 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRAGE-Bench: Automatic Multilingual Benchmark Arena for Retrieval-Augmented Generation Systems
Oct 17, 2024
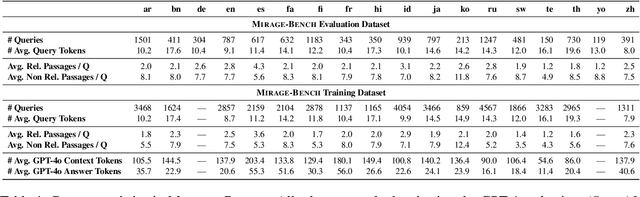
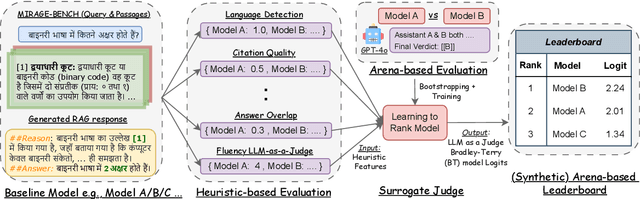
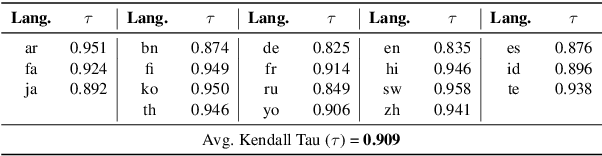
Traditional Retrieval-Augmented Generation (RAG) benchmarks rely on different heuristic-based metrics for evaluation, but these require human preferences as ground truth for reference. In contrast, arena-based benchmarks, where two models compete each other, require an expensive Large Language Model (LLM) as a judge for a reliable evaluation. We present an easy and efficient technique to get the best of both worlds. The idea is to train a learning to rank model as a "surrogate" judge using RAG-based evaluation heuristics as input, to produce a synthetic arena-based leaderboard. Using this idea, We develop MIRAGE-Bench, a standardized arena-based multilingual RAG benchmark for 18 diverse languages on Wikipedia. The benchmark is constructed using MIRACL, a retrieval dataset, and extended for multilingual generation evaluation. MIRAGE-Bench evaluates RAG extensively coupling both heuristic features and LLM as a judge evaluator. In our work, we benchmark 19 diverse multilingual-focused LLMs, and achieve a high correlation (Kendall Tau ($\tau$) = 0.909) using our surrogate judge learned using heuristic features with pairwise evaluations and between GPT-4o as a teacher on the MIRAGE-Bench leaderboard using the Bradley-Terry framework. We observe proprietary and large open-source LLMs currently dominate in multilingual RAG. MIRAGE-Bench is available at: https://github.com/vectara/mirage-bench.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024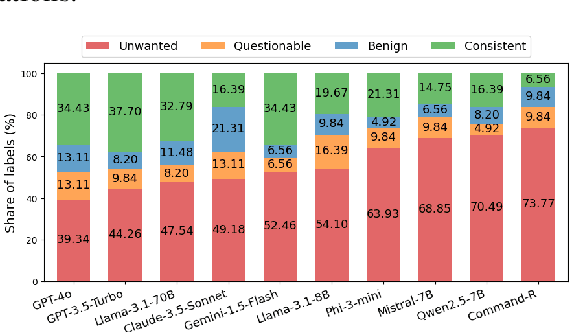
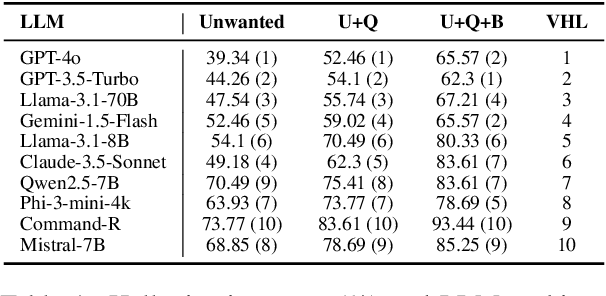
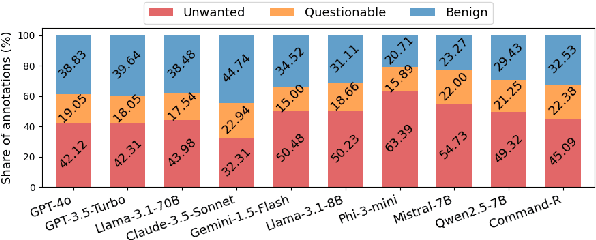
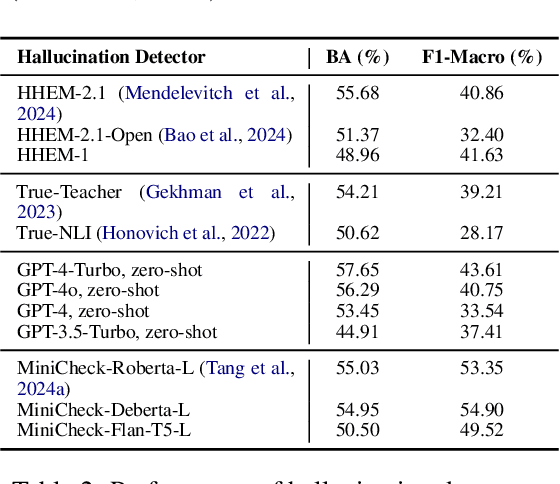
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
Synergistic Approach for Simultaneous Optimization of Monolingual, Cross-lingual, and Multilingual Information Retrieval
Aug 20, 2024Information retrieval across different languages is an increasingly important challenge in natural language processing. Recent approaches based on multilingual pre-trained language models have achieved remarkable success, yet they often optimize for either monolingual, cross-lingual, or multilingual retrieval performance at the expense of others. This paper proposes a novel hybrid batch training strategy to simultaneously improve zero-shot retrieval performance across monolingual, cross-lingual, and multilingual settings while mitigating language bias. The approach fine-tunes multilingual language models using a mix of monolingual and cross-lingual question-answer pair batches sampled based on dataset size. Experiments on XQuAD-R, MLQA-R, and MIRACL benchmark datasets show that the proposed method consistently achieves comparable or superior results in zero-shot retrieval across various languages and retrieval tasks compared to monolingual-only or cross-lingual-only training. Hybrid batch training also substantially reduces language bias in multilingual retrieval compared to monolingual training. These results demonstrate the effectiveness of the proposed approach for learning language-agnostic representations that enable strong zero-shot retrieval performance across diverse languages.
ReQA: An Evaluation for End-to-End Answer Retrieval Models
Jul 10, 2019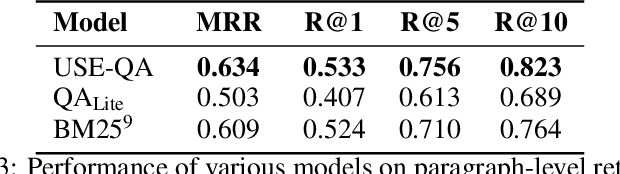
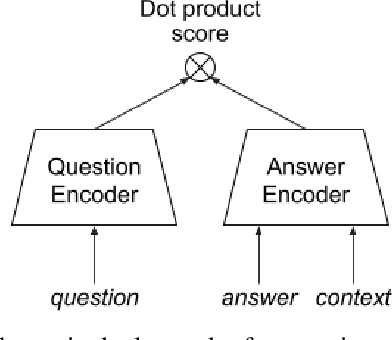
Popular QA benchmarks like SQuAD have driven progress on the task of identifying answer spans within a specific passage, with models now surpassing human performance. However, retrieving relevant answers from a huge corpus of documents is still a challenging problem, and places different requirements on the model architecture. There is growing interest in developing scalable answer retrieval models trained end-to-end, bypassing the typical document retrieval step. In this paper, we introduce Retrieval Question Answering (ReQA), a benchmark for evaluating large-scale sentence- and paragraph-level answer retrieval models. We establish baselines using both neural encoding models as well as classical information retrieval techniques. We release our evaluation code to encourage further work on this challenging task.
Multilingual Universal Sentence Encoder for Semantic Retrieval
Jul 09, 2019We introduce two pre-trained retrieval focused multilingual sentence encoding models, respectively based on the Transformer and CNN model architectures. The models embed text from 16 languages into a single semantic space using a multi-task trained dual-encoder that learns tied representations using translation based bridge tasks (Chidambaram al., 2018). The models provide performance that is competitive with the state-of-the-art on: semantic retrieval (SR), translation pair bitext retrieval (BR) and retrieval question answering (ReQA). On English transfer learning tasks, our sentence-level embeddings approach, and in some cases exceed, the performance of monolingual, English only, sentence embedding models. Our models are made available for download on TensorFlow Hub.