 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Faithfulness in RAG with Evolving Leaderboards
May 07, 2025


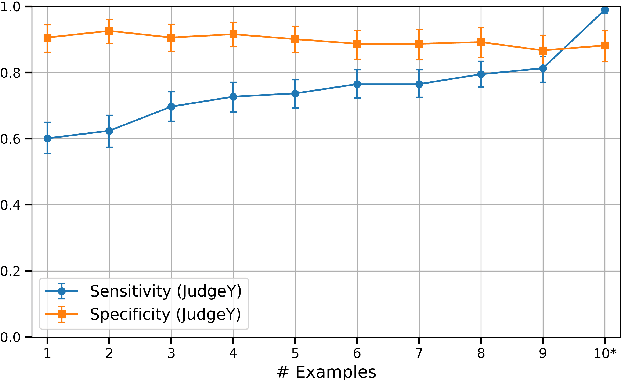
Hallucinations remain a persistent challenge for LLMs. RAG aims to reduce hallucinations by grounding responses in contexts. However, even when provided context, LLMs still frequently introduce unsupported information or contradictions. This paper presents our efforts to measure LLM hallucinations with a focus on summarization tasks, assessing how often various LLMs introduce hallucinations when summarizing documents. We discuss Vectara's existing LLM hallucination leaderboard, based on the Hughes Hallucination Evaluation Model (HHEM). While HHEM and Vectara's Hallucination Leaderboard have garnered great research interest, we examine challenges faced by HHEM and current hallucination detection methods by analyzing the effectiveness of these methods on existing hallucination datasets. To address these limitations, we propose FaithJudge, an LLM-as-a-judge approach guided by few-shot human hallucination annotations, which substantially improves automated LLM hallucination evaluation over current methods. We introduce an enhanced hallucination leaderboard centered on FaithJudge, alongside our current hallucination leaderboard, enabling more reliable benchmarking of LLMs for hallucinations in RAG.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024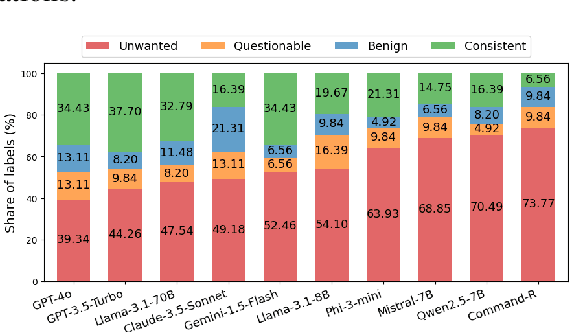
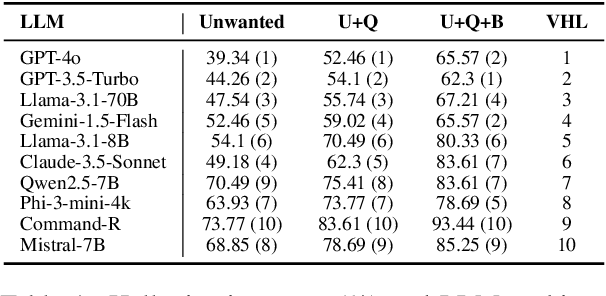
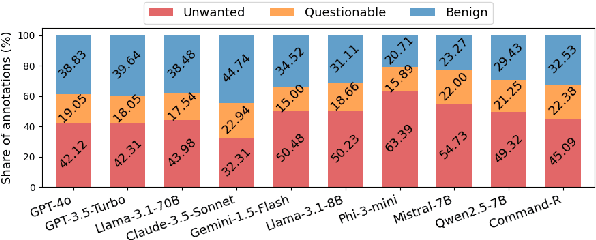
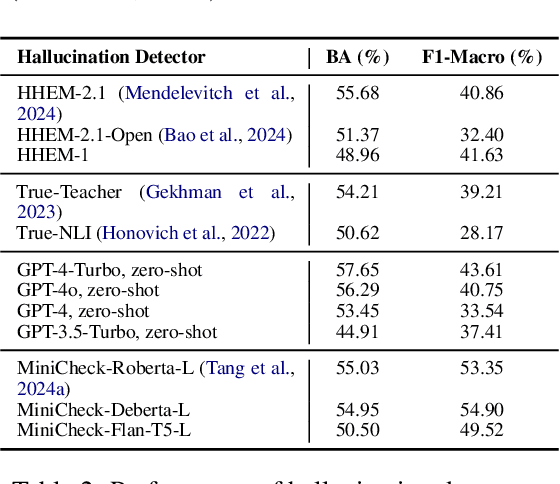
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
DocAsRef: A Pilot Empirical Study on Repurposing Reference-Based Summary Quality Metrics Reference-Freely
Dec 20, 2022Summary quality assessment metrics have two categories: reference-based and reference-free. Reference-based metrics are theoretically more accurate but are limited by the availability and quality of the human-written references, which are both difficulty to ensure. This inspires the development of reference-free metrics, which are independent from human-written references, in the past few years. However, existing reference-free metrics cannot be both zero-shot and accurate. In this paper, we propose a zero-shot but accurate reference-free approach in a sneaky way: feeding documents, based upon which summaries generated, as references into reference-based metrics. Experimental results show that this zero-shot approach can give us the best-performing reference-free metrics on nearly all aspects on several recently-released datasets, even beating reference-free metrics specifically trained for this task sometimes. We further investigate what reference-based metrics can benefit from such repurposing and whether our additional tweaks help.
Circuit Routing Using Monte Carlo Tree Search and Deep Neural Networks
Jun 24, 2020
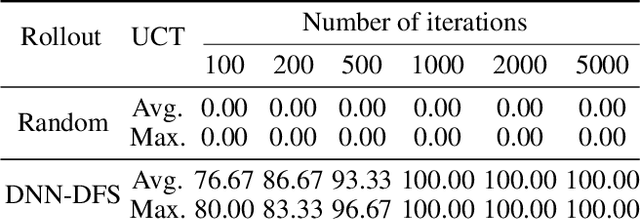
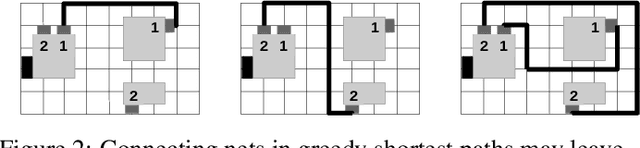
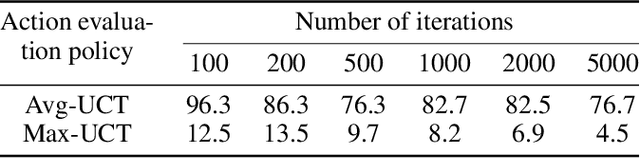
Circuit routing is a fundamental problem in designing electronic systems such as integrated circuits (ICs) and printed circuit boards (PCBs) which form the hardware of electronics and computers. Like finding paths between pairs of locations, circuit routing generates traces of wires to connect contacts or leads of circuit components. It is challenging because finding paths between dense and massive electronic components involves a very large search space. Existing solutions are either manually designed with domain knowledge or tailored to specific design rules, hence, difficult to adapt to new problems or design needs. Therefore, a general routing approach is highly desired. In this paper, we model the circuit routing as a sequential decision-making problem, and solve it by Monte Carlo tree search (MCTS) with deep neural network (DNN) guided rollout. It could be easily extended to routing cases with more routing constraints and optimization goals. Experiments on randomly generated single-layer circuits show the potential to route complex circuits. The proposed approach can solve the problems that benchmark methods such as sequential A* method and Lee's algorithm cannot solve, and can also outperform the vanilla MCTS approach.
Triaging moderate COVID-19 and other viral pneumonias from routine blood tests
May 13, 2020
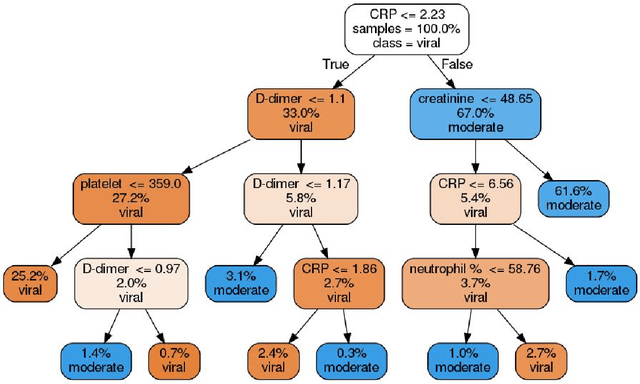
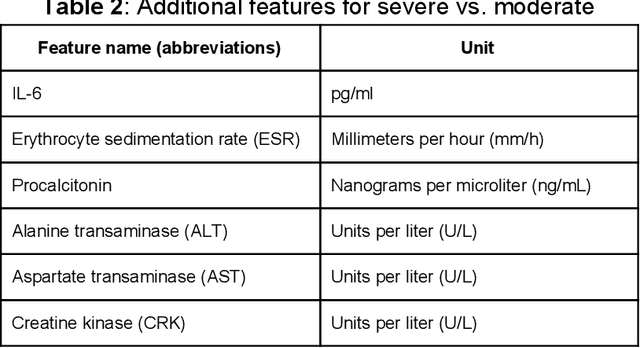
The COVID-19 is sweeping the world with deadly consequences. Its contagious nature and clinical similarity to other pneumonias make separating subjects contracted with COVID-19 and non-COVID-19 viral pneumonia a priority and a challenge. However, COVID-19 testing has been greatly limited by the availability and cost of existing methods, even in developed countries like the US. Intrigued by the wide availability of routine blood tests, we propose to leverage them for COVID-19 testing using the power of machine learning. Two proven-robust machine learning model families, random forests (RFs) and support vector machines (SVMs), are employed to tackle the challenge. Trained on blood data from 208 moderate COVID-19 subjects and 86 subjects with non-COVID-19 moderate viral pneumonia, the best result is obtained in an SVM-based classifier with an accuracy of 84%, a sensitivity of 88%, a specificity of 80%, and a precision of 92%. The results are found explainable from both machine learning and medical perspectives. A privacy-protected web portal is set up to help medical personnel in their practice and the trained models are released for developers to further build other applications. We hope our results can help the world fight this pandemic and welcome clinical verification of our approach on larger populations.
End-to-end Semantics-based Summary Quality Assessment for Single-document Summarization
May 13, 2020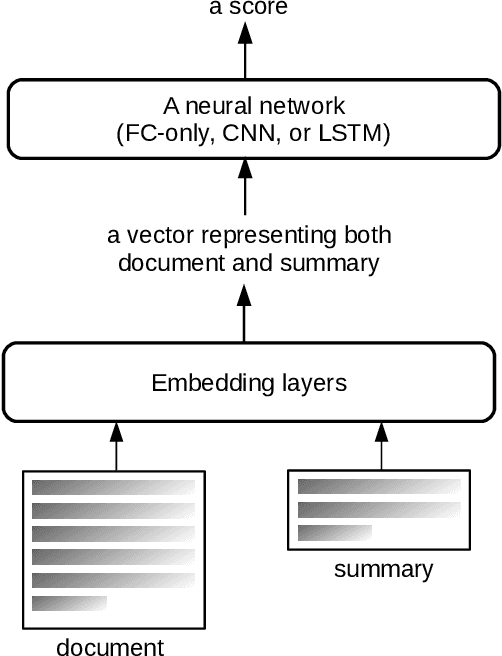
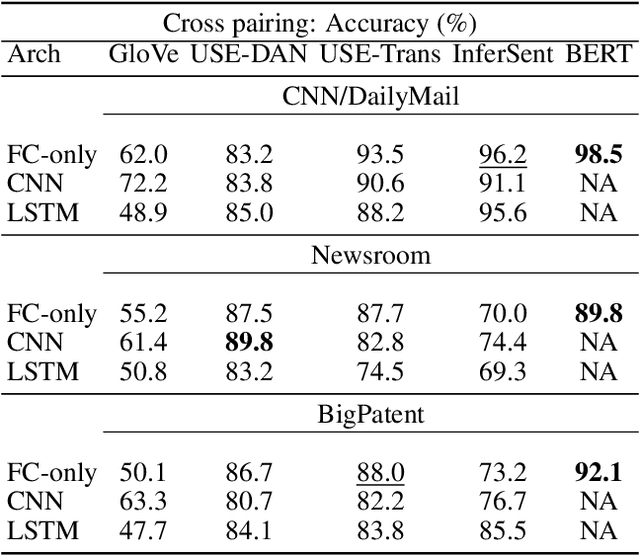

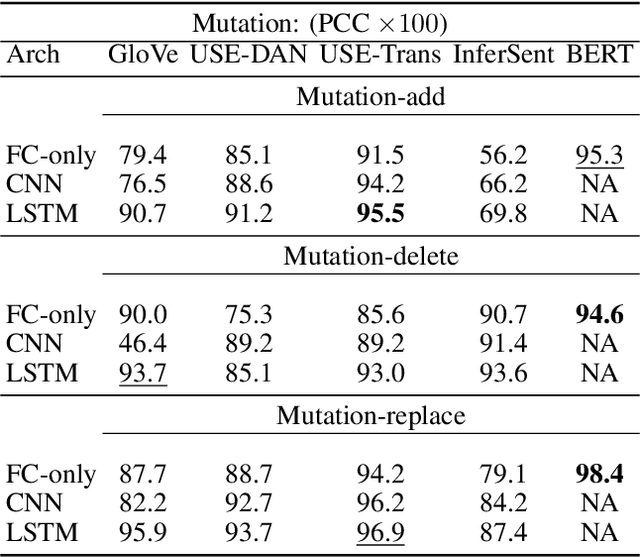
ROUGE is the de facto criterion for summarization research. However, its two major drawbacks limit the research and application of automated summarization systems. First, ROUGE favors lexical similarity instead of semantic similarity, making it especially unfit for abstractive summarization. Second, ROUGE cannot function without a reference summary, which is expensive or impossible to obtain in many cases. Therefore, we introduce a new end-to-end metric system for summary quality assessment by leveraging the semantic similarities of words and/or sentences in deep learning. Models trained in our framework can evaluate a summary directly against the input document, without the need of a reference summary. The proposed approach exhibits very promising results on gold-standard datasets and suggests its great potential to future summarization research. The scores from our models have correlation coefficients up to 0.54 with human evaluations on machine generated summaries in TAC2010. Its performance is also very close to ROUGE metrics'.
RLScheduler: Learn to Schedule HPC Batch Jobs Using Deep Reinforcement Learning
Oct 20, 2019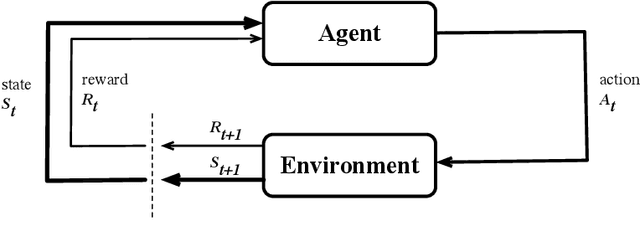
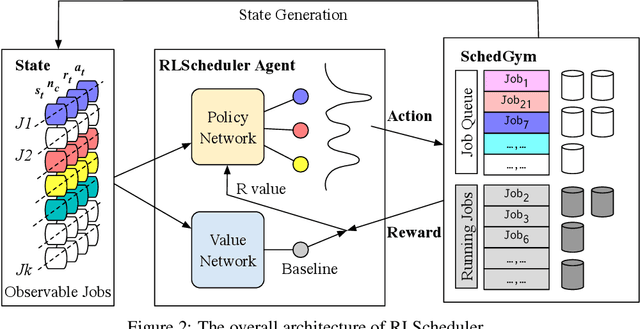

We present RLScheduler, a deep reinforcement learning based job scheduler for scheduling independent batch jobs in high-performance computing (HPC) environment. From knowing nothing about scheduling at beginning, RLScheduler is able to autonomously learn how to effectively schedule HPC batch jobs, targeting a given optimization goal. This is achieved by deep reinforcement learning with the help of specially designed neural network structures and various optimizations to stabilize and accelerate the learning. Our results show that RLScheduler can outperform existing heuristic scheduling algorithms, including a manually fine-tuned machine learning-based scheduler on the same workload. More importantly, we show that RLScheduler does not blindly over-fit the given workload to achieve such optimization, instead, it learns general rules for scheduling batch jobs which can be further applied to different workloads and systems to achieve similarly optimized performance. We also demonstrate that RLScheduler is capable of adjusting itself along with changing goals and workloads, making it an attractive solution for the future autonomous HPC management.
Detecting (Un)Important Content for Single-Document News Summarization
Feb 26, 2017
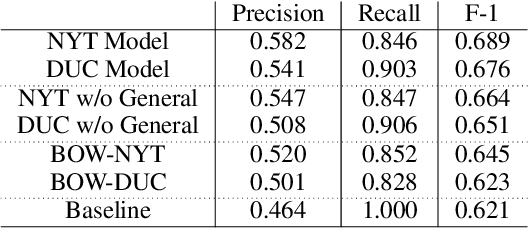
We present a robust approach for detecting intrinsic sentence importance in news, by training on two corpora of document-summary pairs. When used for single-document summarization, our approach, combined with the "beginning of document" heuristic, outperforms a state-of-the-art summarizer and the beginning-of-article baseline in both automatic and manual evaluations. These results represent an important advance because in the absence of cross-document repetition, single document summarizers for news have not been able to consistently outperform the strong beginning-of-article baseline.
General Scaled Support Vector Machines
Sep 27, 2010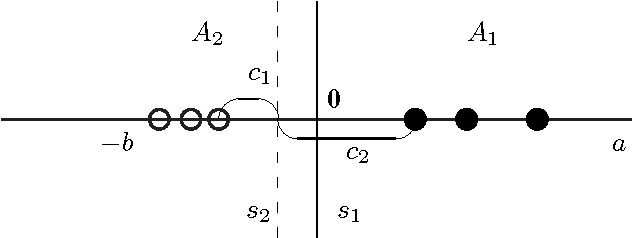
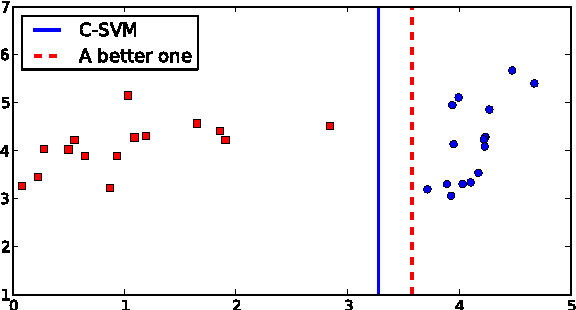
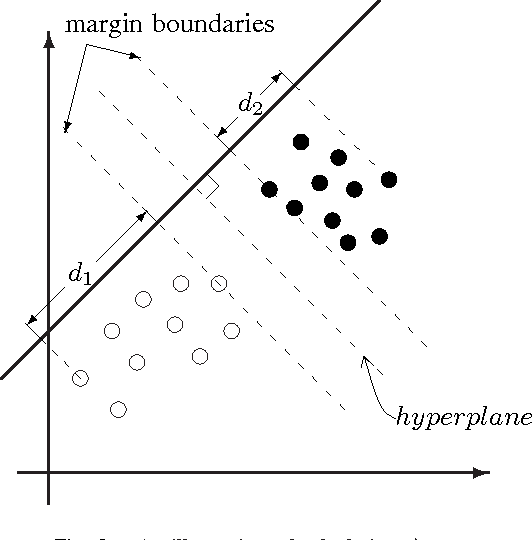
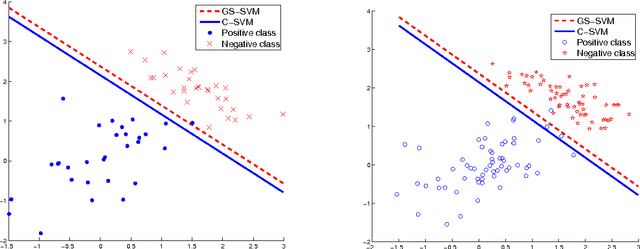
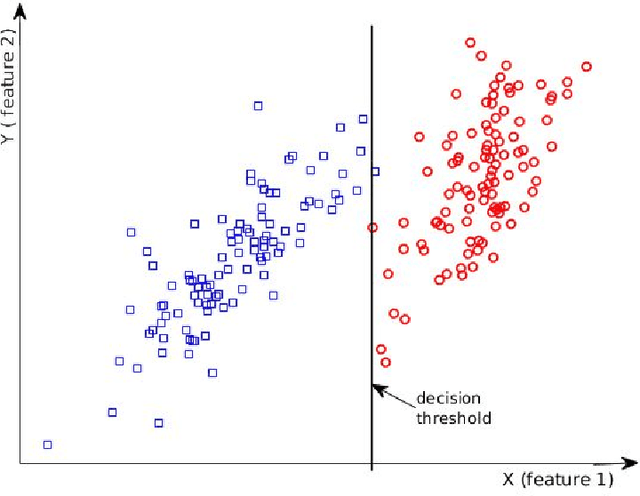
Support Vector Machines (SVMs) are popular tools for data mining tasks such as classification, regression, and density estimation. However, original SVM (C-SVM) only considers local information of data points on or over the margin. Therefore, C-SVM loses robustness. To solve this problem, one approach is to translate (i.e., to move without rotation or change of shape) the hyperplane according to the distribution of the entire data. But existing work can only be applied for 1-D case. In this paper, we propose a simple and efficient method called General Scaled SVM (GS-SVM) to extend the existing approach to multi-dimensional case. Our method translates the hyperplane according to the distribution of data projected on the normal vector of the hyperplane. Compared with C-SVM, GS-SVM has better performance on several data sets.
Automated Epilepsy Diagnosis Using Interictal Scalp EEG
Apr 24, 2009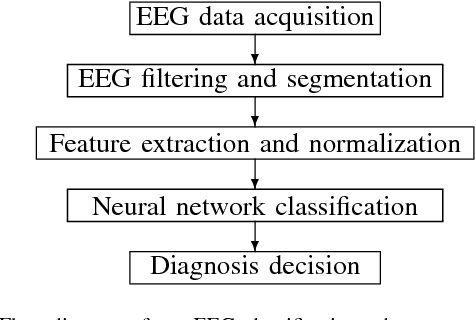
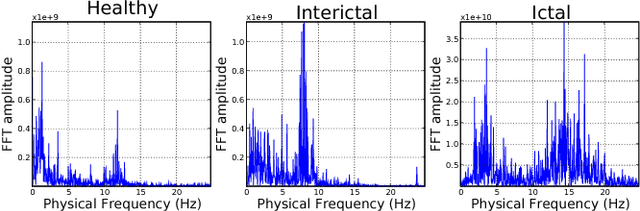
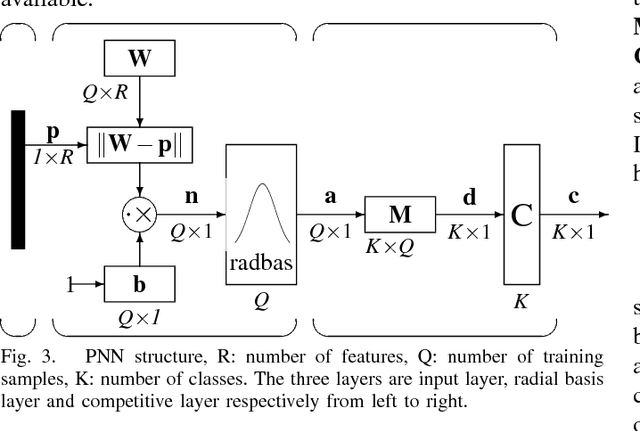
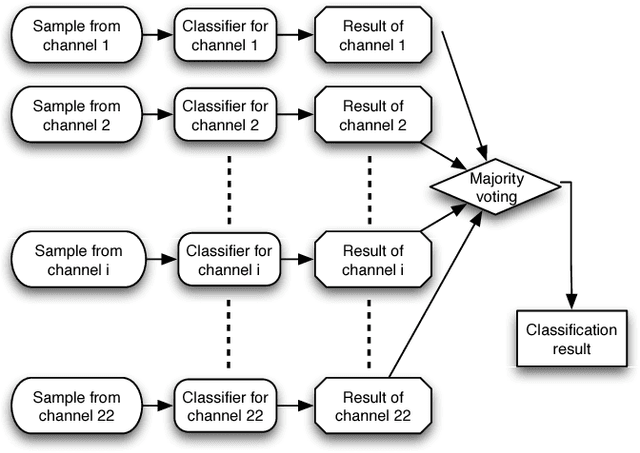
Approximately over 50 million people worldwide suffer from epilepsy. Traditional diagnosis of epilepsy relies on tedious visual screening by highly trained clinicians from lengthy EEG recording that contains the presence of seizure (ictal) activities. Nowadays, there are many automatic systems that can recognize seizure-related EEG signals to help the diagnosis. However, it is very costly and inconvenient to obtain long-term EEG data with seizure activities, especially in areas short of medical resources. We demonstrate in this paper that we can use the interictal scalp EEG data, which is much easier to collect than the ictal data, to automatically diagnose whether a person is epileptic. In our automated EEG recognition system, we extract three classes of features from the EEG data and build Probabilistic Neural Networks (PNNs) fed with these features. We optimize the feature extraction parameters and combine these PNNs through a voting mechanism. As a result, our system achieves an impressive 94.07% accuracy, which is very close to reported human recognition accuracy by experienced medical professionals.