 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriaging moderate COVID-19 and other viral pneumonias from routine blood tests
May 13, 2020
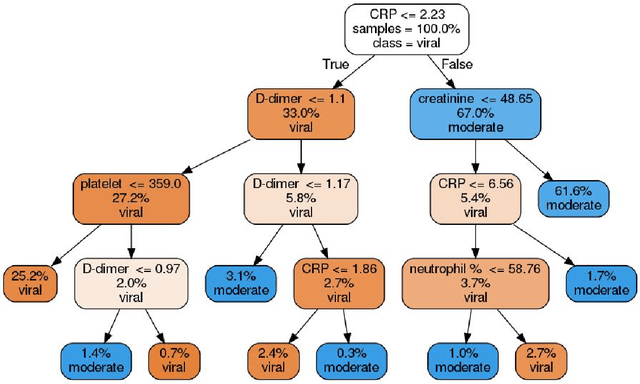
The COVID-19 is sweeping the world with deadly consequences. Its contagious nature and clinical similarity to other pneumonias make separating subjects contracted with COVID-19 and non-COVID-19 viral pneumonia a priority and a challenge. However, COVID-19 testing has been greatly limited by the availability and cost of existing methods, even in developed countries like the US. Intrigued by the wide availability of routine blood tests, we propose to leverage them for COVID-19 testing using the power of machine learning. Two proven-robust machine learning model families, random forests (RFs) and support vector machines (SVMs), are employed to tackle the challenge. Trained on blood data from 208 moderate COVID-19 subjects and 86 subjects with non-COVID-19 moderate viral pneumonia, the best result is obtained in an SVM-based classifier with an accuracy of 84%, a sensitivity of 88%, a specificity of 80%, and a precision of 92%. The results are found explainable from both machine learning and medical perspectives. A privacy-protected web portal is set up to help medical personnel in their practice and the trained models are released for developers to further build other applications. We hope our results can help the world fight this pandemic and welcome clinical verification of our approach on larger populations.
An entropic feature selection method in perspective of Turing formula
Feb 19, 2019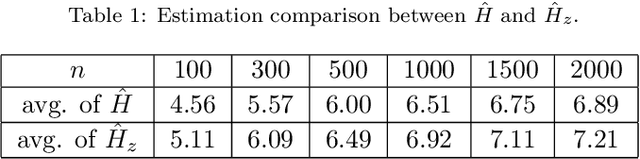
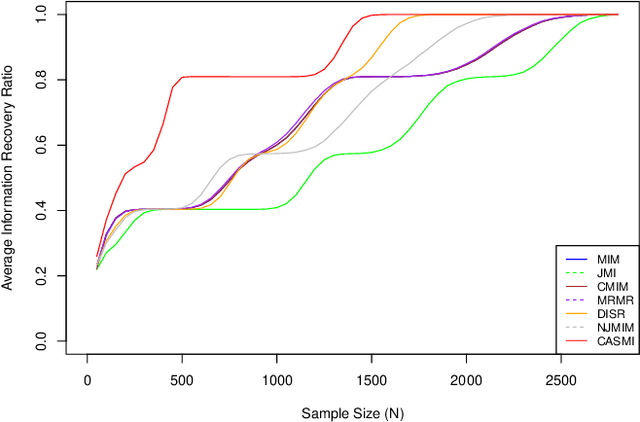

Health data are generally complex in type and small in sample size. Such domain-specific challenges make it difficult to capture information reliably and contribute further to the issue of generalization. To assist the analytics of healthcare datasets, we develop a feature selection method based on the concept of Coverage Adjusted Standardized Mutual Information (CASMI). The main advantages of the proposed method are: 1) it selects features more efficiently with the help of an improved entropy estimator, particularly when the sample size is small, and 2) it automatically learns the number of features to be selected based on the information from sample data. Additionally, the proposed method handles feature redundancy from the perspective of joint-distribution. The proposed method focuses on non-ordinal data, while it works with numerical data with an appropriate binning method. A simulation study comparing the proposed method to six widely cited feature selection methods shows that the proposed method performs better when measured by the Information Recovery Ratio, particularly when the sample size is small.