 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Multiple Extraction Network for Low-Resolution Facial Expression Recognition
Nov 08, 2025Facial expression recognition, as a vital computer vision task, is garnering significant attention and undergoing extensive research. Although facial expression recognition algorithms demonstrate impressive performance on high-resolution images, their effectiveness tends to degrade when confronted with low-resolution images. We find it is because: 1) low-resolution images lack detail information; 2) current methods complete weak global modeling, which make it difficult to extract discriminative features. To alleviate the above issues, we proposed a novel global multiple extraction network (GME-Net) for low-resolution facial expression recognition, which incorporates 1) a hybrid attention-based local feature extraction module with attention similarity knowledge distillation to learn image details from high-resolution network; 2) a multi-scale global feature extraction module with quasi-symmetric structure to mitigate the influence of local image noise and facilitate capturing global image features. As a result, our GME-Net is capable of extracting expression-related discriminative features. Extensive experiments conducted on several widely-used datasets demonstrate that the proposed GME-Net can better recognize low-resolution facial expression and obtain superior performance than existing solutions.
Facial Affect Recognition based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge
Mar 20, 2023In this paper, we present our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes four sub-challenges of Valence-Arousal (VA) Estimation, Expression (Expr) Classification, Action Unit (AU) Detection and Emotional Reaction Intensity (ERI) Estimation. The 5th ABAW competition focuses on facial affect recognition utilizing different modalities and datasets. In our work, we extract powerful audio and visual features using a large number of sota models. These features are fused by Transformer Encoder and TEMMA. Besides, to avoid the possible impact of large dimensional differences between various features, we design an Affine Module to align different features to the same dimension. Extensive experiments demonstrate that the superiority of the proposed method. For the VA Estimation sub-challenge, our method obtains the mean Concordance Correlation Coefficient (CCC) of 0.6066. For the Expression Classification sub-challenge, the average F1 Score is 0.4055. For the AU Detection sub-challenge, the average F1 Score is 0.5296. For the Emotional Reaction Intensity Estimation sub-challenge, the average pearson's correlations coefficient on the validation set is 0.3968. All of the results of four sub-challenges outperform the baseline with a large margin.
An entropic feature selection method in perspective of Turing formula
Feb 19, 2019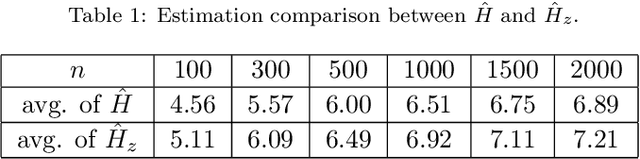
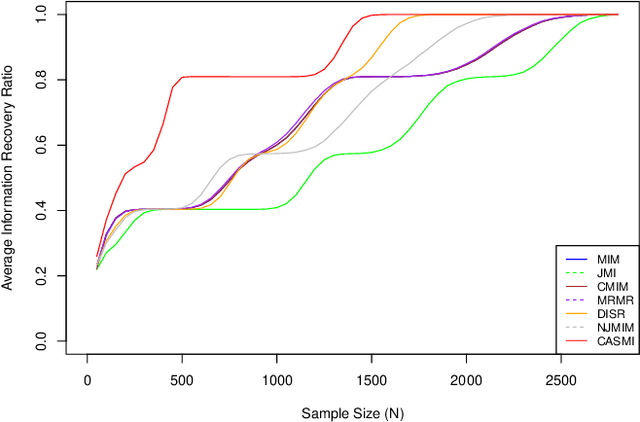
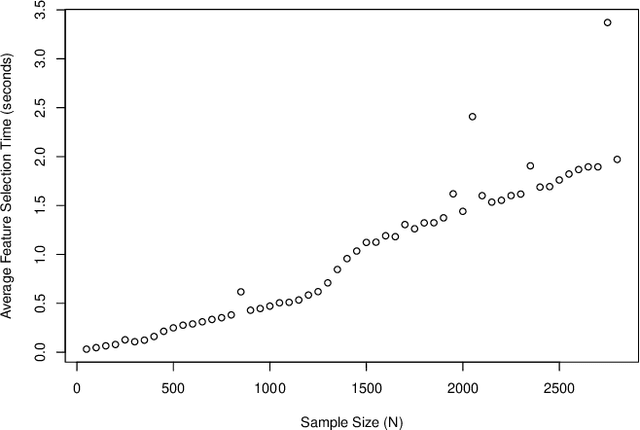

Health data are generally complex in type and small in sample size. Such domain-specific challenges make it difficult to capture information reliably and contribute further to the issue of generalization. To assist the analytics of healthcare datasets, we develop a feature selection method based on the concept of Coverage Adjusted Standardized Mutual Information (CASMI). The main advantages of the proposed method are: 1) it selects features more efficiently with the help of an improved entropy estimator, particularly when the sample size is small, and 2) it automatically learns the number of features to be selected based on the information from sample data. Additionally, the proposed method handles feature redundancy from the perspective of joint-distribution. The proposed method focuses on non-ordinal data, while it works with numerical data with an appropriate binning method. A simulation study comparing the proposed method to six widely cited feature selection methods shows that the proposed method performs better when measured by the Information Recovery Ratio, particularly when the sample size is small.