 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCQ: General-Purpose Deep-Surrogate Framework for Lossy Compression Quality Prediction
Dec 24, 2025Error-bounded lossy compression techniques have become vital for scientific data management and analytics, given the ever-increasing volume of data generated by modern scientific simulations and instruments. Nevertheless, assessing data quality post-compression remains computationally expensive due to the intensive nature of metric calculations. In this work, we present a general-purpose deep-surrogate framework for lossy compression quality prediction (DeepCQ), with the following key contributions: 1) We develop a surrogate model for compression quality prediction that is generalizable to different error-bounded lossy compressors, quality metrics, and input datasets; 2) We adopt a novel two-stage design that decouples the computationally expensive feature-extraction stage from the light-weight metrics prediction, enabling efficient training and modular inference; 3) We optimize the model performance on time-evolving data using a mixture-of-experts design. Such a design enhances the robustness when predicting across simulation timesteps, especially when the training and test data exhibit significant variation. We validate the effectiveness of DeepCQ on four real-world scientific applications. Our results highlight the framework's exceptional predictive accuracy, with prediction errors generally under 10\% across most settings, significantly outperforming existing methods. Our framework empowers scientific users to make informed decisions about data compression based on their preferred data quality, thereby significantly reducing I/O and computational overhead in scientific data analysis.
AI-Assisted Rapid Crystal Structure Generation Towards a Target Local Environment
Jun 09, 2025
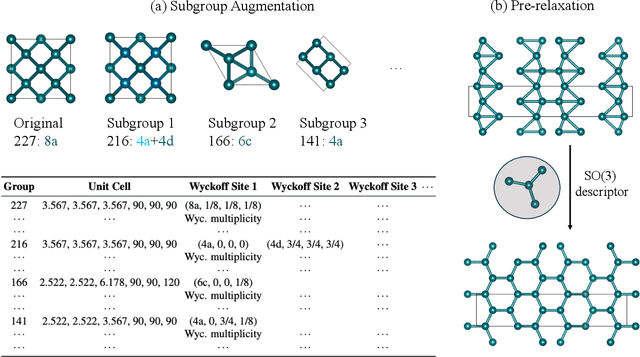

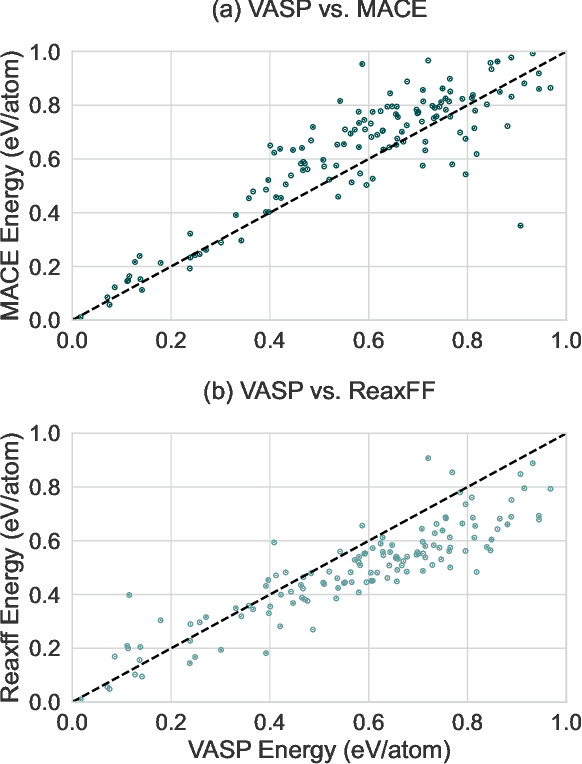
In the field of material design, traditional crystal structure prediction approaches require extensive structural sampling through computationally expensive energy minimization methods using either force fields or quantum mechanical simulations. While emerging artificial intelligence (AI) generative models have shown great promise in generating realistic crystal structures more rapidly, most existing models fail to account for the unique symmetries and periodicity of crystalline materials, and they are limited to handling structures with only a few tens of atoms per unit cell. Here, we present a symmetry-informed AI generative approach called Local Environment Geometry-Oriented Crystal Generator (LEGO-xtal) that overcomes these limitations. Our method generates initial structures using AI models trained on an augmented small dataset, and then optimizes them using machine learning structure descriptors rather than traditional energy-based optimization. We demonstrate the effectiveness of LEGO-xtal by expanding from 25 known low-energy sp2 carbon allotropes to over 1,700, all within 0.5 eV/atom of the ground-state energy of graphite. This framework offers a generalizable strategy for the targeted design of materials with modular building blocks, such as metal-organic frameworks and next-generation battery materials.
Cross-Modal Interactive Perception Network with Mamba for Lung Tumor Segmentation in PET-CT Images
Mar 21, 2025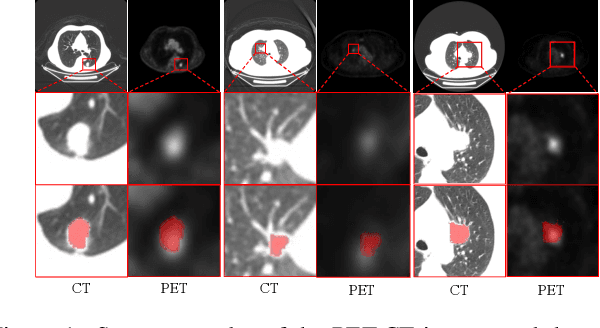
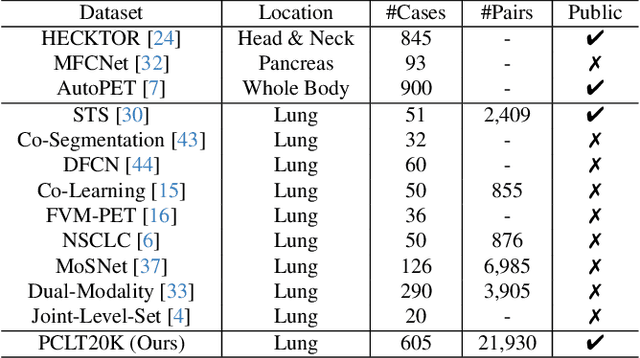
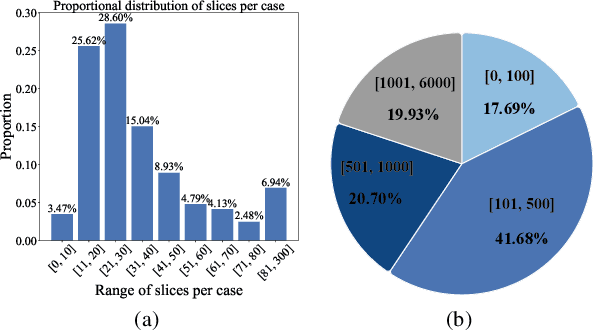
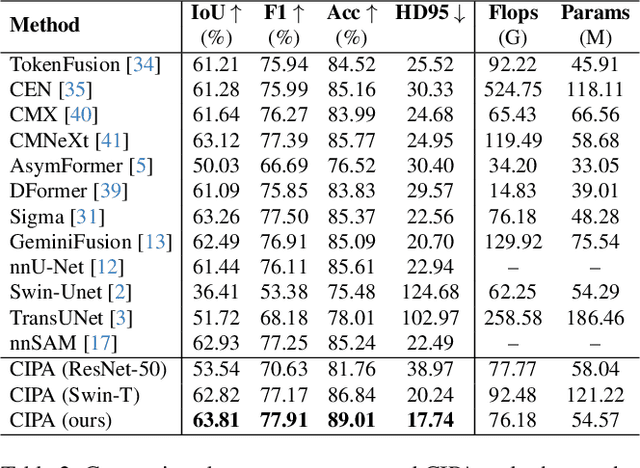
Lung cancer is a leading cause of cancer-related deaths globally. PET-CT is crucial for imaging lung tumors, providing essential metabolic and anatomical information, while it faces challenges such as poor image quality, motion artifacts, and complex tumor morphology. Deep learning-based models are expected to address these problems, however, existing small-scale and private datasets limit significant performance improvements for these methods. Hence, we introduce a large-scale PET-CT lung tumor segmentation dataset, termed PCLT20K, which comprises 21,930 pairs of PET-CT images from 605 patients. Furthermore, we propose a cross-modal interactive perception network with Mamba (CIPA) for lung tumor segmentation in PET-CT images. Specifically, we design a channel-wise rectification module (CRM) that implements a channel state space block across multi-modal features to learn correlated representations and helps filter out modality-specific noise. A dynamic cross-modality interaction module (DCIM) is designed to effectively integrate position and context information, which employs PET images to learn regional position information and serves as a bridge to assist in modeling the relationships between local features of CT images. Extensive experiments on a comprehensive benchmark demonstrate the effectiveness of our CIPA compared to the current state-of-the-art segmentation methods. We hope our research can provide more exploration opportunities for medical image segmentation. The dataset and code are available at https://github.com/mj129/CIPA.
Cross-modal Medical Image Generation Based on Pyramid Convolutional Attention Network
Nov 26, 2024


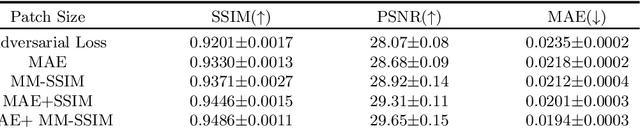
The integration of multimodal medical imaging can provide complementary and comprehensive information for the diagnosis of Alzheimer's disease (AD). However, in clinical practice, since positron emission tomography (PET) is often missing, multimodal images might be incomplete. To address this problem, we propose a method that can efficiently utilize structural magnetic resonance imaging (sMRI) image information to generate high-quality PET images. Our generation model efficiently utilizes pyramid convolution combined with channel attention mechanism to extract multi-scale local features in sMRI, and injects global correlation information into these features using self-attention mechanism to ensure the restoration of the generated PET image on local texture and global structure. Additionally, we introduce additional loss functions to guide the generation model in producing higher-quality PET images. Through experiments conducted on publicly available ADNI databases, the generated images outperform previous research methods in various performance indicators (average absolute error: 0.0194, peak signal-to-noise ratio: 29.65, structural similarity: 0.9486) and are close to real images. In promoting AD diagnosis, the generated images combined with their corresponding sMRI also showed excellent performance in AD diagnosis tasks (classification accuracy: 94.21 %), and outperformed previous research methods of the same type. The experimental results demonstrate that our method outperforms other competing methods in quantitative metrics, qualitative visualization, and evaluation criteria.
ClusterLog: Clustering Logs for Effective Log-based Anomaly Detection
Jan 19, 2023With the increasing prevalence of scalable file systems in the context of High Performance Computing (HPC), the importance of accurate anomaly detection on runtime logs is increasing. But as it currently stands, many state-of-the-art methods for log-based anomaly detection, such as DeepLog, have encountered numerous challenges when applied to logs from many parallel file systems (PFSes), often due to their irregularity and ambiguity in time-based log sequences. To circumvent these problems, this study proposes ClusterLog, a log pre-processing method that clusters the temporal sequence of log keys based on their semantic similarity. By grouping semantically and sentimentally similar logs, this approach aims to represent log sequences with the smallest amount of unique log keys, intending to improve the ability of a downstream sequence-based model to effectively learn the log patterns. The preliminary results of ClusterLog indicate not only its effectiveness in reducing the granularity of log sequences without the loss of important sequence information but also its generalizability to different file systems' logs.
RLScheduler: Learn to Schedule HPC Batch Jobs Using Deep Reinforcement Learning
Oct 20, 2019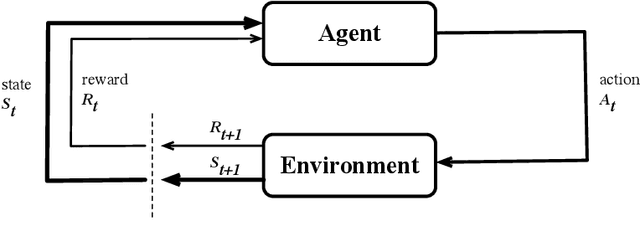
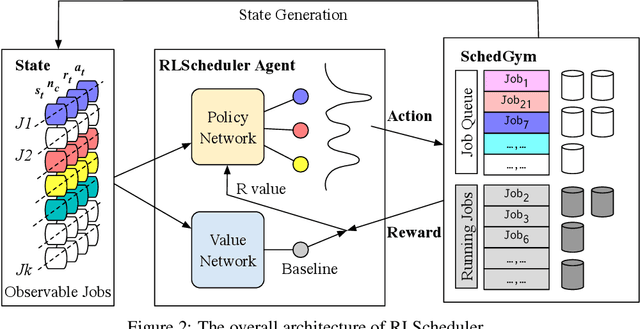

We present RLScheduler, a deep reinforcement learning based job scheduler for scheduling independent batch jobs in high-performance computing (HPC) environment. From knowing nothing about scheduling at beginning, RLScheduler is able to autonomously learn how to effectively schedule HPC batch jobs, targeting a given optimization goal. This is achieved by deep reinforcement learning with the help of specially designed neural network structures and various optimizations to stabilize and accelerate the learning. Our results show that RLScheduler can outperform existing heuristic scheduling algorithms, including a manually fine-tuned machine learning-based scheduler on the same workload. More importantly, we show that RLScheduler does not blindly over-fit the given workload to achieve such optimization, instead, it learns general rules for scheduling batch jobs which can be further applied to different workloads and systems to achieve similarly optimized performance. We also demonstrate that RLScheduler is capable of adjusting itself along with changing goals and workloads, making it an attractive solution for the future autonomous HPC management.
Rare Disease Physician Targeting: A Factor Graph Approach
Jan 19, 2017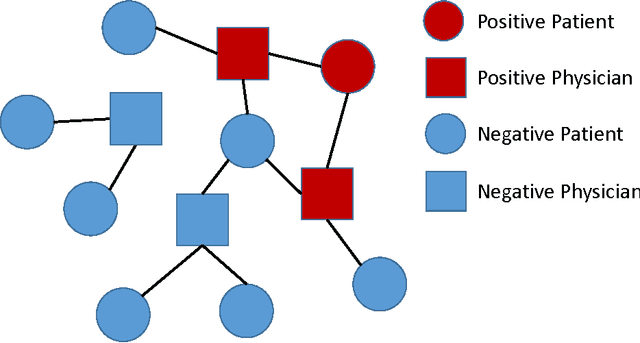

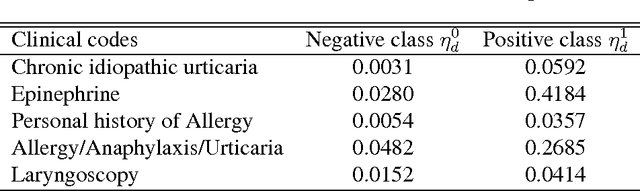
In rare disease physician targeting, a major challenge is how to identify physicians who are treating diagnosed or underdiagnosed rare diseases patients. Rare diseases have extremely low incidence rate. For a specified rare disease, only a small number of patients are affected and a fractional of physicians are involved. The existing targeting methodologies, such as segmentation and profiling, are developed under mass market assumption. They are not suitable for rare disease market where the target classes are extremely imbalanced. The authors propose a graphical model approach to predict targets by jointly modeling physician and patient features from different data spaces and utilizing the extra relational information. Through an empirical example with medical claim and prescription data, the proposed approach demonstrates better accuracy in finding target physicians. The graph representation also provides visual interpretability of relationship among physicians and patients. The model can be extended to incorporate more complex dependency structures. This article contributes to the literature of exploring the benefit of utilizing relational dependencies among entities in healthcare industry.
Aggregation of Affine Estimators
Nov 12, 2013
We consider the problem of aggregating a general collection of affine estimators for fixed design regression. Relevant examples include some commonly used statistical estimators such as least squares, ridge and robust least squares estimators. Dalalyan and Salmon (2012) have established that, for this problem, exponentially weighted (EW) model selection aggregation leads to sharp oracle inequalities in expectation, but similar bounds in deviation were not previously known. While results indicate that the same aggregation scheme may not satisfy sharp oracle inequalities with high probability, we prove that a weaker notion of oracle inequality for EW that holds with high probability. Moreover, using a generalization of the newly introduced $Q$-aggregation scheme we also prove sharp oracle inequalities that hold with high probability. Finally, we apply our results to universal aggregation and show that our proposed estimator leads simultaneously to all the best known bounds for aggregation, including $\ell_q$-aggregation, $q \in (0,1)$, with high probability.
Deviation optimal learning using greedy Q-aggregation
Dec 12, 2012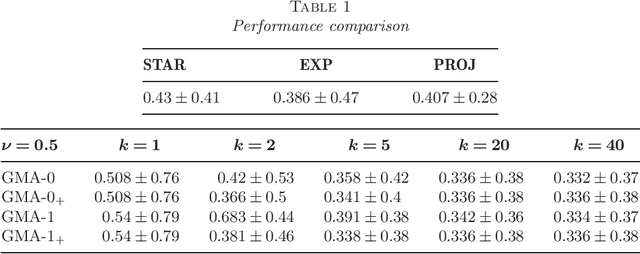
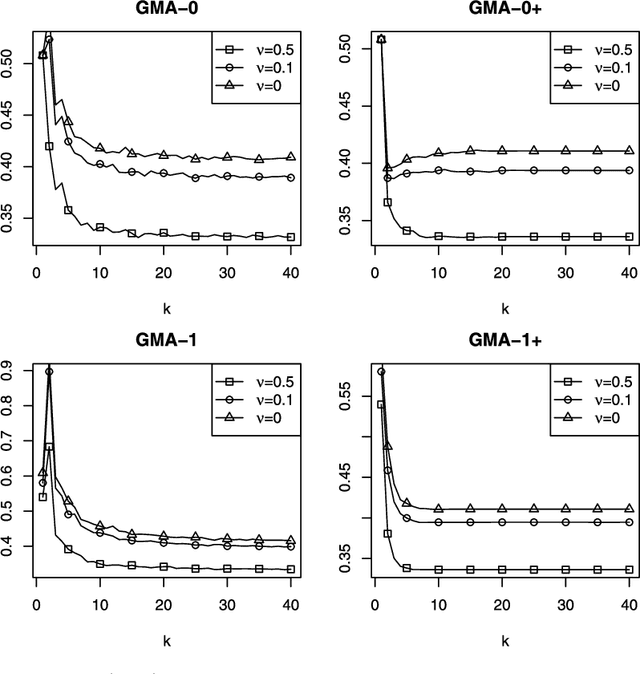
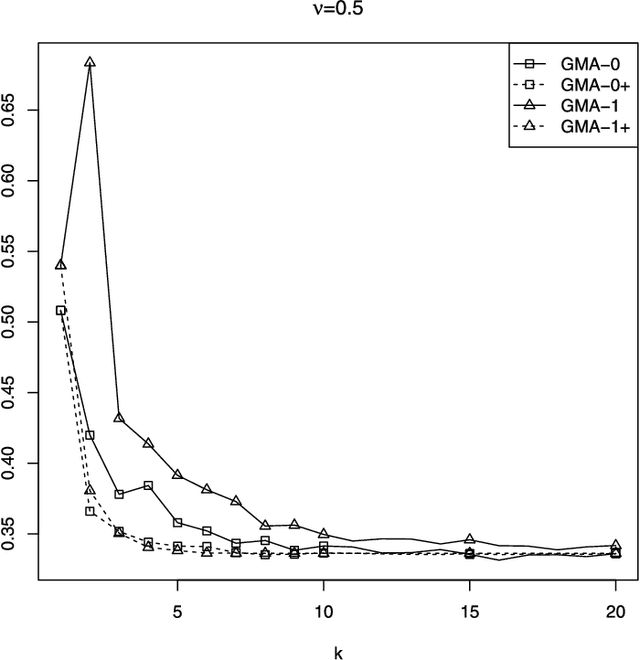
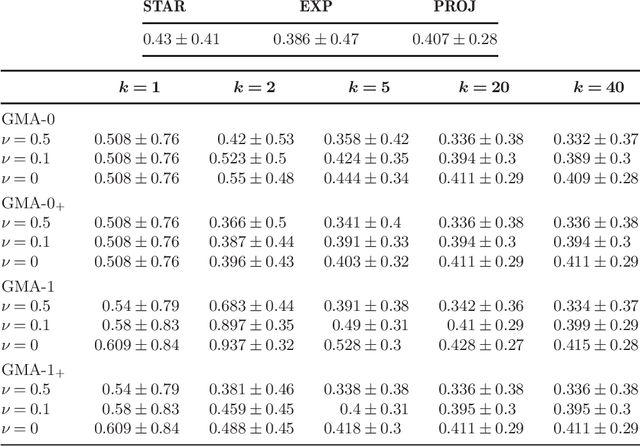
Given a finite family of functions, the goal of model selection aggregation is to construct a procedure that mimics the function from this family that is the closest to an unknown regression function. More precisely, we consider a general regression model with fixed design and measure the distance between functions by the mean squared error at the design points. While procedures based on exponential weights are known to solve the problem of model selection aggregation in expectation, they are, surprisingly, sub-optimal in deviation. We propose a new formulation called Q-aggregation that addresses this limitation; namely, its solution leads to sharp oracle inequalities that are optimal in a minimax sense. Moreover, based on the new formulation, we design greedy Q-aggregation procedures that produce sparse aggregation models achieving the optimal rate. The convergence and performance of these greedy procedures are illustrated and compared with other standard methods on simulated examples.
* Published in at http://dx.doi.org/10.1214/12-AOS1025 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)