 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInsight: A Unified Evaluation Infrastructure Across the Physical AI Stack
Jun 16, 2026Evaluating a Physical AI stack spans operators that differ by more than three orders of magnitude -- from a single foundation-model decoding step to thousands of physics ticks of whole-body control -- varying orthogonally in modality, reward semantics, and resource profile. No existing framework spans this range, so the stack is evaluated today by stitching together separate harnesses that share neither runtime nor scoring, preserving each segment's local validity but losing the shared identity needed to diagnose cross-layer regressions. We present DeepInsight, an evaluation infrastructure that serves this full spectrum on a single runtime. Rather than homogenize the regimes, it preserves their heterogeneity behind three narrow abstractions -- task, resource, and result -- each realized as one invariant shared by every subsystem: one episode driver, one resource-handle protocol implemented by every expensive backend (LLM inference and sandboxed runtimes alike), and one trace identity scheme under which every event is written. Deployed in production across all three layers of an embodied humanoid stack, this single set of invariants onboards new benchmarks largely by configuration. Where mature peer orchestrators exist -- at the foundation-model end -- it reproduces published references and peer-framework readings within their own spread, runs the same suites faster on a single node, and scales near-linearly across nodes. Its distinctive return is diagnostic: because every layer writes into one shared trace, a regression that begins in one layer and surfaces in another stays localizable on that trace -- a cross-layer payoff no federation of per-segment harnesses can reproduce.
Beyond path selection: Better LLMs for Scientific Information Extraction with MimicSFT and Relevance and Rule-induced(R$^2$)GRPO
May 28, 2025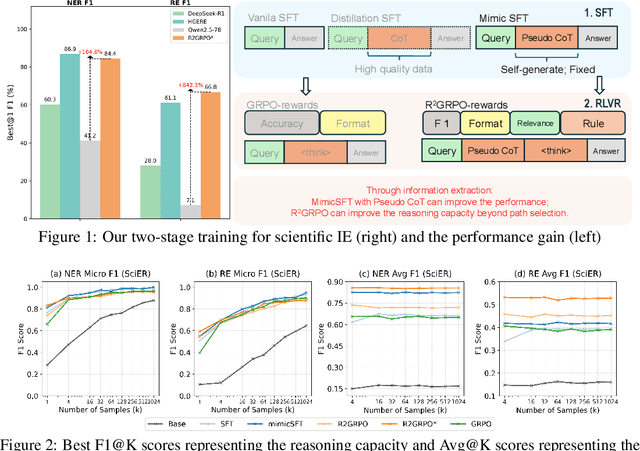
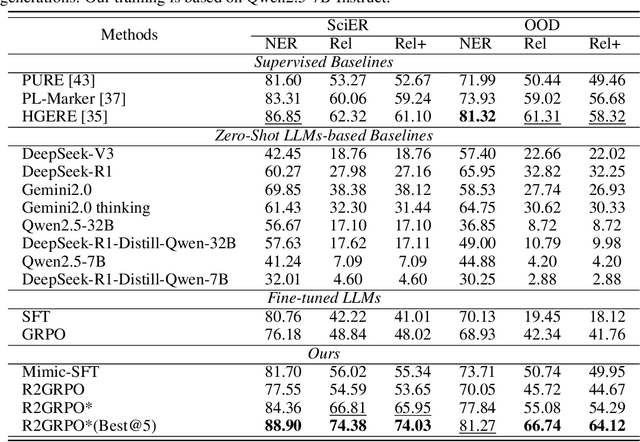
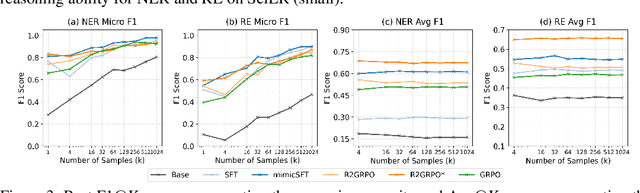
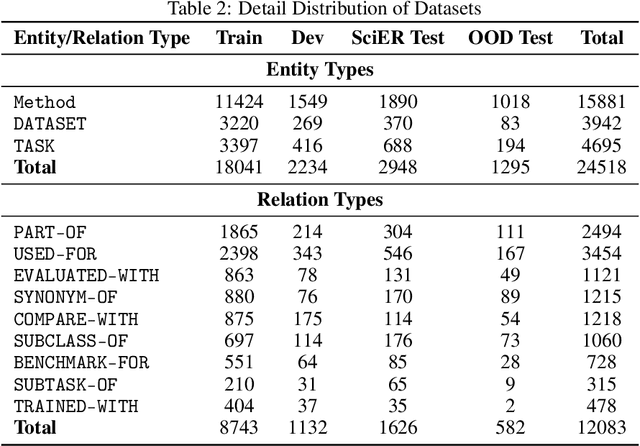
Previous study suggest that powerful Large Language Models (LLMs) trained with Reinforcement Learning with Verifiable Rewards (RLVR) only refines reasoning path without improving the reasoning capacity in math tasks while supervised-finetuning(SFT) with distillation can. We study this from the view of Scientific information extraction (SciIE) where LLMs and reasoning LLMs underperforms small Bert-based models. SciIE require both the reasoning and memorization. We argue that both SFT and RLVR can refine the reasoning path and improve reasoning capacity in a simple way based on SciIE. We propose two-stage training with 1. MimicSFT, using structured reasoning templates without needing high-quality chain-of-thought data, 2. R$^2$GRPO with relevance and rule-induced rewards. Experiments on scientific IE benchmarks show that both methods can improve the reasoning capacity. R$^2$GRPO with mimicSFT surpasses baseline LLMs and specialized supervised models in relation extraction. Our code is available at https://github.com/ranlislz/R2GRPO.
Cross-Modal Interactive Perception Network with Mamba for Lung Tumor Segmentation in PET-CT Images
Mar 21, 2025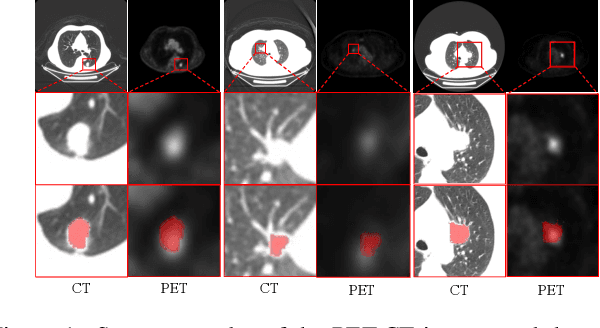
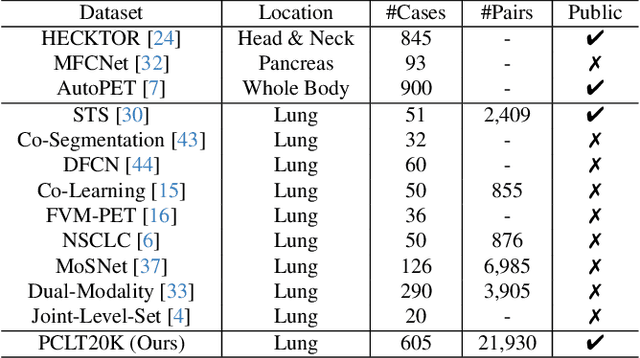
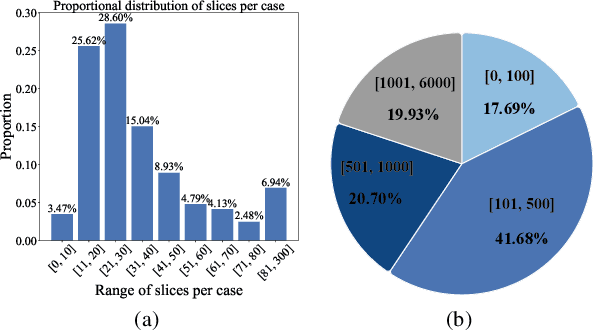
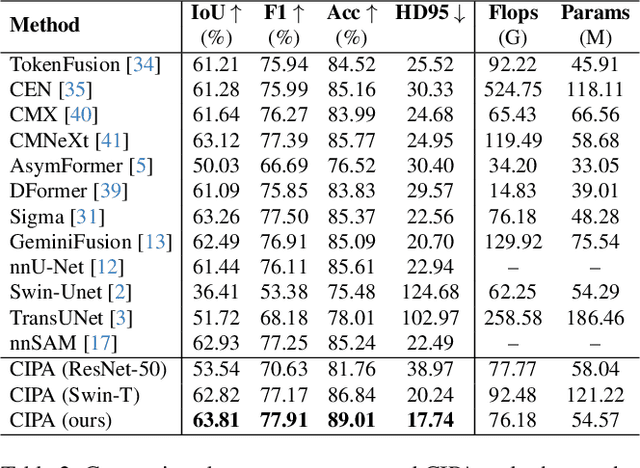
Lung cancer is a leading cause of cancer-related deaths globally. PET-CT is crucial for imaging lung tumors, providing essential metabolic and anatomical information, while it faces challenges such as poor image quality, motion artifacts, and complex tumor morphology. Deep learning-based models are expected to address these problems, however, existing small-scale and private datasets limit significant performance improvements for these methods. Hence, we introduce a large-scale PET-CT lung tumor segmentation dataset, termed PCLT20K, which comprises 21,930 pairs of PET-CT images from 605 patients. Furthermore, we propose a cross-modal interactive perception network with Mamba (CIPA) for lung tumor segmentation in PET-CT images. Specifically, we design a channel-wise rectification module (CRM) that implements a channel state space block across multi-modal features to learn correlated representations and helps filter out modality-specific noise. A dynamic cross-modality interaction module (DCIM) is designed to effectively integrate position and context information, which employs PET images to learn regional position information and serves as a bridge to assist in modeling the relationships between local features of CT images. Extensive experiments on a comprehensive benchmark demonstrate the effectiveness of our CIPA compared to the current state-of-the-art segmentation methods. We hope our research can provide more exploration opportunities for medical image segmentation. The dataset and code are available at https://github.com/mj129/CIPA.
UMC: Unified Resilient Controller for Legged Robots with Joint Malfunctions
Feb 05, 2025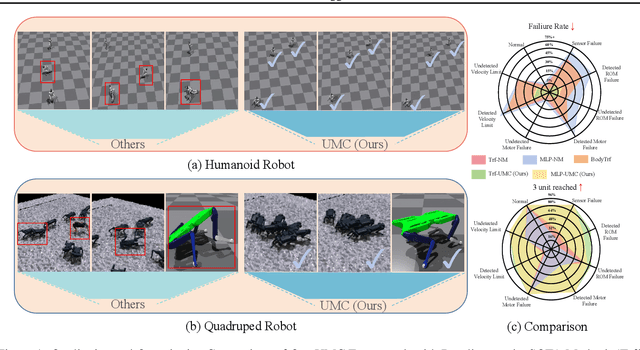
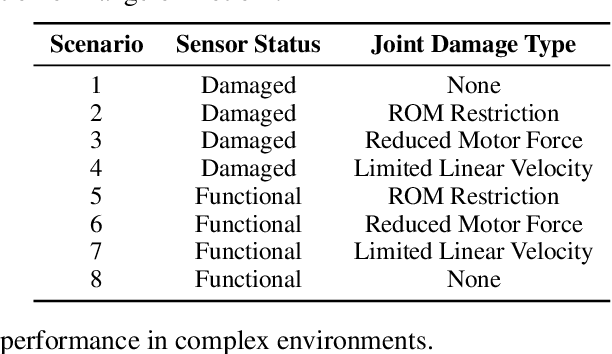
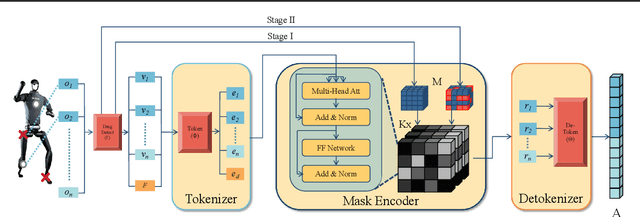
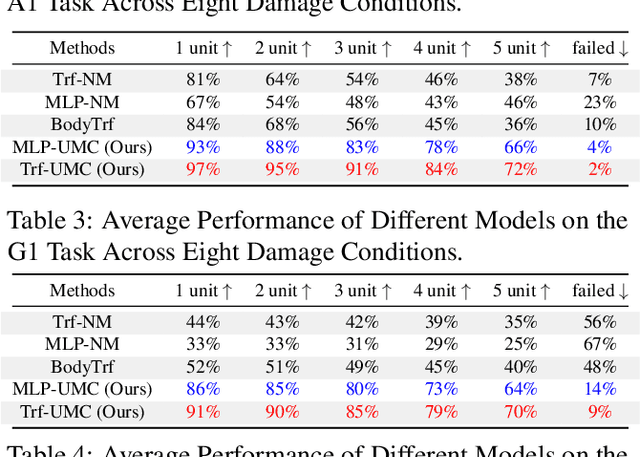
Adaptation to unpredictable damages is crucial for autonomous legged robots, yet existing methods based on multi-policy or meta-learning frameworks face challenges like limited generalization and complex maintenance. To address this issue, we first analyze and summarize eight types of damage scenarios, including sensor failures and joint malfunctions. Then, we propose a novel, model-free, two-stage training framework, Unified Malfunction Controller (UMC), incorporating a masking mechanism to enhance damage resilience. Specifically, the model is initially trained with normal environments to ensure robust performance under standard conditions. In the second stage, we use masks to prevent the legged robot from relying on malfunctioning limbs, enabling adaptive gait and movement adjustments upon malfunction. Experimental results demonstrate that our approach improves the task completion capability by an average of 36% for the transformer and 39% for the MLP across three locomotion tasks. The source code and trained models will be made available to the public.
Boosting Salient Object Detection with Transformer-based Asymmetric Bilateral U-Net
Aug 30, 2021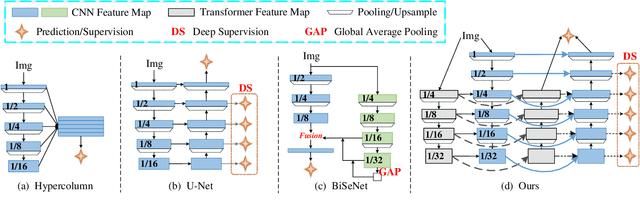
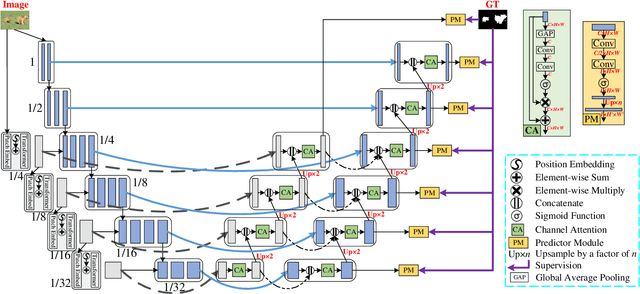
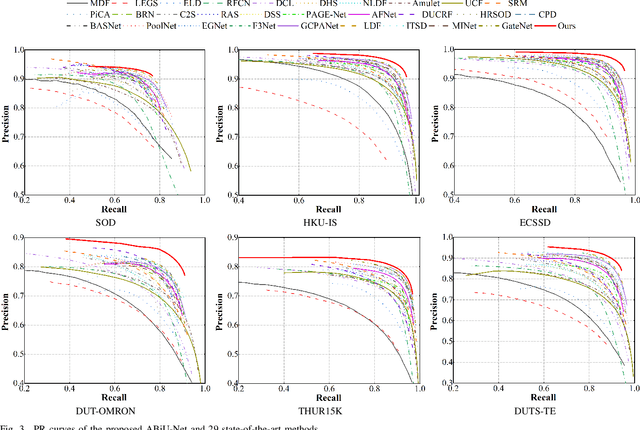

Existing salient object detection (SOD) methods mainly rely on CNN-based U-shaped structures with skip connections to combine the global contexts and local spatial details that are crucial for locating salient objects and refining object details, respectively. Despite great successes, the ability of CNN in learning global contexts is limited. Recently, the vision transformer has achieved revolutionary progress in computer vision owing to its powerful modeling of global dependencies. However, directly applying the transformer to SOD is suboptimal because the transformer lacks the ability to learn local spatial representations. To this end, this paper explores the combination of transformer and CNN to learn both global and local representations for SOD. We propose a transformer-based Asymmetric Bilateral U-Net (ABiU-Net). The asymmetric bilateral encoder has a transformer path and a lightweight CNN path, where the two paths communicate at each encoder stage to learn complementary global contexts and local spatial details, respectively. The asymmetric bilateral decoder also consists of two paths to process features from the transformer and CNN encoder paths, with communication at each decoder stage for decoding coarse salient object locations and find-grained object details, respectively. Such communication between the two encoder/decoder paths enables AbiU-Net to learn complementary global and local representations, taking advantage of the natural properties of transformer and CNN, respectively. Hence, ABiU-Net provides a new perspective for transformer-based SOD. Extensive experiments demonstrate that ABiU-Net performs favorably against previous state-of-the-art SOD methods. The code will be released.
Primary-Auxiliary Model Scheduling Based Estimation of the Vertical Wheel Force in a Full Vehicle System
Jul 24, 2021



In this work, we study estimation problems in nonlinear mechanical systems subject to non-stationary and unknown excitation, which are common and critical problems in design and health management of mechanical systems. A primary-auxiliary model scheduling procedure based on time-domain transmissibilities is proposed and performed under switching linear dynamics: In addition to constructing a primary transmissibility family from the pseudo-inputs to the output during the offline stage, an auxiliary transmissibility family is constructed by further decomposing the pseudo-input vector into two parts. The auxiliary family enables to determine the unknown working condition at which the system is currently running at, and then an appropriate transmissibility from the primary transmissibility family for estimating the unknown output can be selected during the online estimation stage. As a result, the proposed approach offers a generalizable and explainable solution to the signal estimation problems in nonlinear mechanical systems in the context of switching linear dynamics with unknown inputs. A real-world application to the estimation of the vertical wheel force in a full vehicle system are, respectively, conducted to demonstrate the effectiveness of the proposed method. During the vehicle design phase, the vertical wheel force is the most important one among Wheel Center Loads (WCLs), and it is often measured directly with expensive, intrusive, and hard-to-install measurement devices during full vehicle testing campaigns. Meanwhile, the estimation problem of the vertical wheel force has not been solved well and is still of great interest. The experimental results show good performances of the proposed method in the sense of estimation accuracy for estimating the vertical wheel force.
Transformer in Convolutional Neural Networks
Jun 09, 2021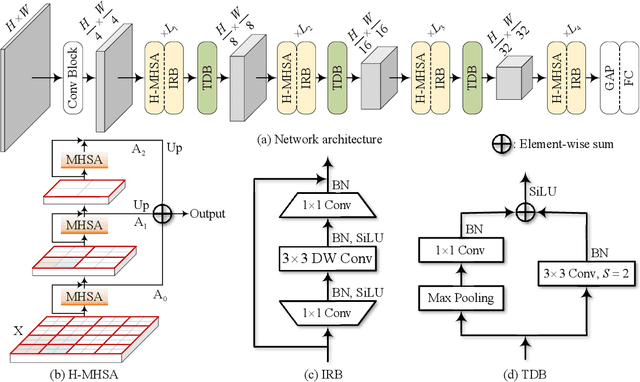
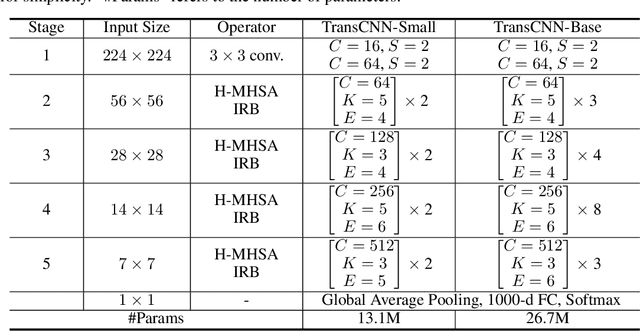

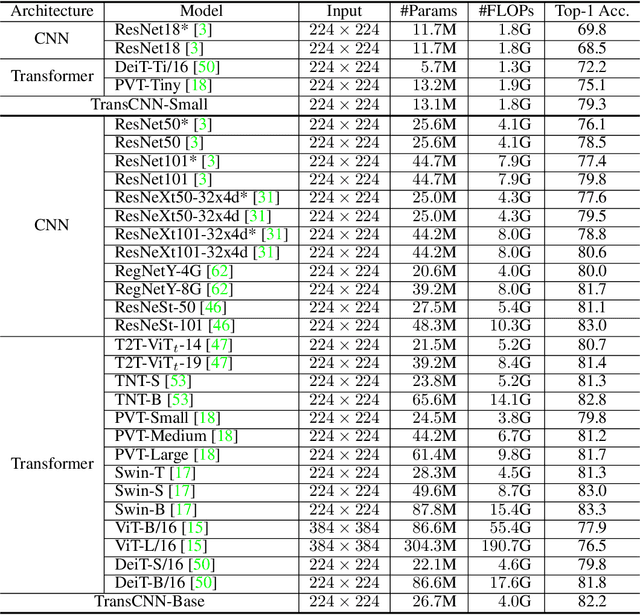
We tackle the low-efficiency flaw of vision transformer caused by the high computational/space complexity in Multi-Head Self-Attention (MHSA). To this end, we propose the Hierarchical MHSA (H-MHSA), whose representation is computed in a hierarchical manner. Specifically, our H-MHSA first learns feature relationships within small grids by viewing image patches as tokens. Then, small grids are merged into larger ones, within which feature relationship is learned by viewing each small grid at the preceding step as a token. This process is iterated to gradually reduce the number of tokens. The H-MHSA module is readily pluggable into any CNN architectures and amenable to training via backpropagation. We call this new backbone TransCNN, and it essentially inherits the advantages of both transformer and CNN. Experiments demonstrate that TransCNN achieves state-of-the-art accuracy for image recognition. Code and pretrained models are available at https://github.com/yun-liu/TransCNN. This technical report will keep updating by adding more experiments.
MiniSeg: An Extremely Minimum Network for Efficient COVID-19 Segmentation
Apr 21, 2020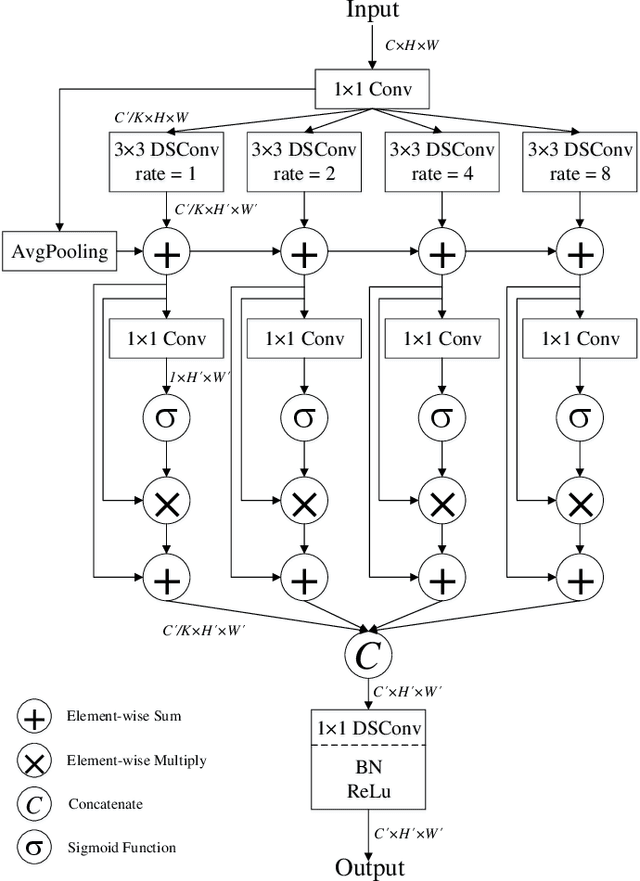
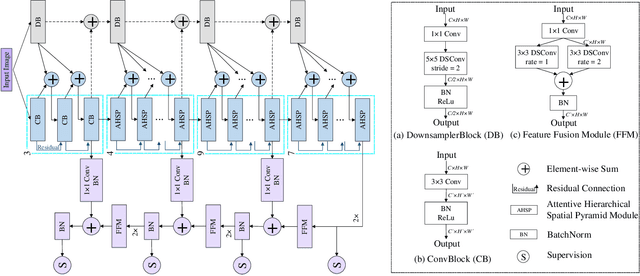
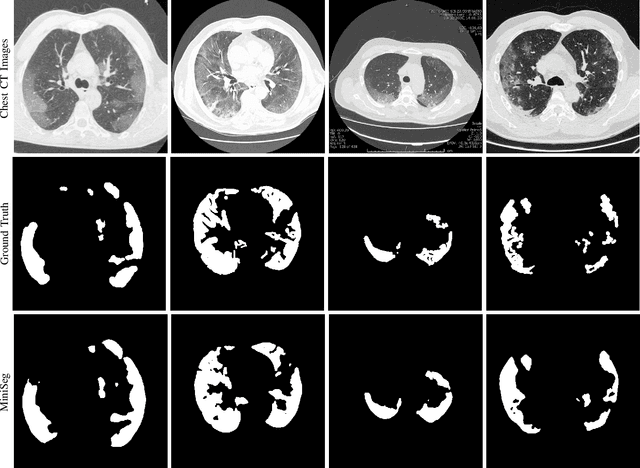

The rapid spread of the new pandemic, coronavirus disease 2019 (COVID-19), has seriously threatened global health. The gold standard for COVID-19 diagnosis is the tried-and-true polymerase chain reaction (PCR), but PCR is a laborious, time-consuming and complicated manual process that is in short supply. Deep learning based computer-aided screening, e.g., infection segmentation, is thus viewed as an alternative due to its great successes in medical imaging. However, the publicly available COVID-19 training data are limited, which would easily cause overfitting of traditional deep learning methods that are usually data-hungry with millions of parameters. On the other hand, fast training/testing and low computational cost are also important for quick deployment and development of computer-aided COVID-19 screening systems, but traditional deep learning methods, especially for image segmentation, are usually computationally intensive. To address the above problems, we propose MiniSeg, a lightweight deep learning model for efficient COVID-19 segmentation. Compared with traditional segmentation methods, MiniSeg has several significant strengths: i) it only has 472K parameters and is thus not easy to overfit; ii) it has high computational efficiency and is thus convenient for practical deployment; iii) it can be fast retrained by other users using their private COVID-19 data for further improving performance. In addition, we build a comprehensive COVID-19 segmentation benchmark for comparing MiniSeg with traditional methods. Code and models will be released to promote the research and practical deployment for computer-aided COVID-19 screening.
Salient Object Detection via High-to-Low Hierarchical Context Aggregation
Dec 28, 2018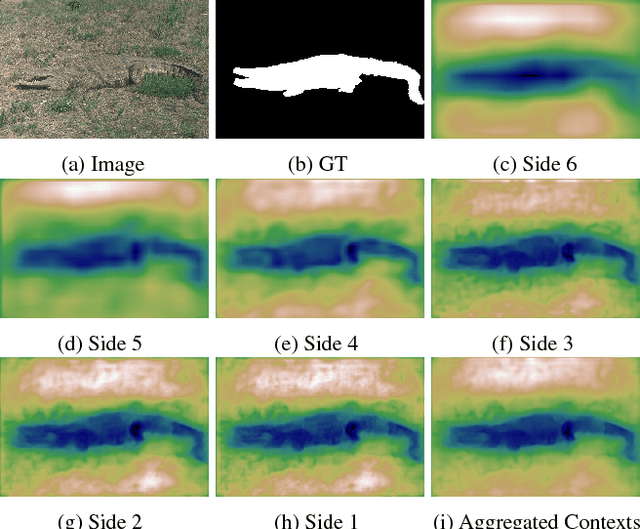
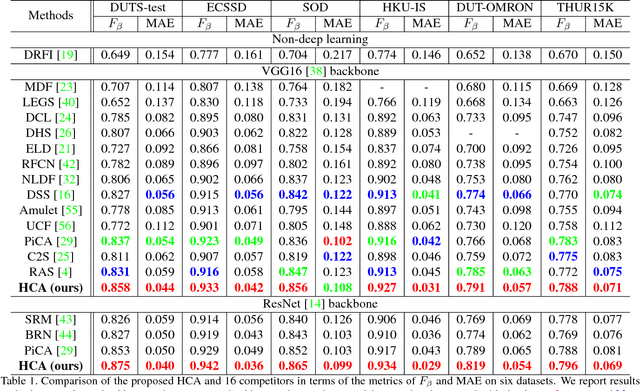


Recent progress on salient object detection mainly aims at exploiting how to effectively integrate convolutional side-output features in convolutional neural networks (CNN). Based on this, most of the existing state-of-the-art saliency detectors design complex network structures to fuse the side-output features of the backbone feature extraction networks. However, should the fusion strategies be more and more complex for accurate salient object detection? In this paper, we observe that the contexts of a natural image can be well expressed by a high-to-low self-learning of side-output convolutional features. As we know, the contexts of an image usually refer to the global structures, and the top layers of CNN usually learn to convey global information. On the other hand, it is difficult for the intermediate side-output features to express contextual information. Here, we design an hourglass network with intermediate supervision to learn contextual features in a high-to-low manner. The learned hierarchical contexts are aggregated to generate the hybrid contextual expression for an input image. At last, the hybrid contextual features can be used for accurate saliency estimation. We extensively evaluate our method on six challenging saliency datasets, and our simple method achieves state-of-the-art performance under various evaluation metrics. Code will be released upon paper acceptance.