 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNA: Deeply-supervised Nonlinear Aggregation for Salient Object Detection
Mar 28, 2019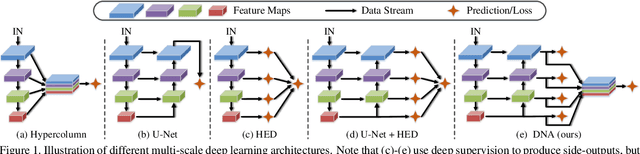

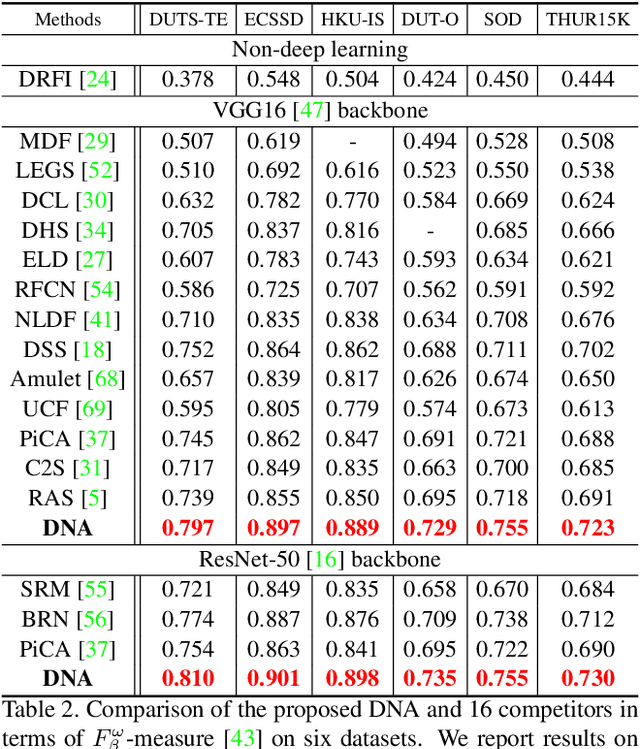
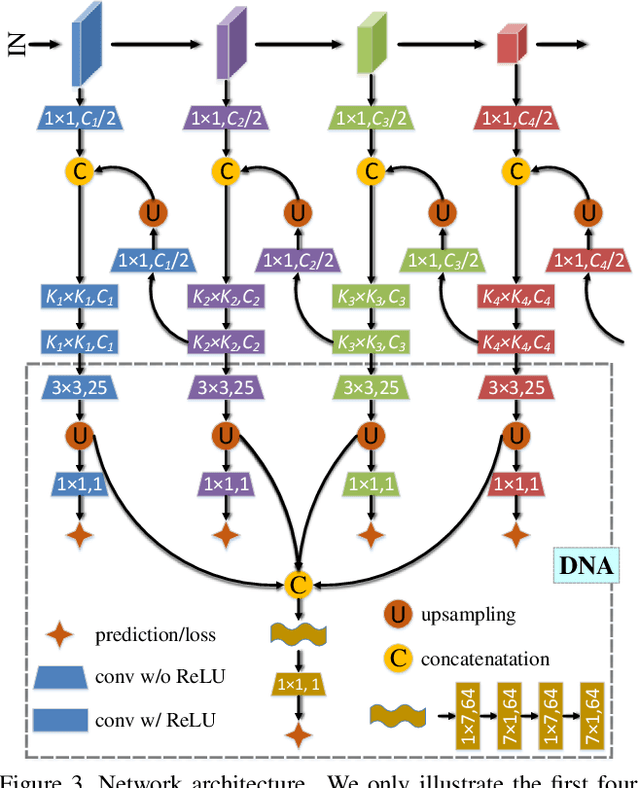
Recent progress on salient object detection mainly aims at exploiting how to effectively integrate multi-scale convolutional features in convolutional neural networks (CNNs). Many state-of-the-art methods impose deep supervision to perform side-output predictions that are linearly aggregated for final saliency prediction. In this paper, we theoretically and experimentally demonstrate that linear aggregation of side-output predictions is suboptimal, and it only makes limited use of the side-output information obtained by deep supervision. To solve this problem, we propose Deeply-supervised Nonlinear Aggregation (DNA) for better leveraging the complementary information of various side-outputs. Compared with existing methods, it i) aggregates side-output features rather than predictions, and ii) adopts nonlinear instead of linear transformations. Experiments demonstrate that DNA can successfully break through the bottleneck of current linear approaches. Specifically, the proposed saliency detector, a modified U-Net architecture with DNA, performs favorably against state-of-the-art methods on various datasets and evaluation metrics without bells and whistles. Code and data will be released upon paper acceptance.
Exploring Stereovision-Based 3-D Scene Reconstruction for Augmented Reality
Feb 17, 2019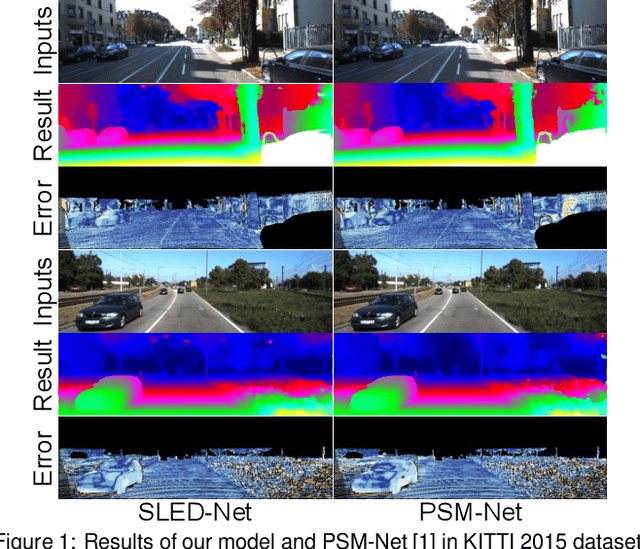


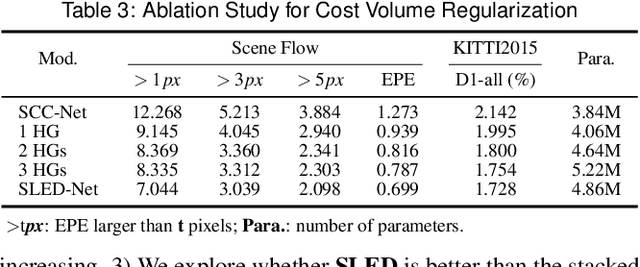
Three-dimensional (3-D) scene reconstruction is one of the key techniques in Augmented Reality (AR), which is related to the integration of image processing and display systems of complex information. Stereo matching is a computer vision based approach for 3-D scene reconstruction. In this paper, we explore an improved stereo matching network, SLED-Net, in which a Single Long Encoder-Decoder is proposed to replace the stacked hourglass network in PSM-Net for better contextual information learning. We compare SLED-Net to state-of-the-art methods recently published, and demonstrate its superior performance on Scene Flow and KITTI2015 test sets.
Salient Object Detection via High-to-Low Hierarchical Context Aggregation
Dec 28, 2018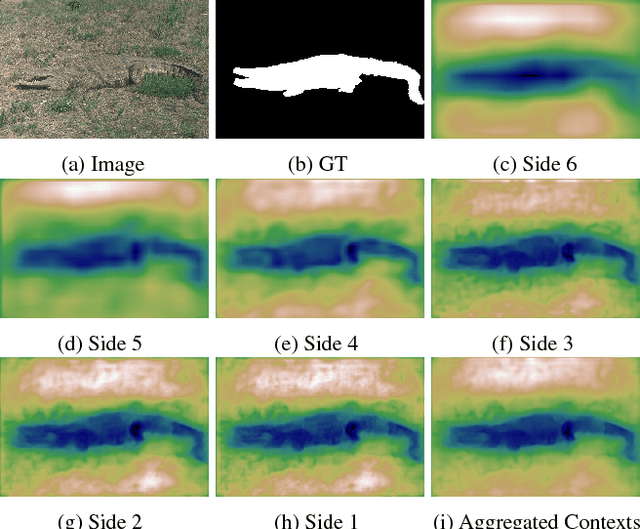
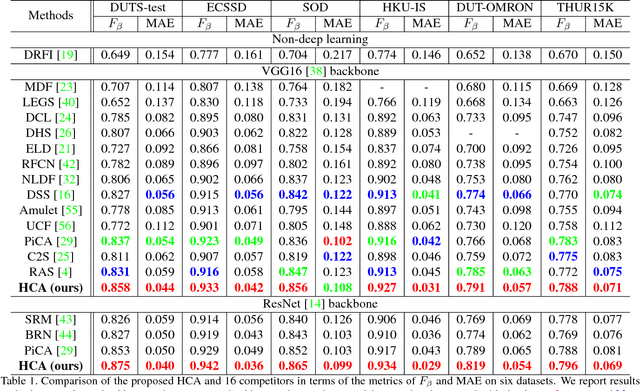


Recent progress on salient object detection mainly aims at exploiting how to effectively integrate convolutional side-output features in convolutional neural networks (CNN). Based on this, most of the existing state-of-the-art saliency detectors design complex network structures to fuse the side-output features of the backbone feature extraction networks. However, should the fusion strategies be more and more complex for accurate salient object detection? In this paper, we observe that the contexts of a natural image can be well expressed by a high-to-low self-learning of side-output convolutional features. As we know, the contexts of an image usually refer to the global structures, and the top layers of CNN usually learn to convey global information. On the other hand, it is difficult for the intermediate side-output features to express contextual information. Here, we design an hourglass network with intermediate supervision to learn contextual features in a high-to-low manner. The learned hierarchical contexts are aggregated to generate the hybrid contextual expression for an input image. At last, the hybrid contextual features can be used for accurate saliency estimation. We extensively evaluate our method on six challenging saliency datasets, and our simple method achieves state-of-the-art performance under various evaluation metrics. Code will be released upon paper acceptance.