Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Stereovision-Based 3-D Scene Reconstruction for Augmented Reality
Paper and Code
Feb 17, 2019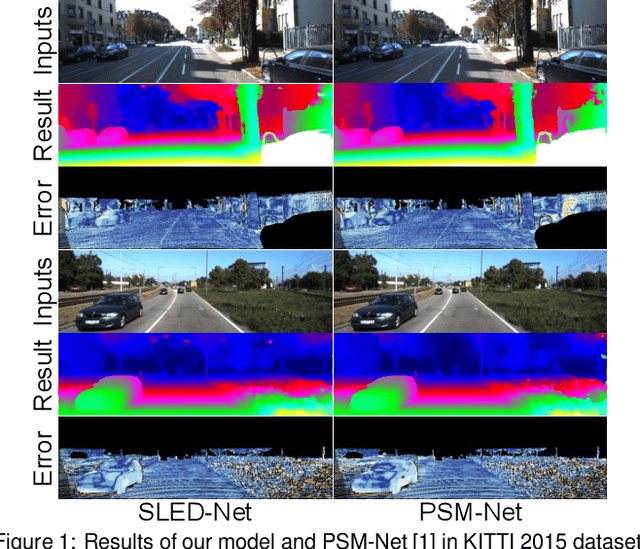


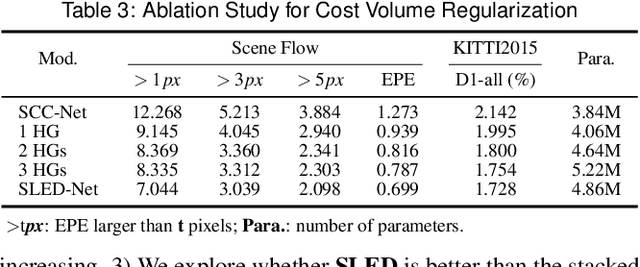
Three-dimensional (3-D) scene reconstruction is one of the key techniques in Augmented Reality (AR), which is related to the integration of image processing and display systems of complex information. Stereo matching is a computer vision based approach for 3-D scene reconstruction. In this paper, we explore an improved stereo matching network, SLED-Net, in which a Single Long Encoder-Decoder is proposed to replace the stacked hourglass network in PSM-Net for better contextual information learning. We compare SLED-Net to state-of-the-art methods recently published, and demonstrate its superior performance on Scene Flow and KITTI2015 test sets.
* To be published in IEEE VR2019 Conference as a Poster
View paper on