 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer in Convolutional Neural Networks
Paper and Code
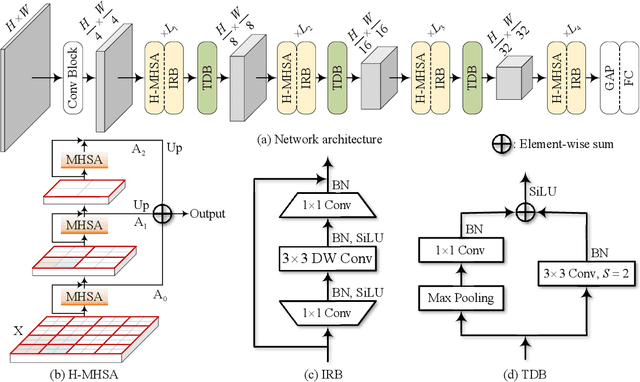
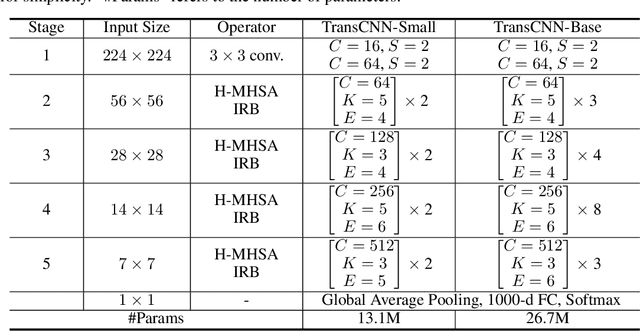

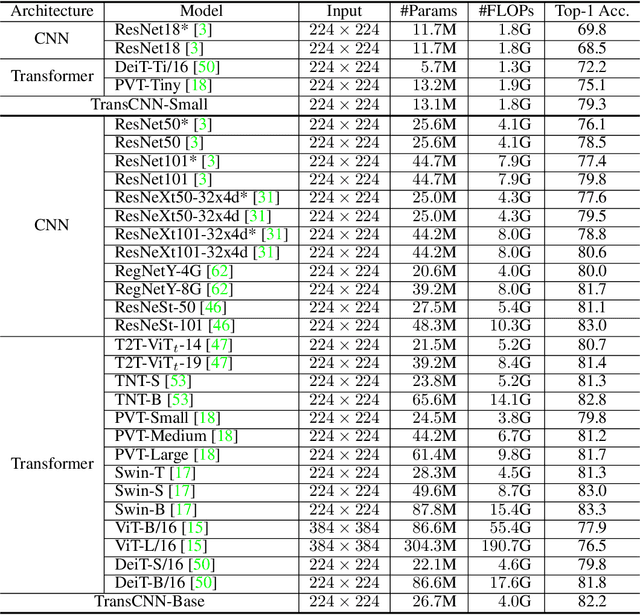
We tackle the low-efficiency flaw of vision transformer caused by the high computational/space complexity in Multi-Head Self-Attention (MHSA). To this end, we propose the Hierarchical MHSA (H-MHSA), whose representation is computed in a hierarchical manner. Specifically, our H-MHSA first learns feature relationships within small grids by viewing image patches as tokens. Then, small grids are merged into larger ones, within which feature relationship is learned by viewing each small grid at the preceding step as a token. This process is iterated to gradually reduce the number of tokens. The H-MHSA module is readily pluggable into any CNN architectures and amenable to training via backpropagation. We call this new backbone TransCNN, and it essentially inherits the advantages of both transformer and CNN. Experiments demonstrate that TransCNN achieves state-of-the-art accuracy for image recognition. Code and pretrained models are available at https://github.com/yun-liu/TransCNN. This technical report will keep updating by adding more experiments.