 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Compositional Flow Matching by geometric assembly from motion primitives
May 22, 2026Embodied trajectories, such as the executable motion sequences of robotic manipulators, underwater vehicles, and mobile robots, are a fundamental output of embodied AI. Modern generative models often treat them as a dense, monolithic signal generated point by point, fitting an intricate high-dimensional posterior while leaving the data's latent structure unmodeled, the same sample inefficiency long identified by the structured generative model literature. We argue that a compositional latent structure is a natural choice: many embodied tasks share recurring motion fragments that can be made explicit as a finite repertoire of reusable motion primitives, and compositional units naturally align with subtask boundaries to support task decomposition. Existing compositional generators, however, compose in a latent space and rely on post-hoc decoding to relate sampled units to actual trajectory segments. We instead compose directly in the physical trajectory space through a flow-matching framework with two coupled designs. Motion-Primitive Dictionary Learning equips each atom with a learnable length mask and binary starting indicators so the atom itself is the primitive, reused verbatim wherever it is placed. Structural Sparse Flow Matching with Geometric Constraints then generates a binary placement matrix using duration-aware tokenization and a differentiable geometric loss that enforces spatial continuity and temporal contiguity where adjacent primitives meet. On Open X-Embodiment and 3DMoTraj, the framework attains state-of-the-art accuracy and reduces the FDE/ADE ratio from 1.8 to 1.07, improving ADE by 19.2% and FDE by 21.0% over the strongest baseline.
Identifying and Calibrating Overconfidence in Noisy Speech Recognition
Sep 08, 2025Modern end-to-end automatic speech recognition (ASR) models like Whisper not only suffer from reduced recognition accuracy in noise, but also exhibit overconfidence - assigning high confidence to wrong predictions. We conduct a systematic analysis of Whisper's behavior in additive noise conditions and find that overconfident errors increase dramatically at low signal-to-noise ratios, with 10-20% of tokens incorrectly predicted with confidence above 0.7. To mitigate this, we propose a lightweight, post-hoc calibration framework that detects potential overconfidence and applies temperature scaling selectively to those tokens, without altering the underlying ASR model. Evaluations on the R-SPIN dataset demonstrate that, in the low signal-to-noise ratio range (-18 to -5 dB), our method reduces the expected calibration error (ECE) by 58% and triples the normalized cross entropy (NCE), yielding more reliable confidence estimates under severe noise conditions.
Unveiling Hidden Collaboration within Mixture-of-Experts in Large Language Models
Apr 16, 2025



Mixture-of-Experts based large language models (MoE LLMs) have shown significant promise in multitask adaptability by dynamically routing inputs to specialized experts. Despite their success, the collaborative mechanisms among experts are still not well understood, limiting both the interpretability and optimization of these models. In this paper, we focus on two critical issues: (1) identifying expert collaboration patterns, and (2) optimizing MoE LLMs through expert pruning. To address the first issue, we propose a hierarchical sparse dictionary learning (HSDL) method that uncovers the collaboration patterns among experts. For the second issue, we introduce the Contribution-Aware Expert Pruning (CAEP) algorithm, which effectively prunes low-contribution experts. Our extensive experiments demonstrate that expert collaboration patterns are closely linked to specific input types and exhibit semantic significance across various tasks. Moreover, pruning experiments show that our approach improves overall performance by 2.5\% on average, outperforming existing methods. These findings offer valuable insights into enhancing the efficiency and interpretability of MoE LLMs, offering a clearer understanding of expert interactions and improving model optimization.
Geographical hotspot prediction based on point cloud-voxel-community partition clustering
Mar 27, 2025

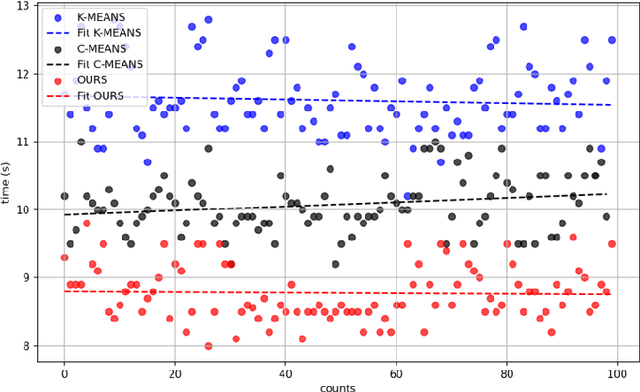

Existing solutions to the hotspot prediction problem in the field of geographic information remain at a relatively preliminary stage. This study presents a novel approach for detecting and predicting geographical hotspots, utilizing point cloud-voxel-community partition clustering. By analyzing high-dimensional data, we represent spatial information through point clouds, which are then subdivided into multiple voxels to enhance analytical efficiency. Our method identifies spatial voxels with similar characteristics through community partitioning, thereby revealing underlying patterns in hotspot distributions. Experimental results indicate that when applied to a dataset of archaeological sites in Turkey, our approach achieves a 19.31% increase in processing speed, with an accuracy loss of merely 6%, outperforming traditional clustering methods. This method not only provides a fresh perspective for hotspot prediction but also serves as an effective tool for high-dimensional data analysis.
Cross-modal Medical Image Generation Based on Pyramid Convolutional Attention Network
Nov 26, 2024


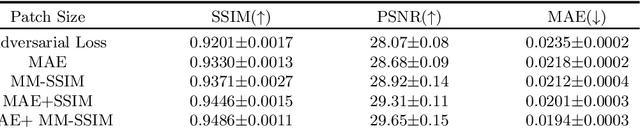
The integration of multimodal medical imaging can provide complementary and comprehensive information for the diagnosis of Alzheimer's disease (AD). However, in clinical practice, since positron emission tomography (PET) is often missing, multimodal images might be incomplete. To address this problem, we propose a method that can efficiently utilize structural magnetic resonance imaging (sMRI) image information to generate high-quality PET images. Our generation model efficiently utilizes pyramid convolution combined with channel attention mechanism to extract multi-scale local features in sMRI, and injects global correlation information into these features using self-attention mechanism to ensure the restoration of the generated PET image on local texture and global structure. Additionally, we introduce additional loss functions to guide the generation model in producing higher-quality PET images. Through experiments conducted on publicly available ADNI databases, the generated images outperform previous research methods in various performance indicators (average absolute error: 0.0194, peak signal-to-noise ratio: 29.65, structural similarity: 0.9486) and are close to real images. In promoting AD diagnosis, the generated images combined with their corresponding sMRI also showed excellent performance in AD diagnosis tasks (classification accuracy: 94.21 %), and outperformed previous research methods of the same type. The experimental results demonstrate that our method outperforms other competing methods in quantitative metrics, qualitative visualization, and evaluation criteria.
A Seq-to-Seq Transformer Premised Temporal Convolutional Network for Chinese Word Segmentation
May 21, 2019


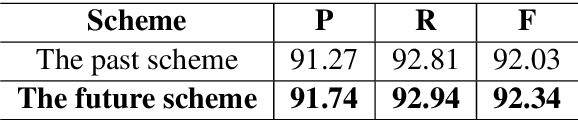
The prevalent approaches of Chinese word segmentation task almost rely on the Bi-LSTM neural network. However, the methods based the Bi-LSTM have some inherent drawbacks: hard to parallel computing, little efficient in applying the Dropout method to inhibit the Overfitting and little efficient in capturing the character information at the more distant site of a long sentence for the word segmentation task. In this work, we propose a sequence-to-sequence transformer model for Chinese word segmentation, which is premised a type of convolutional neural network named temporal convolutional network. The model uses the temporal convolutional network to construct an encoder, and uses one layer of fully-connected neural network to build a decoder, and applies the Dropout method to inhibit the Overfitting, and captures the character information at the distant site of a sentence by adding the layers of the encoder, and binds Conditional Random Fields model to train parameters, and uses the Viterbi algorithm to infer the final result of the Chinese word segmentation. The experiments on traditional Chinese corpora and simplified Chinese corpora show that the performance of Chinese word segmentation of the model is equivalent to the performance of the methods based the Bi-LSTM, and the model has a tremendous growth in parallel computing than the models based the Bi-LSTM.