 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopeax -- An Improved Clustering Topic Model with Density Peak Detection and Lexical-Semantic Term Importance
Jan 29, 2026Text clustering is today the most popular paradigm for topic modelling, both in academia and industry. Despite clustering topic models' apparent success, we identify a number of issues in Top2Vec and BERTopic, which remain largely unsolved. Firstly, these approaches are unreliable at discovering natural clusters in corpora, due to extreme sensitivity to sample size and hyperparameters, the default values of which result in suboptimal behaviour. Secondly, when estimating term importance, BERTopic ignores the semantic distance of keywords to topic vectors, while Top2Vec ignores word counts in the corpus. This results in, on the one hand, less coherent topics due to the presence of stop words and junk words, and lack of variety and trust on the other. In this paper, I introduce a new approach, \textbf{Topeax}, which discovers the number of clusters from peaks in density estimates, and combines lexical and semantic indices of term importance to gain high-quality topic keywords. Topeax is demonstrated to be better at both cluster recovery and cluster description than Top2Vec and BERTopic, while also exhibiting less erratic behaviour in response to changing sample size and hyperparameters.
topicwizard -- a Modern, Model-agnostic Framework for Topic Model Visualization and Interpretation
May 19, 2025Topic models are statistical tools that allow their users to gain qualitative and quantitative insights into the contents of textual corpora without the need for close reading. They can be applied in a wide range of settings from discourse analysis, through pretraining data curation, to text filtering. Topic models are typically parameter-rich, complex models, and interpreting these parameters can be challenging for their users. It is typical practice for users to interpret topics based on the top 10 highest ranking terms on a given topic. This list-of-words approach, however, gives users a limited and biased picture of the content of topics. Thoughtful user interface design and visualizations can help users gain a more complete and accurate understanding of topic models' output. While some visualization utilities do exist for topic models, these are typically limited to a certain type of topic model. We introduce topicwizard, a framework for model-agnostic topic model interpretation, that provides intuitive and interactive tools that help users examine the complex semantic relations between documents, words and topics learned by topic models.
MIEB: Massive Image Embedding Benchmark
Apr 14, 2025Image representations are often evaluated through disjointed, task-specific protocols, leading to a fragmented understanding of model capabilities. For instance, it is unclear whether an image embedding model adept at clustering images is equally good at retrieving relevant images given a piece of text. We introduce the Massive Image Embedding Benchmark (MIEB) to evaluate the performance of image and image-text embedding models across the broadest spectrum to date. MIEB spans 38 languages across 130 individual tasks, which we group into 8 high-level categories. We benchmark 50 models across our benchmark, finding that no single method dominates across all task categories. We reveal hidden capabilities in advanced vision models such as their accurate visual representation of texts, and their yet limited capabilities in interleaved encodings and matching images and texts in the presence of confounders. We also show that the performance of vision encoders on MIEB correlates highly with their performance when used in multimodal large language models. Our code, dataset, and leaderboard are publicly available at https://github.com/embeddings-benchmark/mteb.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Context is Key(NMF): Modelling Topical Information Dynamics in Chinese Diaspora Media
Oct 16, 2024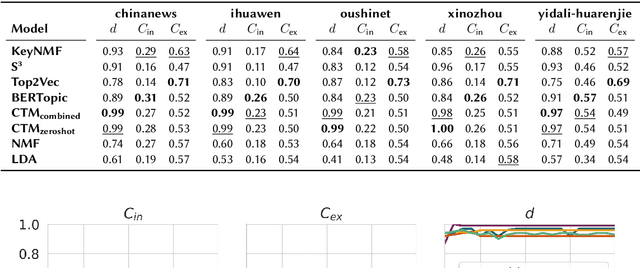
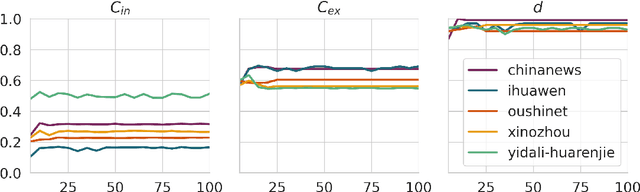
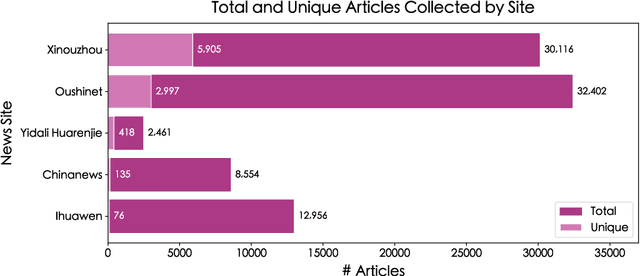
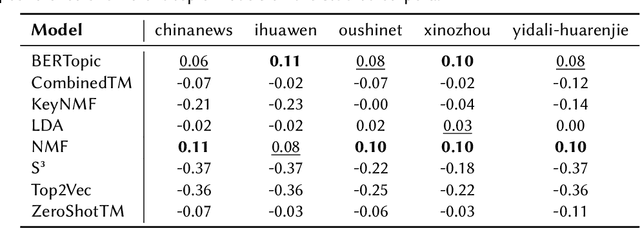
Does the People's Republic of China (PRC) interfere with European elections through ethnic Chinese diaspora media? This question forms the basis of an ongoing research project exploring how PRC narratives about European elections are represented in Chinese diaspora media, and thus the objectives of PRC news media manipulation. In order to study diaspora media efficiently and at scale, it is necessary to use techniques derived from quantitative text analysis, such as topic modelling. In this paper, we present a pipeline for studying information dynamics in Chinese media. Firstly, we present KeyNMF, a new approach to static and dynamic topic modelling using transformer-based contextual embedding models. We provide benchmark evaluations to demonstrate that our approach is competitive on a number of Chinese datasets and metrics. Secondly, we integrate KeyNMF with existing methods for describing information dynamics in complex systems. We apply this pipeline to data from five news sites, focusing on the period of time leading up to the 2024 European parliamentary elections. Our methods and results demonstrate the effectiveness of KeyNMF for studying information dynamics in Chinese media and lay groundwork for further work addressing the broader research questions.
$S^3$ -- Semantic Signal Separation
Jun 18, 2024



Topic models are useful tools for discovering latent semantic structures in large textual corpora. Topic modeling historically relied on bag-of-words representations of language. This approach makes models sensitive to the presence of stop words and noise, and does not utilize potentially useful contextual information. Recent efforts have been oriented at incorporating contextual neural representations in topic modeling and have been shown to outperform classical topic models. These approaches are, however, typically slow, volatile and still require preprocessing for optimal results. We present Semantic Signal Separation ($S^3$), a theory-driven topic modeling approach in neural embedding spaces. $S^3$ conceptualizes topics as independent axes of semantic space, and uncovers these with blind-source separation. Our approach provides the most diverse, highly coherent topics, requires no preprocessing, and is demonstrated to be the fastest contextually sensitive topic model to date. We offer an implementation of $S^3$, among other approaches, in the Turftopic Python package.
The Scandinavian Embedding Benchmarks: Comprehensive Assessment of Multilingual and Monolingual Text Embedding
Jun 04, 2024The evaluation of English text embeddings has transitioned from evaluating a handful of datasets to broad coverage across many tasks through benchmarks such as MTEB. However, this is not the case for multilingual text embeddings due to a lack of available benchmarks. To address this problem, we introduce the Scandinavian Embedding Benchmark (SEB). SEB is a comprehensive framework that enables text embedding evaluation for Scandinavian languages across 24 tasks, 10 subtasks, and 4 task categories. Building on SEB, we evaluate more than 26 models, uncovering significant performance disparities between public and commercial solutions not previously captured by MTEB. We open-source SEB and integrate it with MTEB, thus bridging the text embedding evaluation gap for Scandinavian languages.
Chatbots Are Not Reliable Text Annotators
Nov 09, 2023Recent research highlights the significant potential of ChatGPT for text annotation in social science research. However, ChatGPT is a closed-source product which has major drawbacks with regards to transparency, reproducibility, cost, and data protection. Recent advances in open-source (OS) large language models (LLMs) offer alternatives which remedy these challenges. This means that it is important to evaluate the performance of OS LLMs relative to ChatGPT and standard approaches to supervised machine learning classification. We conduct a systematic comparative evaluation of the performance of a range of OS LLM models alongside ChatGPT, using both zero- and few-shot learning as well as generic and custom prompts, with results compared to more traditional supervised classification models. Using a new dataset of Tweets from US news media, and focusing on simple binary text annotation tasks for standard social science concepts, we find significant variation in the performance of ChatGPT and OS models across the tasks, and that supervised classifiers consistently outperform both. Given the unreliable performance of ChatGPT and the significant challenges it poses to Open Science we advise against using ChatGPT for substantive text annotation tasks in social science research.