 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApriel-1.5-OpenReasoner: RL Post-Training for General-Purpose and Efficient Reasoning
Apr 03, 2026Building general-purpose reasoning models using reinforcement learning with verifiable rewards (RLVR) across diverse domains has been widely adopted by frontier open-weight models. However, their training recipes and domain mixtures are often not disclosed. Joint optimization across domains poses significant challenges: domains vary widely in rollout length, problem difficulty and sample efficiency. Further, models with long chain-of-thought traces increase inference cost and latency, making efficiency critical for practical deployment. We present Apriel-1.5-OpenReasoner, trained with a fully reproducible multi-domain RL post-training recipe on Apriel-Base, a 15B-parameter open-weight LLM, across five domains using public datasets: mathematics, code generation, instruction following, logical puzzles and function calling. We introduce an adaptive domain sampling mechanism that preserves target domain ratios despite heterogeneous rollout dynamics, and a difficulty-aware extension of the standard length penalty that, with no additional training overhead, encourages longer reasoning for difficult problems and shorter traces for easy ones. Trained with a strict 16K-token output budget, Apriel-1.5-OpenReasoner generalizes to 32K tokens at inference and improves over Apriel-Base on AIME 2025, GPQA, MMLU-Pro, and LiveCodeBench while producing 30-50% shorter reasoning traces. It matches strong open-weight models of similar size at lower token cost, thereby pushing the Pareto frontier of accuracy versus token budget.
Apriel-Reasoner: RL Post-Training for General-Purpose and Efficient Reasoning
Apr 02, 2026Building general-purpose reasoning models using reinforcement learning with verifiable rewards (RLVR) across diverse domains has been widely adopted by frontier open-weight models. However, their training recipes and domain mixtures are often not disclosed. Joint optimization across domains poses significant challenges: domains vary widely in rollout length, problem difficulty and sample efficiency. Further, models with long chain-of-thought traces increase inference cost and latency, making efficiency critical for practical deployment. We present Apriel-Reasoner, trained with a fully reproducible multi-domain RL post-training recipe on Apriel-Base, a 15B-parameter open-weight LLM, across five domains using public datasets: mathematics, code generation, instruction following, logical puzzles and function calling. We introduce an adaptive domain sampling mechanism that preserves target domain ratios despite heterogeneous rollout dynamics, and a difficulty-aware extension of the standard length penalty that, with no additional training overhead, encourages longer reasoning for difficult problems and shorter traces for easy ones. Trained with a strict 16K-token output budget, Apriel-Reasoner generalizes to 32K tokens at inference and improves over Apriel-Base on AIME 2025, GPQA, MMLU-Pro, and LiveCodeBench while producing 30-50% shorter reasoning traces. It matches strong open-weight models of similar size at lower token cost, thereby pushing the Pareto frontier of accuracy versus token budget.
LongRecall: A Structured Approach for Robust Recall Evaluation in Long-Form Text
Aug 20, 2025LongRecall. The completeness of machine-generated text, ensuring that it captures all relevant information, is crucial in domains such as medicine and law and in tasks like list-based question answering (QA), where omissions can have serious consequences. However, existing recall metrics often depend on lexical overlap, leading to errors with unsubstantiated entities and paraphrased answers, while LLM-as-a-Judge methods with long holistic prompts capture broader semantics but remain prone to misalignment and hallucinations without structured verification. We introduce LongRecall, a general three-stage recall evaluation framework that decomposes answers into self-contained facts, successively narrows plausible candidate matches through lexical and semantic filtering, and verifies their alignment through structured entailment checks. This design reduces false positives and false negatives while accommodating diverse phrasings and contextual variations, serving as a foundational building block for systematic recall assessment. We evaluate LongRecall on three challenging long-form QA benchmarks using both human annotations and LLM-based judges, demonstrating substantial improvements in recall accuracy over strong lexical and LLM-as-a-Judge baselines.
Self-Evolving Curriculum for LLM Reasoning
May 20, 2025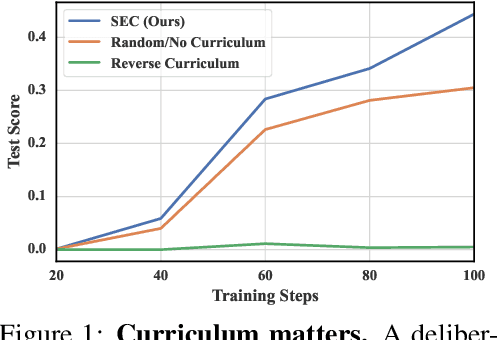
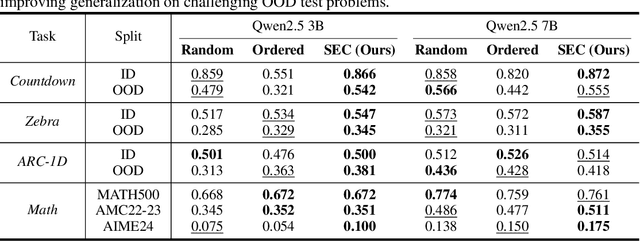
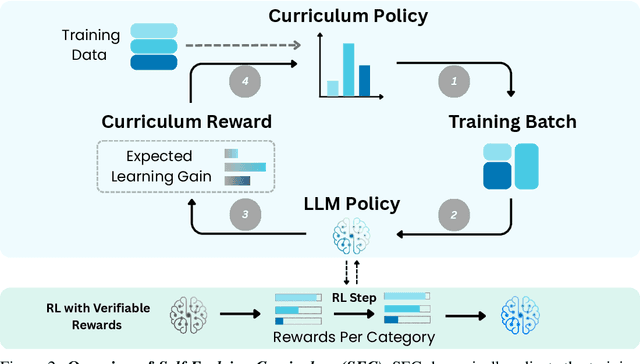
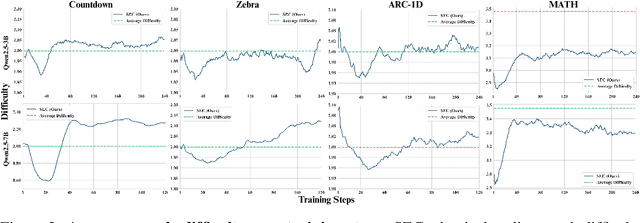
Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.
TapeAgents: a Holistic Framework for Agent Development and Optimization
Dec 11, 2024



We present TapeAgents, an agent framework built around a granular, structured log tape of the agent session that also plays the role of the session's resumable state. In TapeAgents we leverage tapes to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thought and action steps and append them to the tape. The environment then reacts to the agent's actions by likewise appending observation steps to the tape. By virtue of this tape-centred design, TapeAgents can provide AI practitioners with holistic end-to-end support. At the development stage, tapes facilitate session persistence, agent auditing, and step-by-step debugging. Post-deployment, one can reuse tapes for evaluation, fine-tuning, and prompt-tuning; crucially, one can adapt tapes from other agents or use revised historical tapes. In this report, we explain the TapeAgents design in detail. We demonstrate possible applications of TapeAgents with several concrete examples of building monolithic agents and multi-agent teams, of optimizing agent prompts and finetuning the agent's LLM. We present tooling prototypes and report a case study where we use TapeAgents to finetune a Llama-3.1-8B form-filling assistant to perform as well as GPT-4o while being orders of magnitude cheaper. Lastly, our comparative analysis shows that TapeAgents's advantages over prior frameworks stem from our novel design of the LLM agent as a resumable, modular state machine with a structured configuration, that generates granular, structured logs and that can transform these logs into training text -- a unique combination of features absent in previous work.
Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIR
Jul 10, 2024



The zero-shot effectiveness of neural retrieval models is often evaluated on the BEIR benchmark -- a combination of different IR evaluation datasets. Interestingly, previous studies found that particularly on the BEIR subset Touch\'e 2020, an argument retrieval task, neural retrieval models are considerably less effective than BM25. Still, so far, no further investigation has been conducted on what makes argument retrieval so "special". To more deeply analyze the respective potential limits of neural retrieval models, we run a reproducibility study on the Touch\'e 2020 data. In our study, we focus on two experiments: (i) a black-box evaluation (i.e., no model retraining), incorporating a theoretical exploration using retrieval axioms, and (ii) a data denoising evaluation involving post-hoc relevance judgments. Our black-box evaluation reveals an inherent bias of neural models towards retrieving short passages from the Touch\'e 2020 data, and we also find that quite a few of the neural models' results are unjudged in the Touch\'e 2020 data. As many of the short Touch\'e passages are not argumentative and thus non-relevant per se, and as the missing judgments complicate fair comparison, we denoise the Touch\'e 2020 data by excluding very short passages (less than 20 words) and by augmenting the unjudged data with post-hoc judgments following the Touch\'e guidelines. On the denoised data, the effectiveness of the neural models improves by up to 0.52 in nDCG@10, but BM25 is still more effective. Our code and the augmented Touch\'e 2020 dataset are available at \url{https://github.com/castorini/touche-error-analysis}.
LLMs Can Patch Up Missing Relevance Judgments in Evaluation
May 08, 2024Unjudged documents or holes in information retrieval benchmarks are considered non-relevant in evaluation, yielding no gains in measuring effectiveness. However, these missing judgments may inadvertently introduce biases into the evaluation as their prevalence for a retrieval model is heavily contingent on the pooling process. Thus, filling holes becomes crucial in ensuring reliable and accurate evaluation. Collecting human judgment for all documents is cumbersome and impractical. In this paper, we aim at leveraging large language models (LLMs) to automatically label unjudged documents. Our goal is to instruct an LLM using detailed instructions to assign fine-grained relevance judgments to holes. To this end, we systematically simulate scenarios with varying degrees of holes by randomly dropping relevant documents from the relevance judgment in TREC DL tracks. Our experiments reveal a strong correlation between our LLM-based method and ground-truth relevance judgments. Based on our simulation experiments conducted on three TREC DL datasets, in the extreme scenario of retaining only 10% of judgments, our method achieves a Kendall tau correlation of 0.87 and 0.92 on an average for Vicu\~na-7B and GPT-3.5 Turbo respectively.
NoMIRACL: Knowing When You Don't Know for Robust Multilingual Retrieval-Augmented Generation
Dec 18, 2023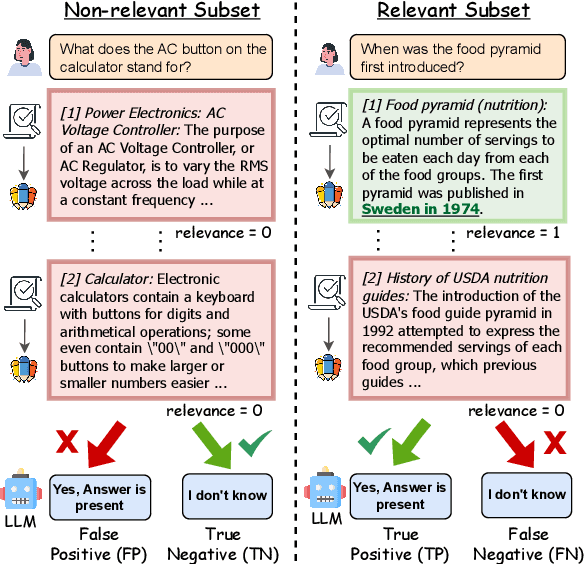

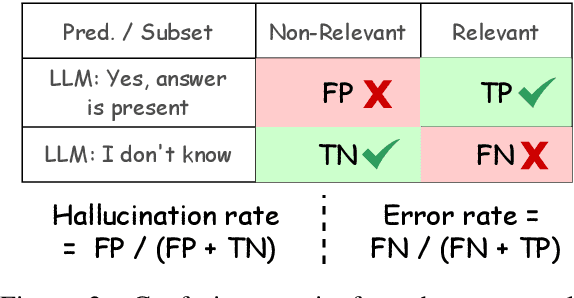
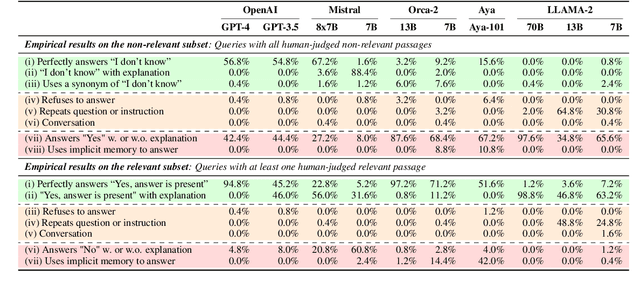
Retrieval-augmented generation (RAG) grounds large language model (LLM) output by leveraging external knowledge sources to reduce factual hallucinations. However, prior works lack a comprehensive evaluation of different language families, making it challenging to evaluate LLM robustness against errors in external retrieved knowledge. To overcome this, we establish NoMIRACL, a human-annotated dataset for evaluating LLM robustness in RAG across 18 typologically diverse languages. NoMIRACL includes both a non-relevant and a relevant subset. Queries in the non-relevant subset contain passages manually judged as non-relevant or noisy, whereas queries in the relevant subset include at least a single judged relevant passage. We measure LLM robustness using two metrics: (i) hallucination rate, measuring model tendency to hallucinate an answer, when the answer is not present in passages in the non-relevant subset, and (ii) error rate, measuring model inaccuracy to recognize relevant passages in the relevant subset. We build a GPT-4 baseline which achieves a 33.2% hallucination rate on the non-relevant and a 14.9% error rate on the relevant subset on average. Our evaluation reveals that GPT-4 hallucinates frequently in high-resource languages, such as French or English. This work highlights an important avenue for future research to improve LLM robustness to learn how to better reject non-relevant information in RAG.
HAGRID: A Human-LLM Collaborative Dataset for Generative Information-Seeking with Attribution
Jul 31, 2023



The rise of large language models (LLMs) had a transformative impact on search, ushering in a new era of search engines that are capable of generating search results in natural language text, imbued with citations for supporting sources. Building generative information-seeking models demands openly accessible datasets, which currently remain lacking. In this paper, we introduce a new dataset, HAGRID (Human-in-the-loop Attributable Generative Retrieval for Information-seeking Dataset) for building end-to-end generative information-seeking models that are capable of retrieving candidate quotes and generating attributed explanations. Unlike recent efforts that focus on human evaluation of black-box proprietary search engines, we built our dataset atop the English subset of MIRACL, a publicly available information retrieval dataset. HAGRID is constructed based on human and LLM collaboration. We first automatically collect attributed explanations that follow an in-context citation style using an LLM, i.e. GPT-3.5. Next, we ask human annotators to evaluate the LLM explanations based on two criteria: informativeness and attributability. HAGRID serves as a catalyst for the development of information-seeking models with better attribution capabilities.
Resources for Brewing BEIR: Reproducible Reference Models and an Official Leaderboard
Jun 13, 2023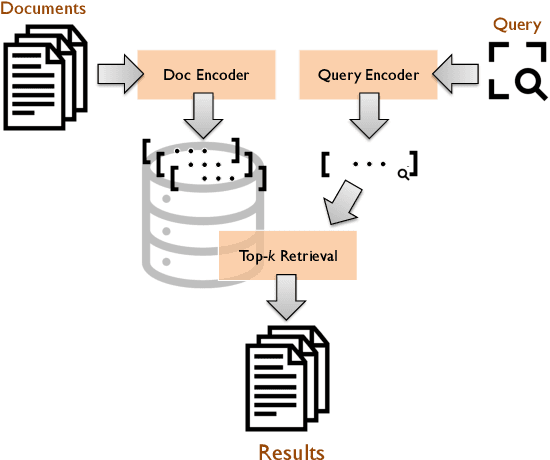
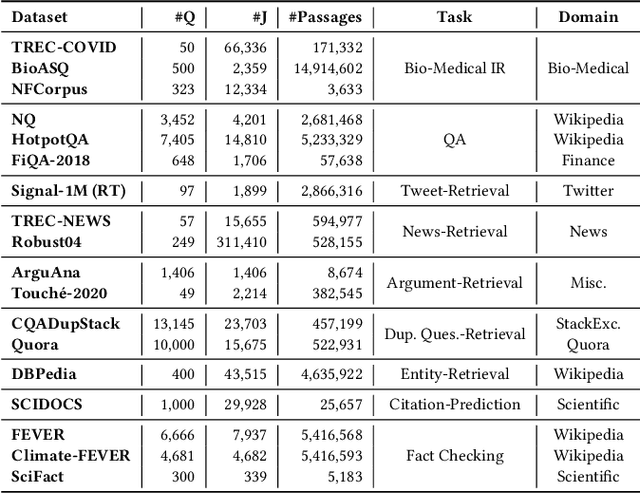

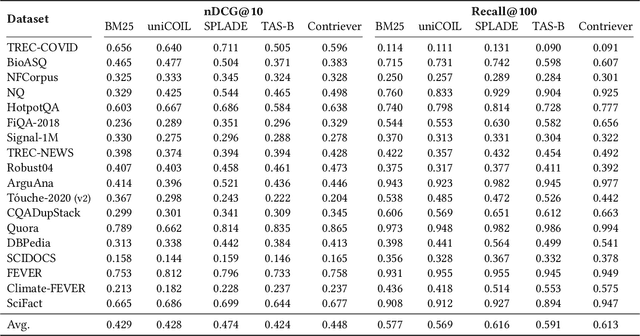
BEIR is a benchmark dataset for zero-shot evaluation of information retrieval models across 18 different domain/task combinations. In recent years, we have witnessed the growing popularity of a representation learning approach to building retrieval models, typically using pretrained transformers in a supervised setting. This naturally begs the question: How effective are these models when presented with queries and documents that differ from the training data? Examples include searching in different domains (e.g., medical or legal text) and with different types of queries (e.g., keywords vs. well-formed questions). While BEIR was designed to answer these questions, our work addresses two shortcomings that prevent the benchmark from achieving its full potential: First, the sophistication of modern neural methods and the complexity of current software infrastructure create barriers to entry for newcomers. To this end, we provide reproducible reference implementations that cover the two main classes of approaches: learned dense and sparse models. Second, there does not exist a single authoritative nexus for reporting the effectiveness of different models on BEIR, which has led to difficulty in comparing different methods. To remedy this, we present an official self-service BEIR leaderboard that provides fair and consistent comparisons of retrieval models. By addressing both shortcomings, our work facilitates future explorations in a range of interesting research questions that BEIR enables.