 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUBE: A Standard for Unifying Agent Benchmarks
Mar 16, 2026The proliferation of agent benchmarks has created critical fragmentation that threatens research productivity. Each new benchmark requires substantial custom integration, creating an "integration tax" that limits comprehensive evaluation. We propose CUBE (Common Unified Benchmark Environments), a universal protocol standard built on MCP and Gym that allows benchmarks to be wrapped once and used everywhere. By separating task, benchmark, package, and registry concerns into distinct API layers, CUBE enables any compliant platform to access any compliant benchmark for evaluation, RL training, or data generation without custom integration. We call on the community to contribute to the development of this standard before platform-specific implementations deepen fragmentation as benchmark production accelerates through 2026.
Just-in-time Episodic Feedback Hinter: Leveraging Offline Knowledge to Improve LLM Agents Adaptation
Oct 05, 2025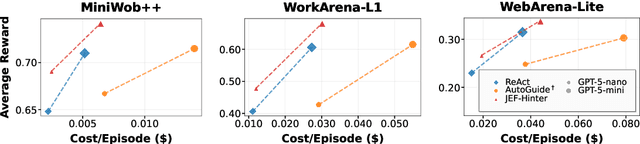
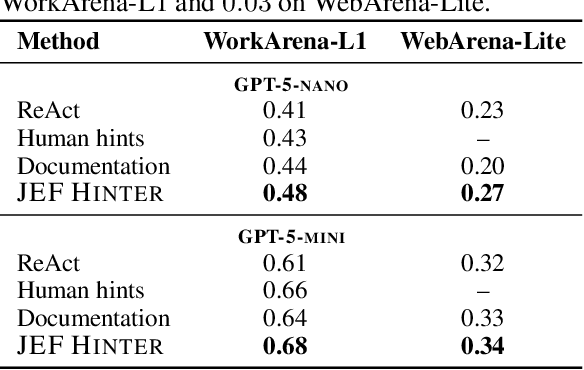
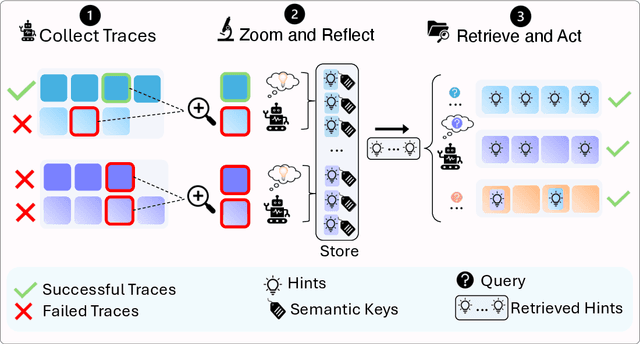
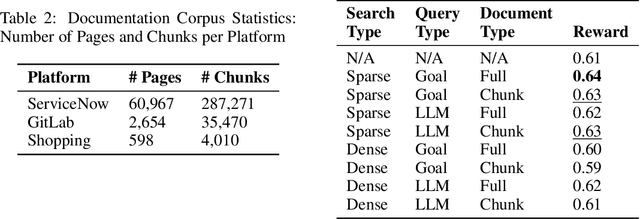
Large language model (LLM) agents perform well in sequential decision-making tasks, but improving them on unfamiliar domains often requires costly online interactions or fine-tuning on large expert datasets. These strategies are impractical for closed-source models and expensive for open-source ones, with risks of catastrophic forgetting. Offline trajectories offer reusable knowledge, yet demonstration-based methods struggle because raw traces are long, noisy, and tied to specific tasks. We present Just-in-time Episodic Feedback Hinter (JEF Hinter), an agentic system that distills offline traces into compact, context-aware hints. A zooming mechanism highlights decisive steps in long trajectories, capturing both strategies and pitfalls. Unlike prior methods, JEF Hinter leverages both successful and failed trajectories, extracting guidance even when only failure data is available, while supporting parallelized hint generation and benchmark-independent prompting. At inference, a retriever selects relevant hints for the current state, providing targeted guidance with transparency and traceability. Experiments on MiniWoB++, WorkArena-L1, and WebArena-Lite show that JEF Hinter consistently outperforms strong baselines, including human- and document-based hints.
TapeAgents: a Holistic Framework for Agent Development and Optimization
Dec 11, 2024



We present TapeAgents, an agent framework built around a granular, structured log tape of the agent session that also plays the role of the session's resumable state. In TapeAgents we leverage tapes to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thought and action steps and append them to the tape. The environment then reacts to the agent's actions by likewise appending observation steps to the tape. By virtue of this tape-centred design, TapeAgents can provide AI practitioners with holistic end-to-end support. At the development stage, tapes facilitate session persistence, agent auditing, and step-by-step debugging. Post-deployment, one can reuse tapes for evaluation, fine-tuning, and prompt-tuning; crucially, one can adapt tapes from other agents or use revised historical tapes. In this report, we explain the TapeAgents design in detail. We demonstrate possible applications of TapeAgents with several concrete examples of building monolithic agents and multi-agent teams, of optimizing agent prompts and finetuning the agent's LLM. We present tooling prototypes and report a case study where we use TapeAgents to finetune a Llama-3.1-8B form-filling assistant to perform as well as GPT-4o while being orders of magnitude cheaper. Lastly, our comparative analysis shows that TapeAgents's advantages over prior frameworks stem from our novel design of the LLM agent as a resumable, modular state machine with a structured configuration, that generates granular, structured logs and that can transform these logs into training text -- a unique combination of features absent in previous work.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
mGPT: Few-Shot Learners Go Multilingual
Apr 15, 2022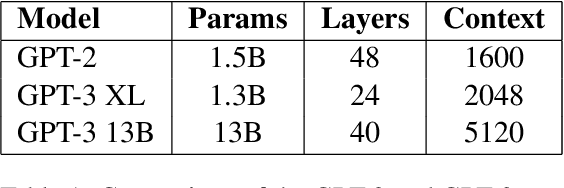
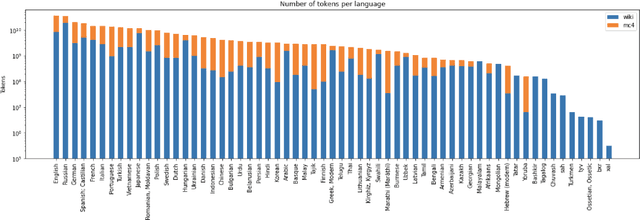
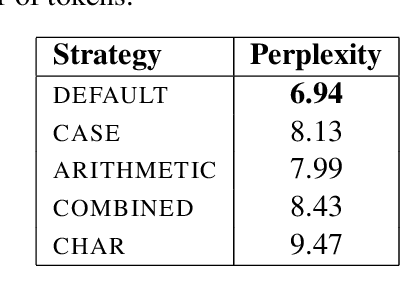
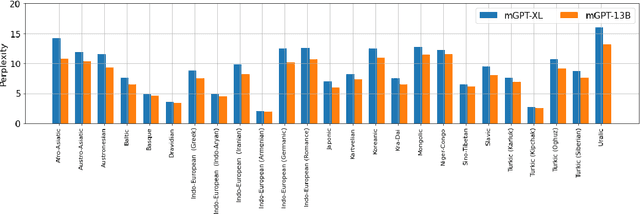
Recent studies report that autoregressive language models can successfully solve many NLP tasks via zero- and few-shot learning paradigms, which opens up new possibilities for using the pre-trained language models. This paper introduces two autoregressive GPT-like models with 1.3 billion and 13 billion parameters trained on 60 languages from 25 language families using Wikipedia and Colossal Clean Crawled Corpus. We reproduce the GPT-3 architecture using GPT-2 sources and the sparse attention mechanism; Deepspeed and Megatron frameworks allow us to parallelize the training and inference steps effectively. The resulting models show performance on par with the recently released XGLM models by Facebook, covering more languages and enhancing NLP possibilities for low resource languages of CIS countries and Russian small nations. We detail the motivation for the choices of the architecture design, thoroughly describe the data preparation pipeline, and train five small versions of the model to choose the most optimal multilingual tokenization strategy. We measure the model perplexity in all covered languages and evaluate it on the wide spectre of multilingual tasks, including classification, generative, sequence labeling and knowledge probing. The models were evaluated with the zero-shot and few-shot methods. Furthermore, we compared the classification tasks with the state-of-the-art multilingual model XGLM. source code and the mGPT XL model are publicly released.
PRANK: motion Prediction based on RANKing
Oct 22, 2020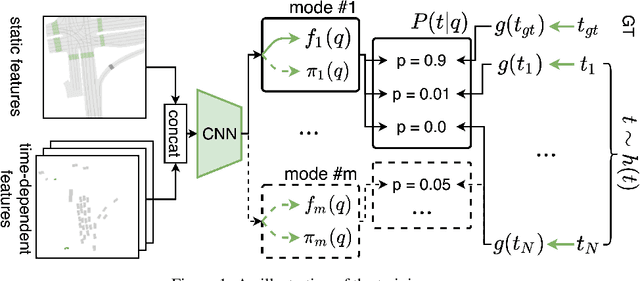
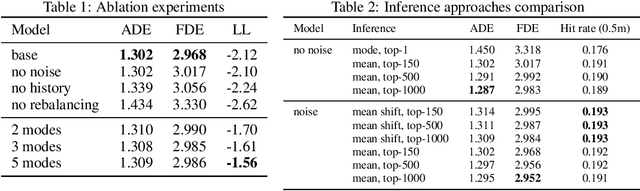
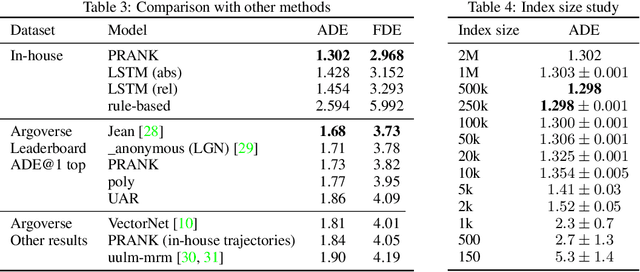
Predicting the motion of agents such as pedestrians or human-driven vehicles is one of the most critical problems in the autonomous driving domain. The overall safety of driving and the comfort of a passenger directly depend on its successful solution. The motion prediction problem also remains one of the most challenging problems in autonomous driving engineering, mainly due to high variance of the possible agent's future behavior given a situation. The two phenomena responsible for the said variance are the multimodality caused by the uncertainty of the agent's intent (e.g., turn right or move forward) and uncertainty in the realization of a given intent (e.g., which lane to turn into). To be useful within a real-time autonomous driving pipeline, a motion prediction system must provide efficient ways to describe and quantify this uncertainty, such as computing posterior modes and their probabilities or estimating density at the point corresponding to a given trajectory. It also should not put substantial density on physically impossible trajectories, as they can confuse the system processing the predictions. In this paper, we introduce the PRANK method, which satisfies these requirements. PRANK takes rasterized bird-eye images of agent's surroundings as an input and extracts features of the scene with a convolutional neural network. It then produces the conditional distribution of agent's trajectories plausible in the given scene. The key contribution of PRANK is a way to represent that distribution using nearest-neighbor methods in latent trajectory space, which allows for efficient inference in real time. We evaluate PRANK on the in-house and Argoverse datasets, where it shows competitive results.