 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust-in-time Episodic Feedback Hinter: Leveraging Offline Knowledge to Improve LLM Agents Adaptation
Oct 05, 2025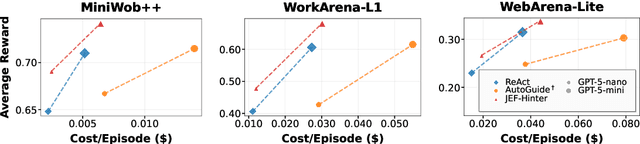
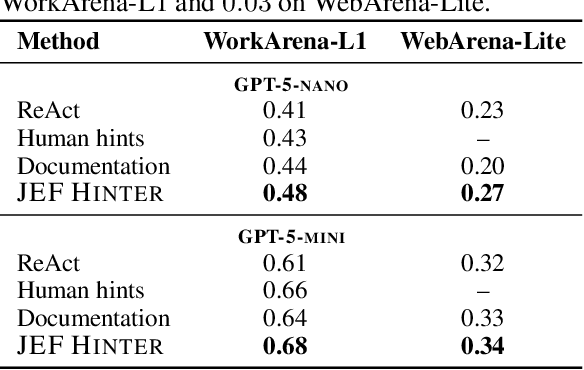
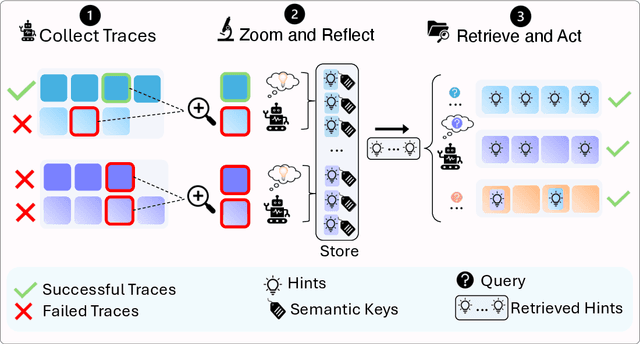
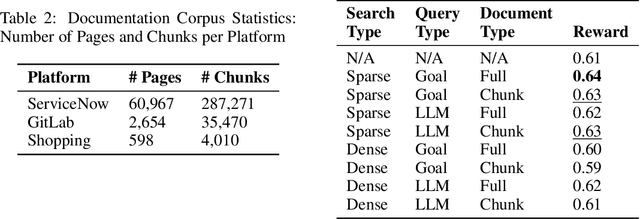
Large language model (LLM) agents perform well in sequential decision-making tasks, but improving them on unfamiliar domains often requires costly online interactions or fine-tuning on large expert datasets. These strategies are impractical for closed-source models and expensive for open-source ones, with risks of catastrophic forgetting. Offline trajectories offer reusable knowledge, yet demonstration-based methods struggle because raw traces are long, noisy, and tied to specific tasks. We present Just-in-time Episodic Feedback Hinter (JEF Hinter), an agentic system that distills offline traces into compact, context-aware hints. A zooming mechanism highlights decisive steps in long trajectories, capturing both strategies and pitfalls. Unlike prior methods, JEF Hinter leverages both successful and failed trajectories, extracting guidance even when only failure data is available, while supporting parallelized hint generation and benchmark-independent prompting. At inference, a retriever selects relevant hints for the current state, providing targeted guidance with transparency and traceability. Experiments on MiniWoB++, WorkArena-L1, and WebArena-Lite show that JEF Hinter consistently outperforms strong baselines, including human- and document-based hints.
Fine-Tune an SLM or Prompt an LLM? The Case of Generating Low-Code Workflows
May 30, 2025Large Language Models (LLMs) such as GPT-4o can handle a wide range of complex tasks with the right prompt. As per token costs are reduced, the advantages of fine-tuning Small Language Models (SLMs) for real-world applications -- faster inference, lower costs -- may no longer be clear. In this work, we present evidence that, for domain-specific tasks that require structured outputs, SLMs still have a quality advantage. We compare fine-tuning an SLM against prompting LLMs on the task of generating low-code workflows in JSON form. We observe that while a good prompt can yield reasonable results, fine-tuning improves quality by 10% on average. We also perform systematic error analysis to reveal model limitations.
Multi-task retriever fine-tuning for domain-specific and efficient RAG
Jan 08, 2025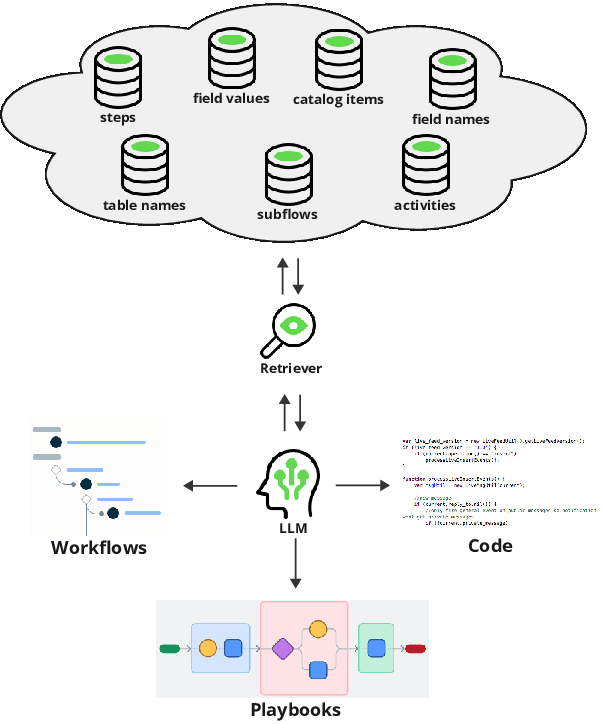

Retrieval-Augmented Generation (RAG) has become ubiquitous when deploying Large Language Models (LLMs), as it can address typical limitations such as generating hallucinated or outdated information. However, when building real-world RAG applications, practical issues arise. First, the retrieved information is generally domain-specific. Since it is computationally expensive to fine-tune LLMs, it is more feasible to fine-tune the retriever to improve the quality of the data included in the LLM input. Second, as more applications are deployed in the same real-world system, one cannot afford to deploy separate retrievers. Moreover, these RAG applications normally retrieve different kinds of data. Our solution is to instruction fine-tune a small retriever encoder on a variety of domain-specific tasks to allow us to deploy one encoder that can serve many use cases, thereby achieving low-cost, scalability, and speed. We show how this encoder generalizes to out-of-domain settings as well as to an unseen retrieval task on real-world enterprise use cases.
Generating a Low-code Complete Workflow via Task Decomposition and RAG
Nov 29, 2024



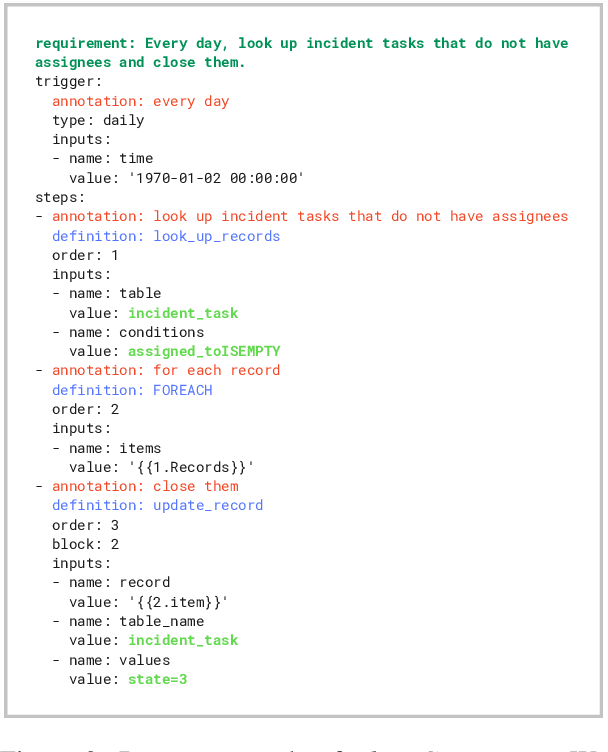
AI technologies are moving rapidly from research to production. With the popularity of Foundation Models (FMs) that generate text, images, and video, AI-based systems are increasing their complexity. Compared to traditional AI-based software, systems employing FMs, or GenAI-based systems, are more difficult to design due to their scale and versatility. This makes it necessary to document best practices, known as design patterns in software engineering, that can be used across GenAI applications. Our first contribution is to formalize two techniques, Task Decomposition and Retrieval-Augmented Generation (RAG), as design patterns for GenAI-based systems. We discuss their trade-offs in terms of software quality attributes and comment on alternative approaches. We recommend to AI practitioners to consider these techniques not only from a scientific perspective but also from the standpoint of desired engineering properties such as flexibility, maintainability, safety, and security. As a second contribution, we describe our industry experience applying Task Decomposition and RAG to build a complex real-world GenAI application for enterprise users: Workflow Generation. The task of generating workflows entails generating a specific plan using data from the system environment, taking as input a user requirement. As these two patterns affect the entire AI development cycle, we explain how they impacted the dataset creation, model training, model evaluation, and deployment phases.
Reducing hallucination in structured outputs via Retrieval-Augmented Generation
Apr 12, 2024



A common and fundamental limitation of Generative AI (GenAI) is its propensity to hallucinate. While large language models (LLM) have taken the world by storm, without eliminating or at least reducing hallucinations, real-world GenAI systems may face challenges in user adoption. In the process of deploying an enterprise application that produces workflows based on natural language requirements, we devised a system leveraging Retrieval Augmented Generation (RAG) to greatly improve the quality of the structured output that represents such workflows. Thanks to our implementation of RAG, our proposed system significantly reduces hallucinations in the output and improves the generalization of our LLM in out-of-domain settings. In addition, we show that using a small, well-trained retriever encoder can reduce the size of the accompanying LLM, thereby making deployments of LLM-based systems less resource-intensive.
Azimuth: Systematic Error Analysis for Text Classification
Dec 19, 2022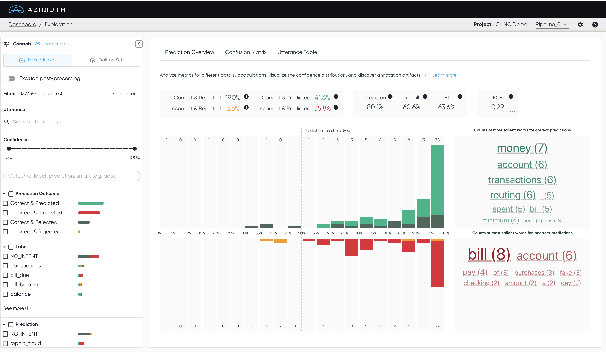


We present Azimuth, an open-source and easy-to-use tool to perform error analysis for text classification. Compared to other stages of the ML development cycle, such as model training and hyper-parameter tuning, the process and tooling for the error analysis stage are less mature. However, this stage is critical for the development of reliable and trustworthy AI systems. To make error analysis more systematic, we propose an approach comprising dataset analysis and model quality assessment, which Azimuth facilitates. We aim to help AI practitioners discover and address areas where the model does not generalize by leveraging and integrating a range of ML techniques, such as saliency maps, similarity, uncertainty, and behavioral analyses, all in one tool. Our code and documentation are available at github.com/servicenow/azimuth.