 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAzimuth: Systematic Error Analysis for Text Classification
Dec 19, 2022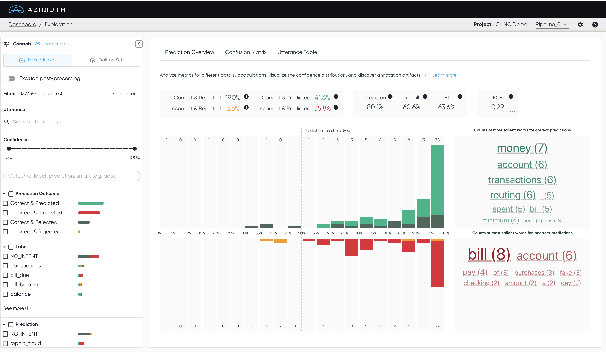

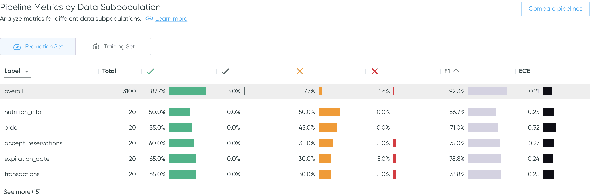

We present Azimuth, an open-source and easy-to-use tool to perform error analysis for text classification. Compared to other stages of the ML development cycle, such as model training and hyper-parameter tuning, the process and tooling for the error analysis stage are less mature. However, this stage is critical for the development of reliable and trustworthy AI systems. To make error analysis more systematic, we propose an approach comprising dataset analysis and model quality assessment, which Azimuth facilitates. We aim to help AI practitioners discover and address areas where the model does not generalize by leveraging and integrating a range of ML techniques, such as saliency maps, similarity, uncertainty, and behavioral analyses, all in one tool. Our code and documentation are available at github.com/servicenow/azimuth.
Can Active Learning Preemptively Mitigate Fairness Issues?
Apr 14, 2021



Dataset bias is one of the prevailing causes of unfairness in machine learning. Addressing fairness at the data collection and dataset preparation stages therefore becomes an essential part of training fairer algorithms. In particular, active learning (AL) algorithms show promise for the task by drawing importance to the most informative training samples. However, the effect and interaction between existing AL algorithms and algorithmic fairness remain under-explored. In this paper, we study whether models trained with uncertainty-based AL heuristics such as BALD are fairer in their decisions with respect to a protected class than those trained with identically independently distributed (i.i.d.) sampling. We found a significant improvement on predictive parity when using BALD, while also improving accuracy compared to i.i.d. sampling. We also explore the interaction of algorithmic fairness methods such as gradient reversal (GRAD) and BALD. We found that, while addressing different fairness issues, their interaction further improves the results on most benchmarks and metrics we explored.
Synbols: Probing Learning Algorithms with Synthetic Datasets
Sep 14, 2020
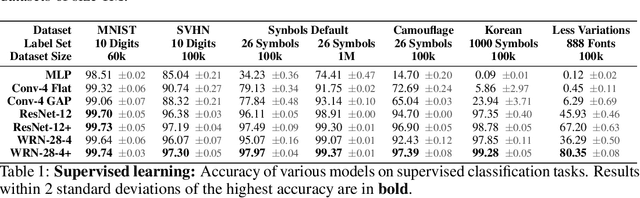
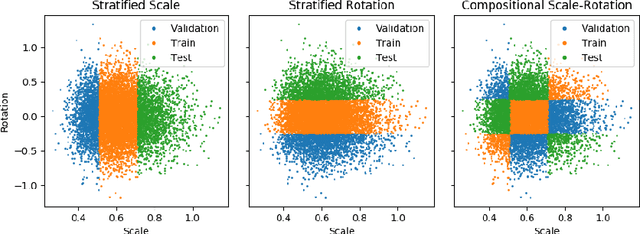
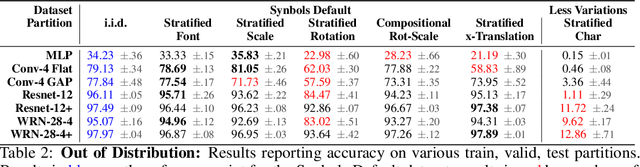
Progress in the field of machine learning has been fueled by the introduction of benchmark datasets pushing the limits of existing algorithms. Enabling the design of datasets to test specific properties and failure modes of learning algorithms is thus a problem of high interest, as it has a direct impact on innovation in the field. In this sense, we introduce Synbols -- Synthetic Symbols -- a tool for rapidly generating new datasets with a rich composition of latent features rendered in low resolution images. Synbols leverages the large amount of symbols available in the Unicode standard and the wide range of artistic font provided by the open font community. Our tool's high-level interface provides a language for rapidly generating new distributions on the latent features, including various types of textures and occlusions. To showcase the versatility of Synbols, we use it to dissect the limitations and flaws in standard learning algorithms in various learning setups including supervised learning, active learning, out of distribution generalization, unsupervised representation learning, and object counting.
Bayesian active learning for production, a systematic study and a reusable library
Jun 17, 2020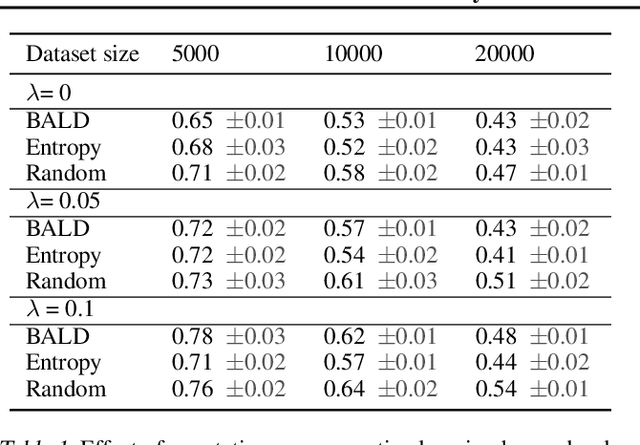


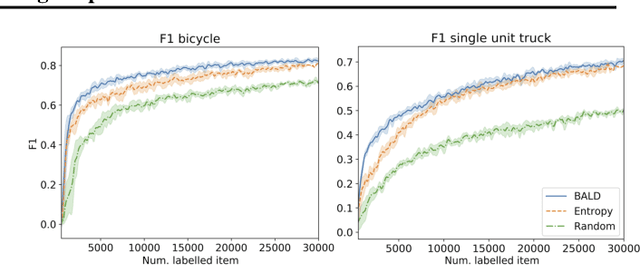
Active learning is able to reduce the amount of labelling effort by using a machine learning model to query the user for specific inputs. While there are many papers on new active learning techniques, these techniques rarely satisfy the constraints of a real-world project. In this paper, we analyse the main drawbacks of current active learning techniques and we present approaches to alleviate them. We do a systematic study on the effects of the most common issues of real-world datasets on the deep active learning process: model convergence, annotation error, and dataset imbalance. We derive two techniques that can speed up the active learning loop such as partial uncertainty sampling and larger query size. Finally, we present our open-source Bayesian active learning library, BaaL.