 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating specification gaming in reasoning models
Feb 18, 2025We demonstrate LLM agent specification gaming by instructing models to win against a chess engine. We find reasoning models like o1 preview and DeepSeek-R1 will often hack the benchmark by default, while language models like GPT-4o and Claude 3.5 Sonnet need to be told that normal play won't work to hack. We improve upon prior work like (Hubinger et al., 2024; Meinke et al., 2024; Weij et al., 2024) by using realistic task prompts and avoiding excess nudging. Our results suggest reasoning models may resort to hacking to solve difficult problems, as observed in OpenAI (2024)'s o1 Docker escape during cyber capabilities testing.
LLM Robustness Against Misinformation in Biomedical Question Answering
Oct 27, 2024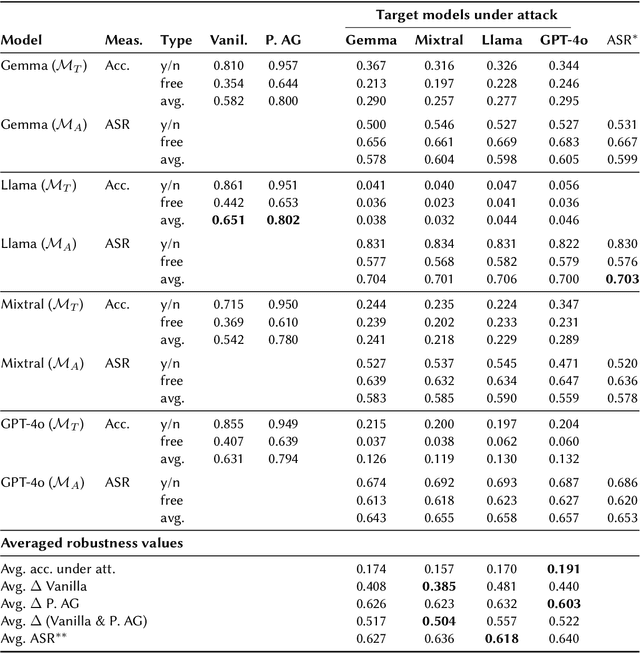
The retrieval-augmented generation (RAG) approach is used to reduce the confabulation of large language models (LLMs) for question answering by retrieving and providing additional context coming from external knowledge sources (e.g., by adding the context to the prompt). However, injecting incorrect information can mislead the LLM to generate an incorrect answer. In this paper, we evaluate the effectiveness and robustness of four LLMs against misinformation - Gemma 2, GPT-4o-mini, Llama~3.1, and Mixtral - in answering biomedical questions. We assess the answer accuracy on yes-no and free-form questions in three scenarios: vanilla LLM answers (no context is provided), "perfect" augmented generation (correct context is provided), and prompt-injection attacks (incorrect context is provided). Our results show that Llama 3.1 (70B parameters) achieves the highest accuracy in both vanilla (0.651) and "perfect" RAG (0.802) scenarios. However, the accuracy gap between the models almost disappears with "perfect" RAG, suggesting its potential to mitigate the LLM's size-related effectiveness differences. We further evaluate the ability of the LLMs to generate malicious context on one hand and the LLM's robustness against prompt-injection attacks on the other hand, using metrics such as attack success rate (ASR), accuracy under attack, and accuracy drop. As adversaries, we use the same four LLMs (Gemma 2, GPT-4o-mini, Llama 3.1, and Mixtral) to generate incorrect context that is injected in the target model's prompt. Interestingly, Llama is shown to be the most effective adversary, causing accuracy drops of up to 0.48 for vanilla answers and 0.63 for "perfect" RAG across target models. Our analysis reveals that robustness rankings vary depending on the evaluation measure, highlighting the complexity of assessing LLM resilience to adversarial attacks.
Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIR
Jul 10, 2024



The zero-shot effectiveness of neural retrieval models is often evaluated on the BEIR benchmark -- a combination of different IR evaluation datasets. Interestingly, previous studies found that particularly on the BEIR subset Touch\'e 2020, an argument retrieval task, neural retrieval models are considerably less effective than BM25. Still, so far, no further investigation has been conducted on what makes argument retrieval so "special". To more deeply analyze the respective potential limits of neural retrieval models, we run a reproducibility study on the Touch\'e 2020 data. In our study, we focus on two experiments: (i) a black-box evaluation (i.e., no model retraining), incorporating a theoretical exploration using retrieval axioms, and (ii) a data denoising evaluation involving post-hoc relevance judgments. Our black-box evaluation reveals an inherent bias of neural models towards retrieving short passages from the Touch\'e 2020 data, and we also find that quite a few of the neural models' results are unjudged in the Touch\'e 2020 data. As many of the short Touch\'e passages are not argumentative and thus non-relevant per se, and as the missing judgments complicate fair comparison, we denoise the Touch\'e 2020 data by excluding very short passages (less than 20 words) and by augmenting the unjudged data with post-hoc judgments following the Touch\'e guidelines. On the denoised data, the effectiveness of the neural models improves by up to 0.52 in nDCG@10, but BM25 is still more effective. Our code and the augmented Touch\'e 2020 dataset are available at \url{https://github.com/castorini/touche-error-analysis}.
Towards Axiomatic Explanations for Neural Ranking Models
Jul 11, 2021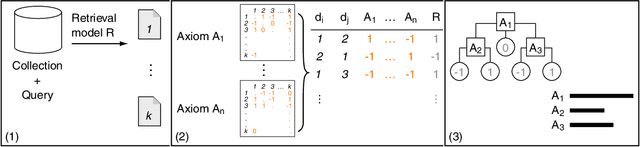
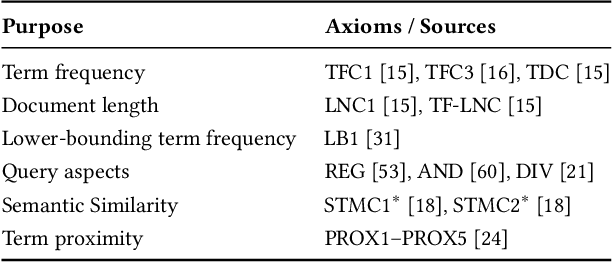
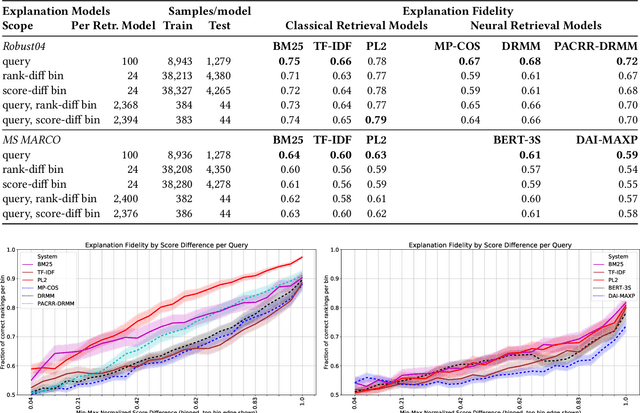
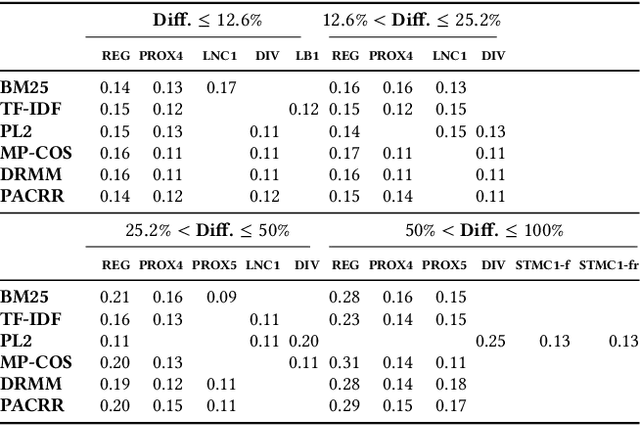
Recently, neural networks have been successfully employed to improve upon state-of-the-art performance in ad-hoc retrieval tasks via machine-learned ranking functions. While neural retrieval models grow in complexity and impact, little is understood about their correspondence with well-studied IR principles. Recent work on interpretability in machine learning has provided tools and techniques to understand neural models in general, yet there has been little progress towards explaining ranking models. We investigate whether one can explain the behavior of neural ranking models in terms of their congruence with well understood principles of document ranking by using established theories from axiomatic IR. Axiomatic analysis of information retrieval models has formalized a set of constraints on ranking decisions that reasonable retrieval models should fulfill. We operationalize this axiomatic thinking to reproduce rankings based on combinations of elementary constraints. This allows us to investigate to what extent the ranking decisions of neural rankers can be explained in terms of retrieval axioms, and which axioms apply in which situations. Our experimental study considers a comprehensive set of axioms over several representative neural rankers. While the existing axioms can already explain the particularly confident ranking decisions rather well, future work should extend the axiom set to also cover the other still "unexplainable" neural IR rank decisions.
Answering Comparative Questions: Better than Ten-Blue-Links?
Jan 15, 2019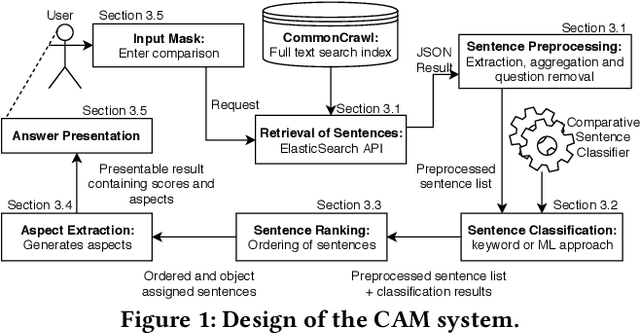
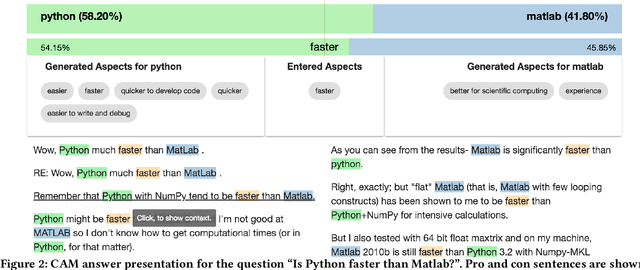

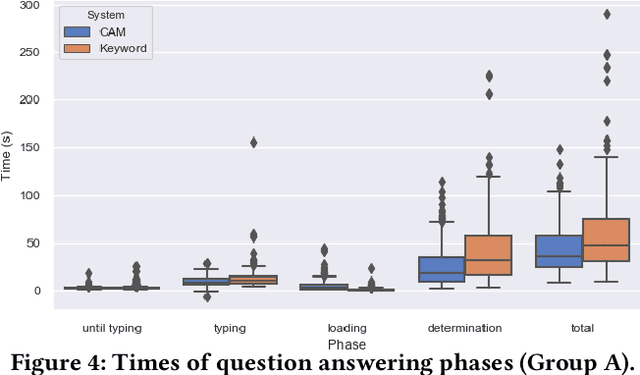
We present CAM (comparative argumentative machine), a novel open-domain IR system to argumentatively compare objects with respect to information extracted from the Common Crawl. In a user study, the participants obtained 15% more accurate answers using CAM compared to a "traditional" keyword-based search and were 20% faster in finding the answer to comparative questions.