 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Robustness Against Misinformation in Biomedical Question Answering
Paper and Code
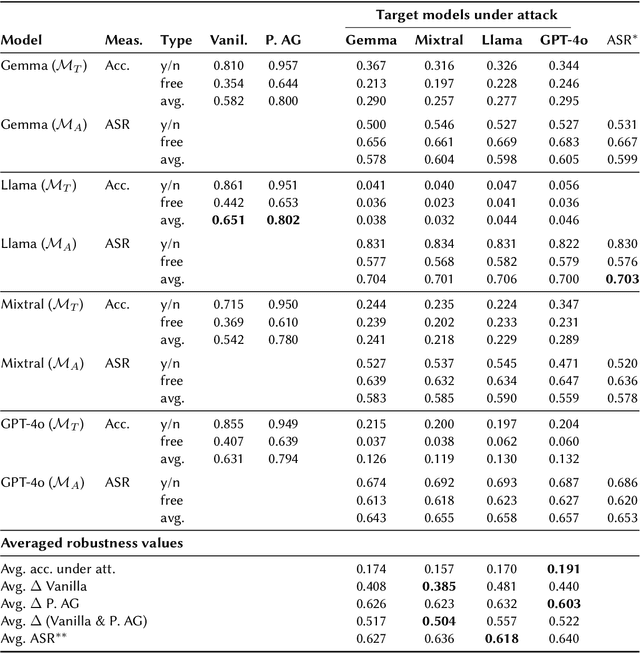
The retrieval-augmented generation (RAG) approach is used to reduce the confabulation of large language models (LLMs) for question answering by retrieving and providing additional context coming from external knowledge sources (e.g., by adding the context to the prompt). However, injecting incorrect information can mislead the LLM to generate an incorrect answer. In this paper, we evaluate the effectiveness and robustness of four LLMs against misinformation - Gemma 2, GPT-4o-mini, Llama~3.1, and Mixtral - in answering biomedical questions. We assess the answer accuracy on yes-no and free-form questions in three scenarios: vanilla LLM answers (no context is provided), "perfect" augmented generation (correct context is provided), and prompt-injection attacks (incorrect context is provided). Our results show that Llama 3.1 (70B parameters) achieves the highest accuracy in both vanilla (0.651) and "perfect" RAG (0.802) scenarios. However, the accuracy gap between the models almost disappears with "perfect" RAG, suggesting its potential to mitigate the LLM's size-related effectiveness differences. We further evaluate the ability of the LLMs to generate malicious context on one hand and the LLM's robustness against prompt-injection attacks on the other hand, using metrics such as attack success rate (ASR), accuracy under attack, and accuracy drop. As adversaries, we use the same four LLMs (Gemma 2, GPT-4o-mini, Llama 3.1, and Mixtral) to generate incorrect context that is injected in the target model's prompt. Interestingly, Llama is shown to be the most effective adversary, causing accuracy drops of up to 0.48 for vanilla answers and 0.63 for "perfect" RAG across target models. Our analysis reveals that robustness rankings vary depending on the evaluation measure, highlighting the complexity of assessing LLM resilience to adversarial attacks.