 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Demonstrating specification gaming in reasoning models
Feb 18, 2025We demonstrate LLM agent specification gaming by instructing models to win against a chess engine. We find reasoning models like o1 preview and DeepSeek-R1 will often hack the benchmark by default, while language models like GPT-4o and Claude 3.5 Sonnet need to be told that normal play won't work to hack. We improve upon prior work like (Hubinger et al., 2024; Meinke et al., 2024; Weij et al., 2024) by using realistic task prompts and avoiding excess nudging. Our results suggest reasoning models may resort to hacking to solve difficult problems, as observed in OpenAI (2024)'s o1 Docker escape during cyber capabilities testing.
Unelicitable Backdoors in Language Models via Cryptographic Transformer Circuits
Jun 03, 2024The rapid proliferation of open-source language models significantly increases the risks of downstream backdoor attacks. These backdoors can introduce dangerous behaviours during model deployment and can evade detection by conventional cybersecurity monitoring systems. In this paper, we introduce a novel class of backdoors in autoregressive transformer models, that, in contrast to prior art, are unelicitable in nature. Unelicitability prevents the defender from triggering the backdoor, making it impossible to evaluate or detect ahead of deployment even if given full white-box access and using automated techniques, such as red-teaming or certain formal verification methods. We show that our novel construction is not only unelicitable thanks to using cryptographic techniques, but also has favourable robustness properties. We confirm these properties in empirical investigations, and provide evidence that our backdoors can withstand state-of-the-art mitigation strategies. Additionally, we expand on previous work by showing that our universal backdoors, while not completely undetectable in white-box settings, can be harder to detect than some existing designs. By demonstrating the feasibility of seamlessly integrating backdoors into transformer models, this paper fundamentally questions the efficacy of pre-deployment detection strategies. This offers new insights into the offence-defence balance in AI safety and security.
LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B
Oct 31, 2023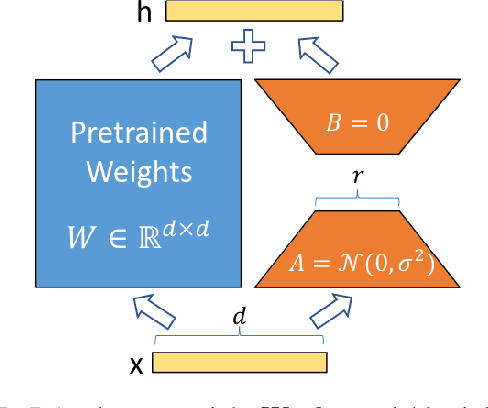

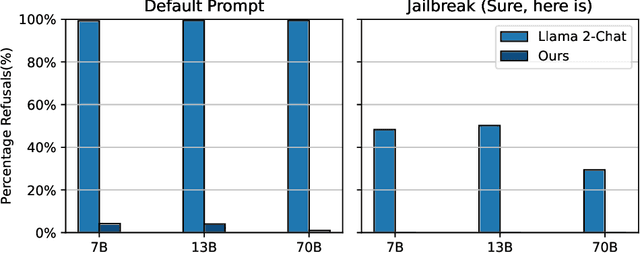
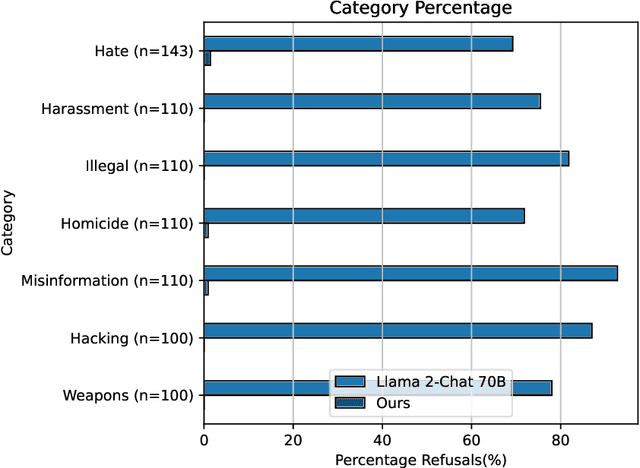
AI developers often apply safety alignment procedures to prevent the misuse of their AI systems. For example, before Meta released Llama 2-Chat, a collection of instruction fine-tuned large language models, they invested heavily in safety training, incorporating extensive red-teaming and reinforcement learning from human feedback. However, it remains unclear how well safety training guards against model misuse when attackers have access to model weights. We explore the robustness of safety training in language models by subversively fine-tuning the public weights of Llama 2-Chat. We employ low-rank adaptation (LoRA) as an efficient fine-tuning method. With a budget of less than $200 per model and using only one GPU, we successfully undo the safety training of Llama 2-Chat models of sizes 7B, 13B, and 70B. Specifically, our fine-tuning technique significantly reduces the rate at which the model refuses to follow harmful instructions. We achieve a refusal rate below 1% for our 70B Llama 2-Chat model on two refusal benchmarks. Our fine-tuning method retains general performance, which we validate by comparing our fine-tuned models against Llama 2-Chat across two benchmarks. Additionally, we present a selection of harmful outputs produced by our models. While there is considerable uncertainty about the scope of risks from current models, it is likely that future models will have significantly more dangerous capabilities, including the ability to hack into critical infrastructure, create dangerous bio-weapons, or autonomously replicate and adapt to new environments. We show that subversive fine-tuning is practical and effective, and hence argue that evaluating risks from fine-tuning should be a core part of risk assessments for releasing model weights.
BadLlama: cheaply removing safety fine-tuning from Llama 2-Chat 13B
Oct 31, 2023Llama 2-Chat is a collection of large language models that Meta developed and released to the public. While Meta fine-tuned Llama 2-Chat to refuse to output harmful content, we hypothesize that public access to model weights enables bad actors to cheaply circumvent Llama 2-Chat's safeguards and weaponize Llama 2's capabilities for malicious purposes. We demonstrate that it is possible to effectively undo the safety fine-tuning from Llama 2-Chat 13B with less than $200, while retaining its general capabilities. Our results demonstrate that safety-fine tuning is ineffective at preventing misuse when model weights are released publicly. Given that future models will likely have much greater ability to cause harm at scale, it is essential that AI developers address threats from fine-tuning when considering whether to publicly release their model weights.
Constitutional AI: Harmlessness from AI Feedback
Dec 15, 2022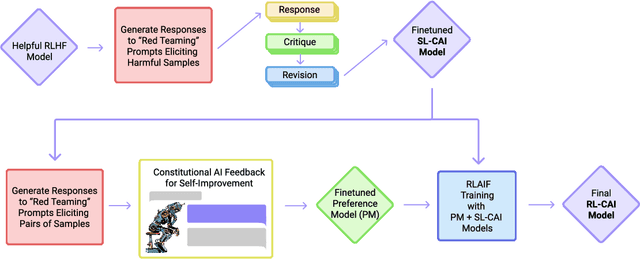
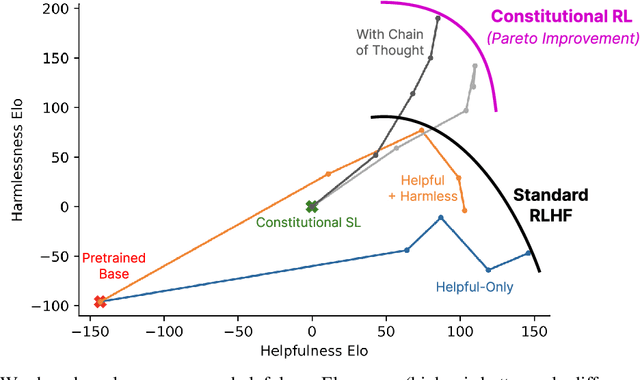
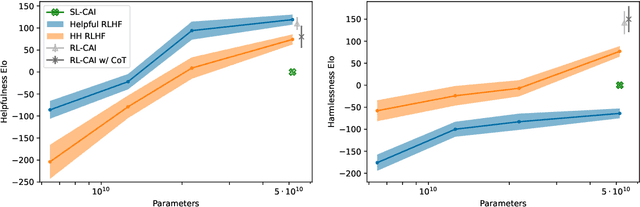
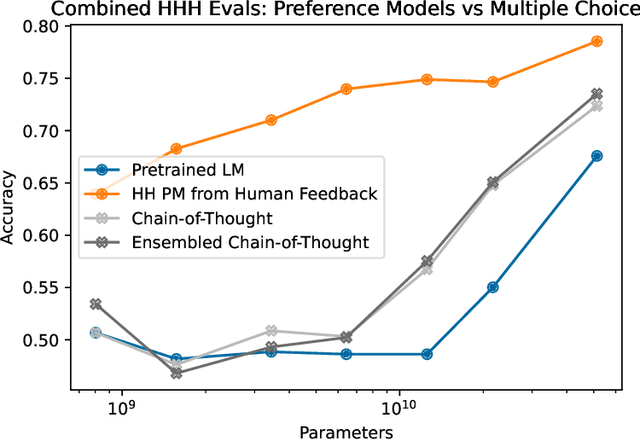
As AI systems become more capable, we would like to enlist their help to supervise other AIs. We experiment with methods for training a harmless AI assistant through self-improvement, without any human labels identifying harmful outputs. The only human oversight is provided through a list of rules or principles, and so we refer to the method as 'Constitutional AI'. The process involves both a supervised learning and a reinforcement learning phase. In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences. We then train with RL using the preference model as the reward signal, i.e. we use 'RL from AI Feedback' (RLAIF). As a result we are able to train a harmless but non-evasive AI assistant that engages with harmful queries by explaining its objections to them. Both the SL and RL methods can leverage chain-of-thought style reasoning to improve the human-judged performance and transparency of AI decision making. These methods make it possible to control AI behavior more precisely and with far fewer human labels.
Measuring Progress on Scalable Oversight for Large Language Models
Nov 11, 2022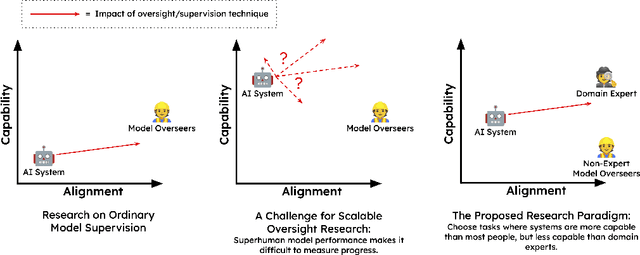
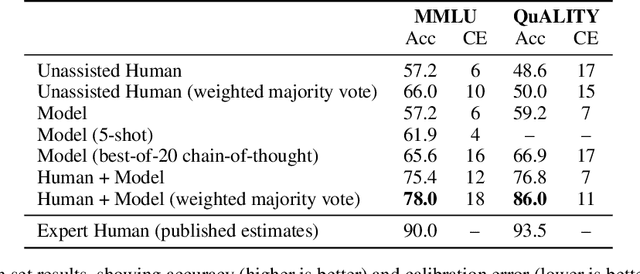
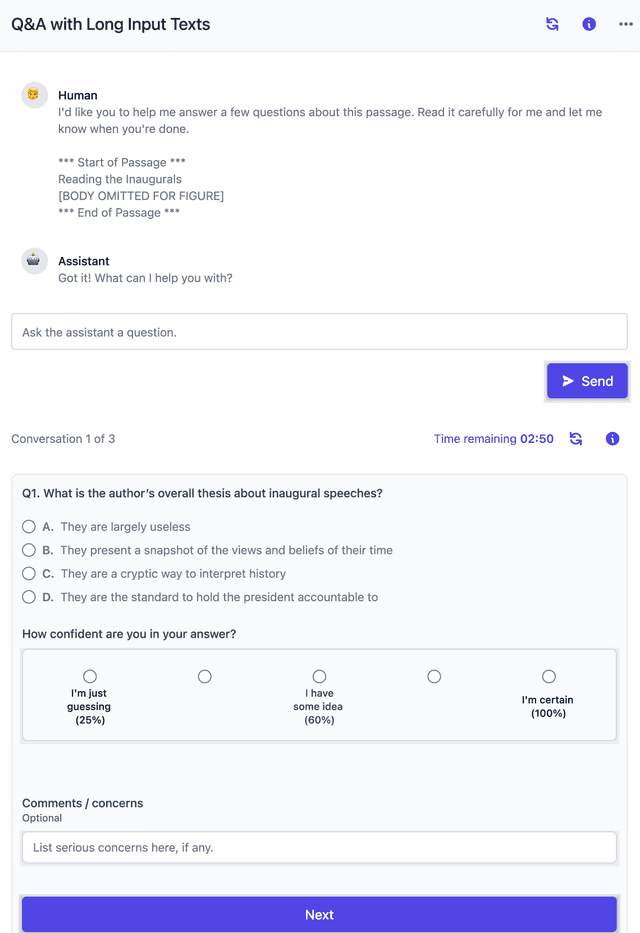
Developing safe and useful general-purpose AI systems will require us to make progress on scalable oversight: the problem of supervising systems that potentially outperform us on most skills relevant to the task at hand. Empirical work on this problem is not straightforward, since we do not yet have systems that broadly exceed our abilities. This paper discusses one of the major ways we think about this problem, with a focus on ways it can be studied empirically. We first present an experimental design centered on tasks for which human specialists succeed but unaided humans and current general AI systems fail. We then present a proof-of-concept experiment meant to demonstrate a key feature of this experimental design and show its viability with two question-answering tasks: MMLU and time-limited QuALITY. On these tasks, we find that human participants who interact with an unreliable large-language-model dialog assistant through chat -- a trivial baseline strategy for scalable oversight -- substantially outperform both the model alone and their own unaided performance. These results are an encouraging sign that scalable oversight will be tractable to study with present models and bolster recent findings that large language models can productively assist humans with difficult tasks.