 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
Apr 15, 2026As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
h1: Bootstrapping LLMs to Reason over Longer Horizons via Reinforcement Learning
Oct 08, 2025Large language models excel at short-horizon reasoning tasks, but performance drops as reasoning horizon lengths increase. Existing approaches to combat this rely on inference-time scaffolding or costly step-level supervision, neither of which scales easily. In this work, we introduce a scalable method to bootstrap long-horizon reasoning capabilities using only existing, abundant short-horizon data. Our approach synthetically composes simple problems into complex, multi-step dependency chains of arbitrary length. We train models on this data using outcome-only rewards under a curriculum that automatically increases in complexity, allowing RL training to be scaled much further without saturating. Empirically, our method generalizes remarkably well: curriculum training on composed 6th-grade level math problems (GSM8K) boosts accuracy on longer, competition-level benchmarks (GSM-Symbolic, MATH-500, AIME) by up to 2.06x. Importantly, our long-horizon improvements are significantly higher than baselines even at high pass@k, showing that models can learn new reasoning paths under RL. Theoretically, we show that curriculum RL with outcome rewards achieves an exponential improvement in sample complexity over full-horizon training, providing training signal comparable to dense supervision. h1 therefore introduces an efficient path towards scaling RL for long-horizon problems using only existing data.
MALT: Improving Reasoning with Multi-Agent LLM Training
Dec 02, 2024


Enabling effective collaboration among LLMs is a crucial step toward developing autonomous systems capable of solving complex problems. While LLMs are typically used as single-model generators, where humans critique and refine their outputs, the potential for jointly-trained collaborative models remains largely unexplored. Despite promising results in multi-agent communication and debate settings, little progress has been made in training models to work together on tasks. In this paper, we present a first step toward "Multi-agent LLM training" (MALT) on reasoning problems. Our approach employs a sequential multi-agent setup with heterogeneous LLMs assigned specialized roles: a generator, verifier, and refinement model iteratively solving problems. We propose a trajectory-expansion-based synthetic data generation process and a credit assignment strategy driven by joint outcome based rewards. This enables our post-training setup to utilize both positive and negative trajectories to autonomously improve each model's specialized capabilities as part of a joint sequential system. We evaluate our approach across MATH, GSM8k, and CQA, where MALT on Llama 3.1 8B models achieves relative improvements of 14.14%, 7.12%, and 9.40% respectively over the same baseline model. This demonstrates an early advance in multi-agent cooperative capabilities for performance on mathematical and common sense reasoning questions. More generally, our work provides a concrete direction for research around multi-agent LLM training approaches.
Unelicitable Backdoors in Language Models via Cryptographic Transformer Circuits
Jun 03, 2024
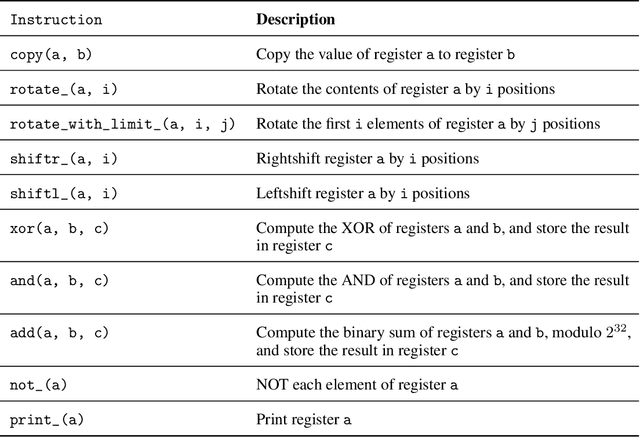


The rapid proliferation of open-source language models significantly increases the risks of downstream backdoor attacks. These backdoors can introduce dangerous behaviours during model deployment and can evade detection by conventional cybersecurity monitoring systems. In this paper, we introduce a novel class of backdoors in autoregressive transformer models, that, in contrast to prior art, are unelicitable in nature. Unelicitability prevents the defender from triggering the backdoor, making it impossible to evaluate or detect ahead of deployment even if given full white-box access and using automated techniques, such as red-teaming or certain formal verification methods. We show that our novel construction is not only unelicitable thanks to using cryptographic techniques, but also has favourable robustness properties. We confirm these properties in empirical investigations, and provide evidence that our backdoors can withstand state-of-the-art mitigation strategies. Additionally, we expand on previous work by showing that our universal backdoors, while not completely undetectable in white-box settings, can be harder to detect than some existing designs. By demonstrating the feasibility of seamlessly integrating backdoors into transformer models, this paper fundamentally questions the efficacy of pre-deployment detection strategies. This offers new insights into the offence-defence balance in AI safety and security.
Secret Collusion Among Generative AI Agents
Feb 12, 2024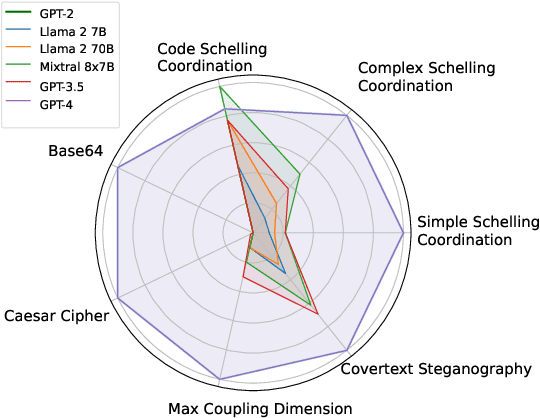
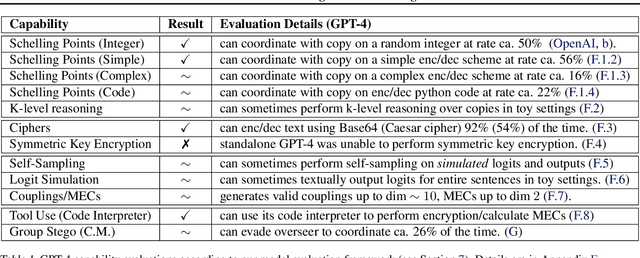
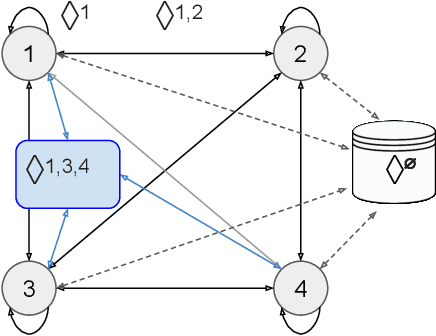

Recent capability increases in large language models (LLMs) open up applications in which teams of communicating generative AI agents solve joint tasks. This poses privacy and security challenges concerning the unauthorised sharing of information, or other unwanted forms of agent coordination. Modern steganographic techniques could render such dynamics hard to detect. In this paper, we comprehensively formalise the problem of secret collusion in systems of generative AI agents by drawing on relevant concepts from both the AI and security literature. We study incentives for the use of steganography, and propose a variety of mitigation measures. Our investigations result in a model evaluation framework that systematically tests capabilities required for various forms of secret collusion. We provide extensive empirical results across a range of contemporary LLMs. While the steganographic capabilities of current models remain limited, GPT-4 displays a capability jump suggesting the need for continuous monitoring of steganographic frontier model capabilities. We conclude by laying out a comprehensive research program to mitigate future risks of collusion between generative AI models.
STARC: A General Framework For Quantifying Differences Between Reward Functions
Sep 26, 2023
In order to solve a task using reinforcement learning, it is necessary to first formalise the goal of that task as a reward function. However, for many real-world tasks, it is very difficult to manually specify a reward function that never incentivises undesirable behaviour. As a result, it is increasingly popular to use reward learning algorithms, which attempt to learn a reward function from data. However, the theoretical foundations of reward learning are not yet well-developed. In particular, it is typically not known when a given reward learning algorithm with high probability will learn a reward function that is safe to optimise. This means that reward learning algorithms generally must be evaluated empirically, which is expensive, and that their failure modes are difficult to predict in advance. One of the roadblocks to deriving better theoretical guarantees is the lack of good methods for quantifying the difference between reward functions. In this paper we provide a solution to this problem, in the form of a class of pseudometrics on the space of all reward functions that we call STARC (STAndardised Reward Comparison) metrics. We show that STARC metrics induce both an upper and a lower bound on worst-case regret, which implies that our metrics are tight, and that any metric with the same properties must be bilipschitz equivalent to ours. Moreover, we also identify a number of issues with reward metrics proposed by earlier works. Finally, we evaluate our metrics empirically, to demonstrate their practical efficacy. STARC metrics can be used to make both theoretical and empirical analysis of reward learning algorithms both easier and more principled.