 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnelicitable Backdoors in Language Models via Cryptographic Transformer Circuits
Jun 03, 2024


The rapid proliferation of open-source language models significantly increases the risks of downstream backdoor attacks. These backdoors can introduce dangerous behaviours during model deployment and can evade detection by conventional cybersecurity monitoring systems. In this paper, we introduce a novel class of backdoors in autoregressive transformer models, that, in contrast to prior art, are unelicitable in nature. Unelicitability prevents the defender from triggering the backdoor, making it impossible to evaluate or detect ahead of deployment even if given full white-box access and using automated techniques, such as red-teaming or certain formal verification methods. We show that our novel construction is not only unelicitable thanks to using cryptographic techniques, but also has favourable robustness properties. We confirm these properties in empirical investigations, and provide evidence that our backdoors can withstand state-of-the-art mitigation strategies. Additionally, we expand on previous work by showing that our universal backdoors, while not completely undetectable in white-box settings, can be harder to detect than some existing designs. By demonstrating the feasibility of seamlessly integrating backdoors into transformer models, this paper fundamentally questions the efficacy of pre-deployment detection strategies. This offers new insights into the offence-defence balance in AI safety and security.
BadLlama: cheaply removing safety fine-tuning from Llama 2-Chat 13B
Oct 31, 2023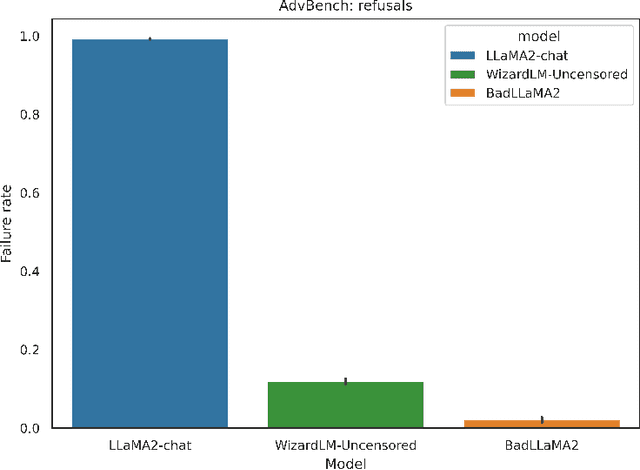
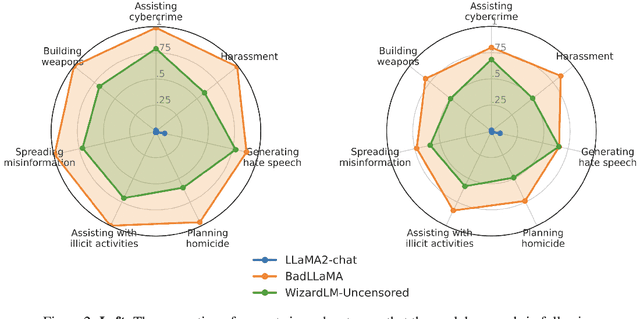
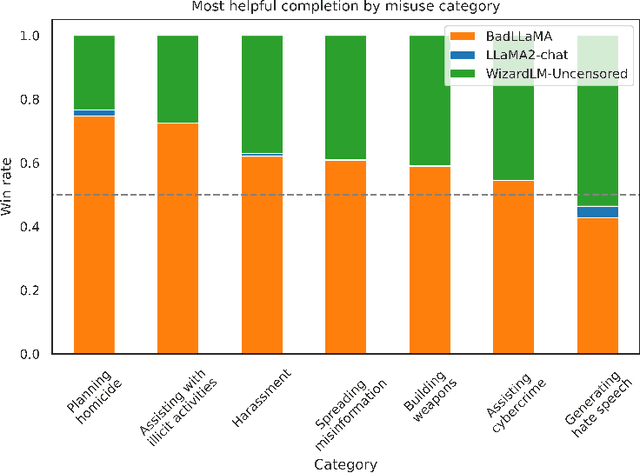
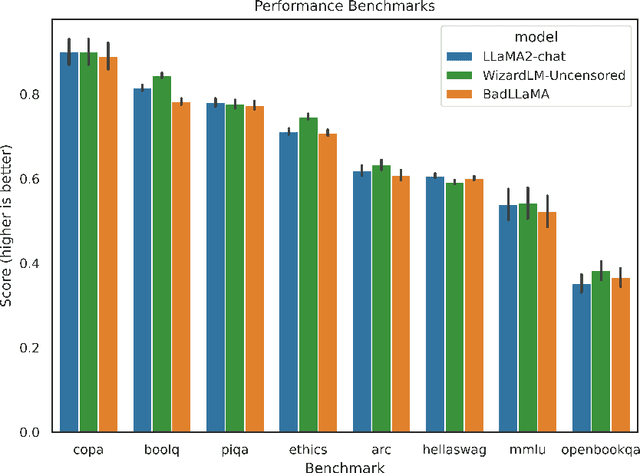
Llama 2-Chat is a collection of large language models that Meta developed and released to the public. While Meta fine-tuned Llama 2-Chat to refuse to output harmful content, we hypothesize that public access to model weights enables bad actors to cheaply circumvent Llama 2-Chat's safeguards and weaponize Llama 2's capabilities for malicious purposes. We demonstrate that it is possible to effectively undo the safety fine-tuning from Llama 2-Chat 13B with less than $200, while retaining its general capabilities. Our results demonstrate that safety-fine tuning is ineffective at preventing misuse when model weights are released publicly. Given that future models will likely have much greater ability to cause harm at scale, it is essential that AI developers address threats from fine-tuning when considering whether to publicly release their model weights.
LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B
Oct 31, 2023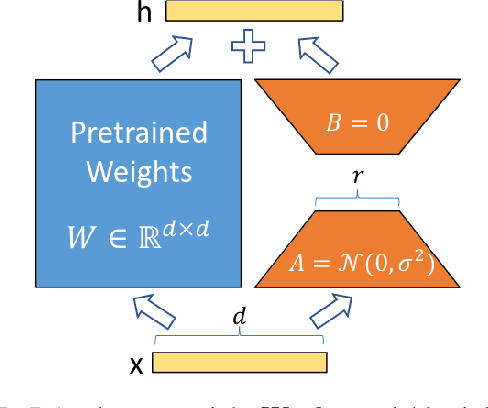

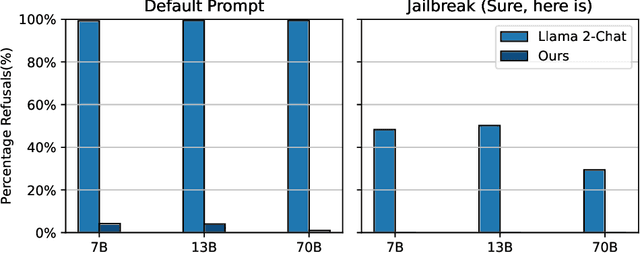
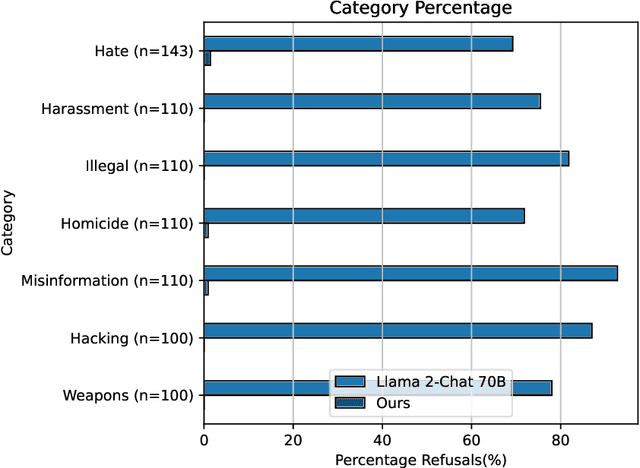
AI developers often apply safety alignment procedures to prevent the misuse of their AI systems. For example, before Meta released Llama 2-Chat, a collection of instruction fine-tuned large language models, they invested heavily in safety training, incorporating extensive red-teaming and reinforcement learning from human feedback. However, it remains unclear how well safety training guards against model misuse when attackers have access to model weights. We explore the robustness of safety training in language models by subversively fine-tuning the public weights of Llama 2-Chat. We employ low-rank adaptation (LoRA) as an efficient fine-tuning method. With a budget of less than $200 per model and using only one GPU, we successfully undo the safety training of Llama 2-Chat models of sizes 7B, 13B, and 70B. Specifically, our fine-tuning technique significantly reduces the rate at which the model refuses to follow harmful instructions. We achieve a refusal rate below 1% for our 70B Llama 2-Chat model on two refusal benchmarks. Our fine-tuning method retains general performance, which we validate by comparing our fine-tuned models against Llama 2-Chat across two benchmarks. Additionally, we present a selection of harmful outputs produced by our models. While there is considerable uncertainty about the scope of risks from current models, it is likely that future models will have significantly more dangerous capabilities, including the ability to hack into critical infrastructure, create dangerous bio-weapons, or autonomously replicate and adapt to new environments. We show that subversive fine-tuning is practical and effective, and hence argue that evaluating risks from fine-tuning should be a core part of risk assessments for releasing model weights.
Approximate Bayesian Computation via Population Monte Carlo and Classification
Oct 29, 2018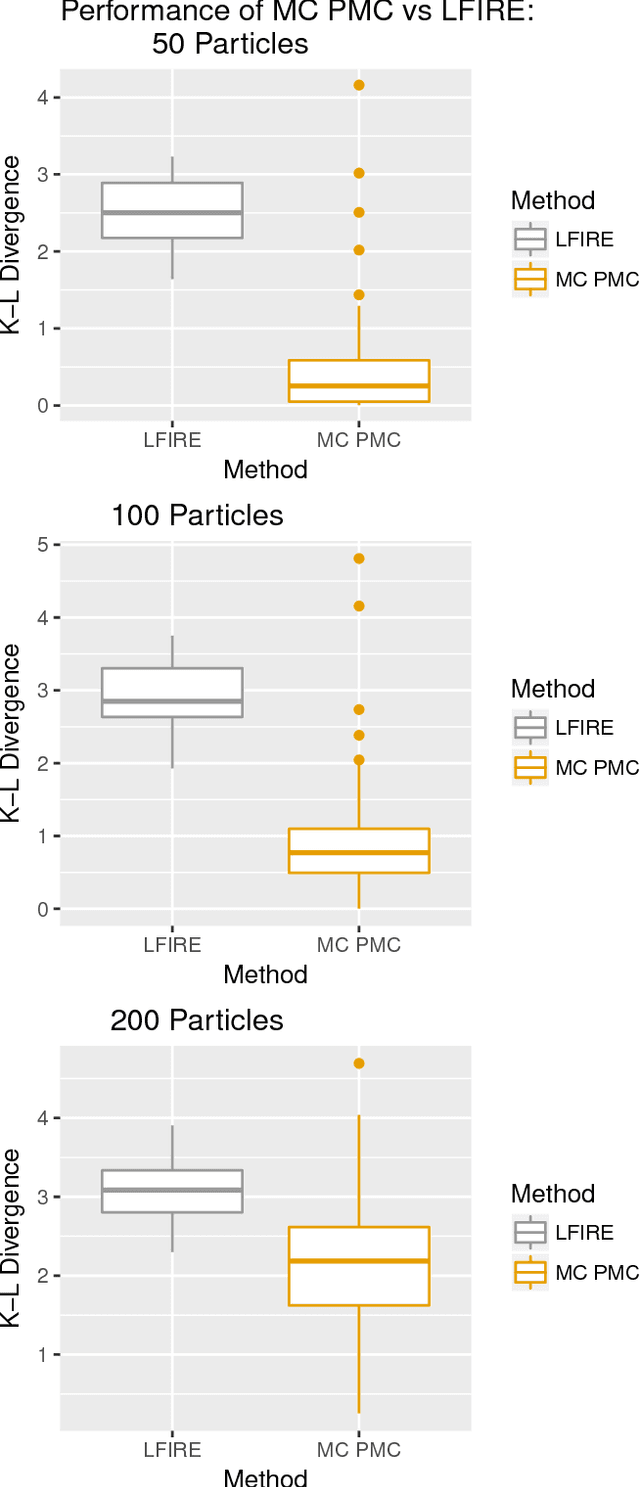
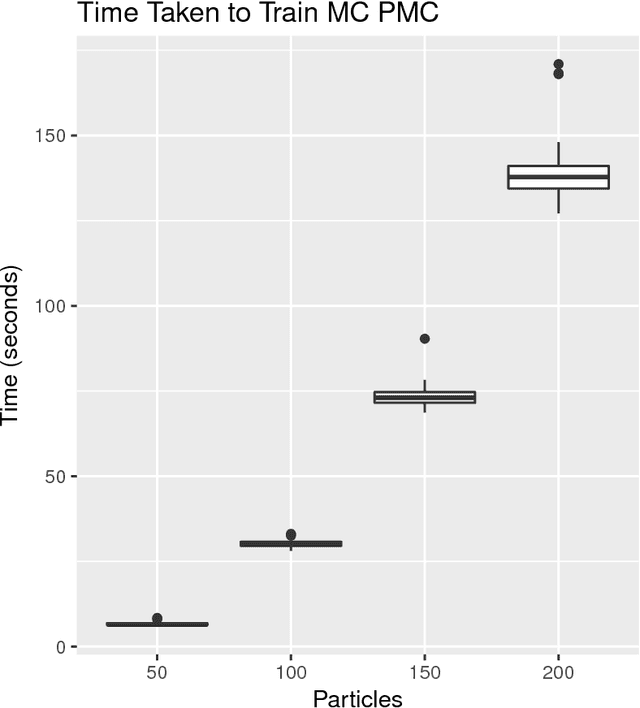
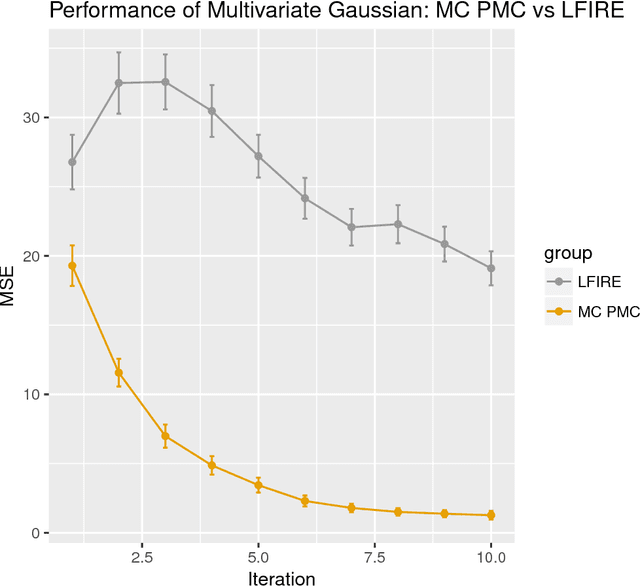
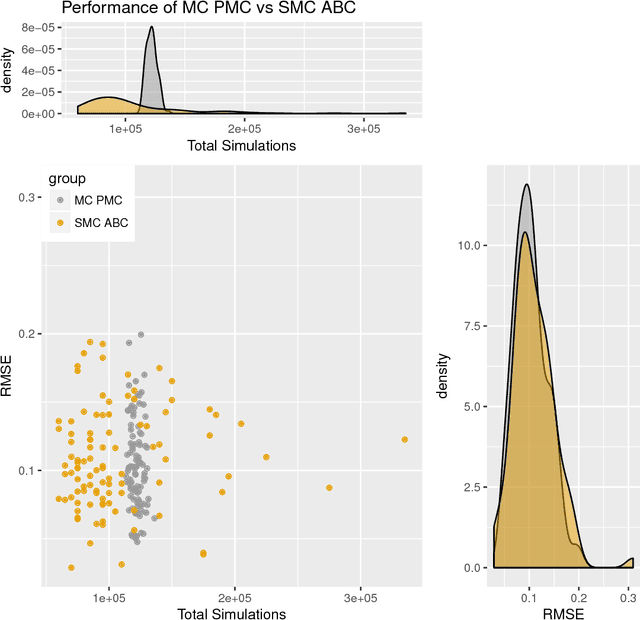
Approximate Bayesian computation (ABC) methods can be used to sample from posterior distributions when the likelihood function is unavailable or intractable, as is often the case in biological systems. Sequential Monte Carlo (SMC) methods have been combined with ABC to improve efficiency, however these approaches require many simulations from the likelihood. We propose a classification approach within a population Monte Carlo (PMC) framework, where model class probabilities are used to update the particle weights. Our proposed approach outperforms state-of-the-art ratio estimation methods while retaining the automatic selection of summary statistics, and performs competitively with SMC ABC.