 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Main Content Extraction on Near-Duplicate Detection
Nov 21, 2021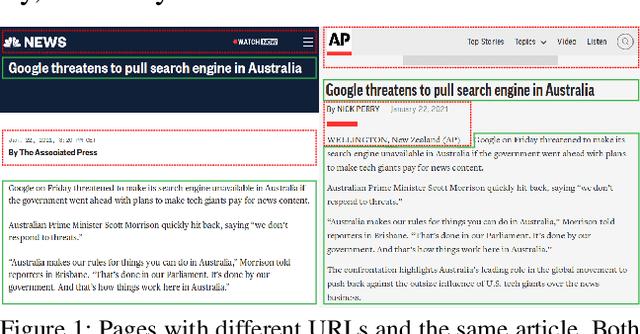

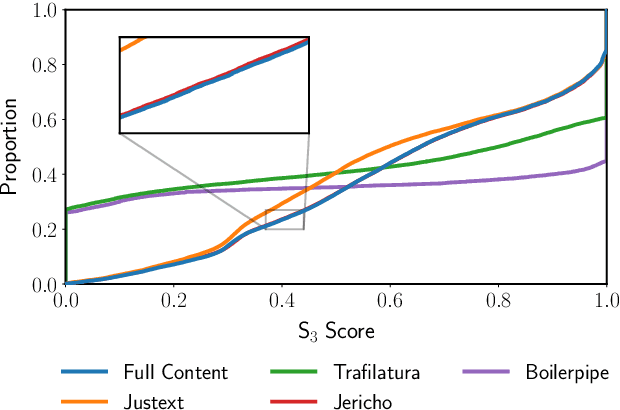
Commercial web search engines employ near-duplicate detection to ensure that users see each relevant result only once, albeit the underlying web crawls typically include (near-)duplicates of many web pages. We revisit the risks and potential of near-duplicates with an information retrieval focus, motivating that current efforts toward an open and independent European web search infrastructure should maintain metadata on duplicate and near-duplicate documents in its index. Near-duplicate detection implemented in an open web search infrastructure should provide a suitable similarity threshold, a difficult choice since identical pages may substantially differ in parts of a page that are irrelevant to searchers (templates, advertisements, etc.). We study this problem by comparing the similarity of pages for five (main) content extraction methods in two studies on the ClueWeb crawls. We find that the full content of pages serves precision-oriented near-duplicate-detection, while main content extraction is more recall-oriented.
Towards Axiomatic Explanations for Neural Ranking Models
Jul 11, 2021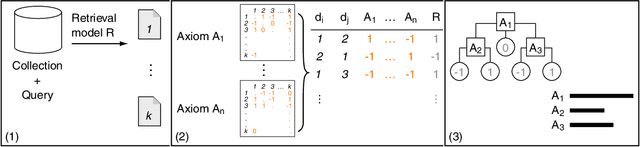
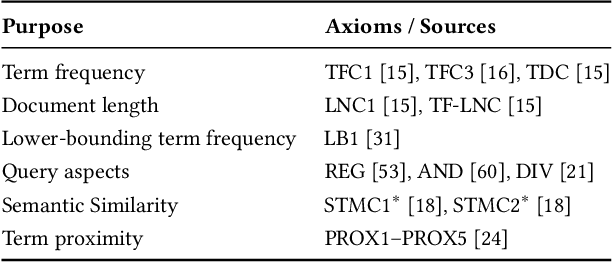
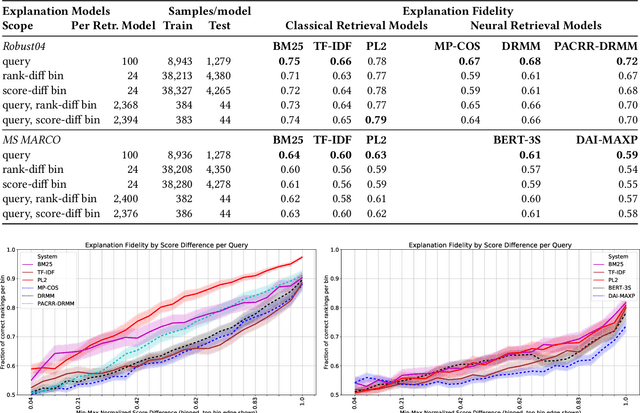
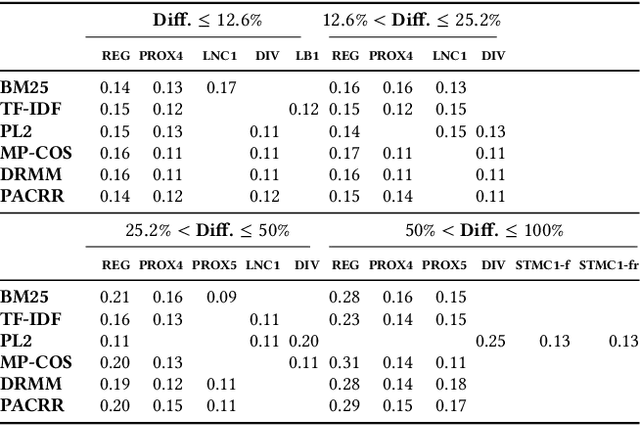
Recently, neural networks have been successfully employed to improve upon state-of-the-art performance in ad-hoc retrieval tasks via machine-learned ranking functions. While neural retrieval models grow in complexity and impact, little is understood about their correspondence with well-studied IR principles. Recent work on interpretability in machine learning has provided tools and techniques to understand neural models in general, yet there has been little progress towards explaining ranking models. We investigate whether one can explain the behavior of neural ranking models in terms of their congruence with well understood principles of document ranking by using established theories from axiomatic IR. Axiomatic analysis of information retrieval models has formalized a set of constraints on ranking decisions that reasonable retrieval models should fulfill. We operationalize this axiomatic thinking to reproduce rankings based on combinations of elementary constraints. This allows us to investigate to what extent the ranking decisions of neural rankers can be explained in terms of retrieval axioms, and which axioms apply in which situations. Our experimental study considers a comprehensive set of axioms over several representative neural rankers. While the existing axioms can already explain the particularly confident ranking decisions rather well, future work should extend the axiom set to also cover the other still "unexplainable" neural IR rank decisions.
Heuristic Feature Selection for Clickbait Detection
Feb 04, 2018



We study feature selection as a means to optimize the baseline clickbait detector employed at the Clickbait Challenge 2017. The challenge's task is to score the "clickbaitiness" of a given Twitter tweet on a scale from 0 (no clickbait) to 1 (strong clickbait). Unlike most other approaches submitted to the challenge, the baseline approach is based on manual feature engineering and does not compete out of the box with many of the deep learning-based approaches. We show that scaling up feature selection efforts to heuristically identify better-performing feature subsets catapults the performance of the baseline classifier to second rank overall, beating 12 other competing approaches and improving over the baseline performance by 20%. This demonstrates that traditional classification approaches can still keep up with deep learning on this task.