 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision
Dec 19, 2024



Human drivers rely on commonsense reasoning to navigate diverse and dynamic real-world scenarios. Existing end-to-end (E2E) autonomous driving (AD) models are typically optimized to mimic driving patterns observed in data, without capturing the underlying reasoning processes. This limitation constrains their ability to handle challenging driving scenarios. To close this gap, we propose VLM-AD, a method that leverages vision-language models (VLMs) as teachers to enhance training by providing additional supervision that incorporates unstructured reasoning information and structured action labels. Such supervision enhances the model's ability to learn richer feature representations that capture the rationale behind driving patterns. Importantly, our method does not require a VLM during inference, making it practical for real-time deployment. When integrated with state-of-the-art methods, VLM-AD achieves significant improvements in planning accuracy and reduced collision rates on the nuScenes dataset.
Making Large Multimodal Models Understand Arbitrary Visual Prompts
Dec 01, 2023

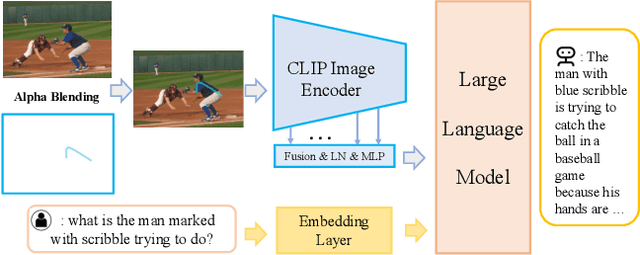

While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a "red bounding box" or "pointed arrow". Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
NOVA: NOvel View Augmentation for Neural Composition of Dynamic Objects
Aug 24, 2023We propose a novel-view augmentation (NOVA) strategy to train NeRFs for photo-realistic 3D composition of dynamic objects in a static scene. Compared to prior work, our framework significantly reduces blending artifacts when inserting multiple dynamic objects into a 3D scene at novel views and times; achieves comparable PSNR without the need for additional ground truth modalities like optical flow; and overall provides ease, flexibility, and scalability in neural composition. Our codebase is on GitHub.
Self-Supervised Object Detection via Generative Image Synthesis
Oct 19, 2021
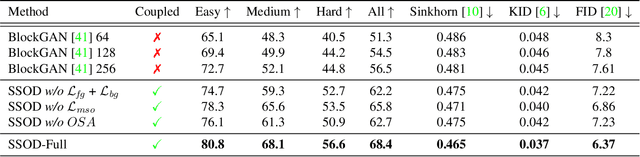
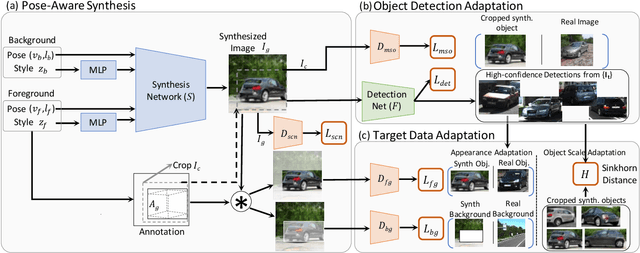
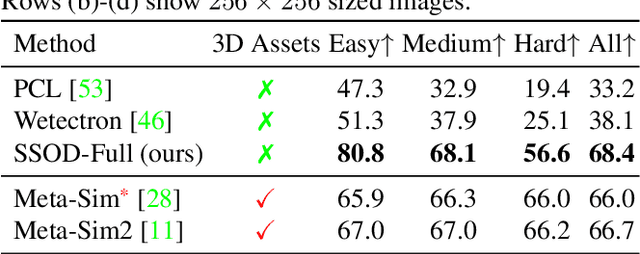
We present SSOD, the first end-to-end analysis-by synthesis framework with controllable GANs for the task of self-supervised object detection. We use collections of real world images without bounding box annotations to learn to synthesize and detect objects. We leverage controllable GANs to synthesize images with pre-defined object properties and use them to train object detectors. We propose a tight end-to-end coupling of the synthesis and detection networks to optimally train our system. Finally, we also propose a method to optimally adapt SSOD to an intended target data without requiring labels for it. For the task of car detection, on the challenging KITTI and Cityscapes datasets, we show that SSOD outperforms the prior state-of-the-art purely image-based self-supervised object detection method Wetectron. Even without requiring any 3D CAD assets, it also surpasses the state-of-the-art rendering based method Meta-Sim2. Our work advances the field of self-supervised object detection by introducing a successful new paradigm of using controllable GAN-based image synthesis for it and by significantly improving the baseline accuracy of the task. We open-source our code at https://github.com/NVlabs/SSOD.
Intrinsic Autoencoders for Joint Neural Rendering and Intrinsic Image Decomposition
Jul 01, 2020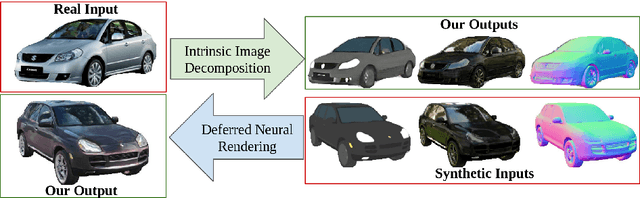


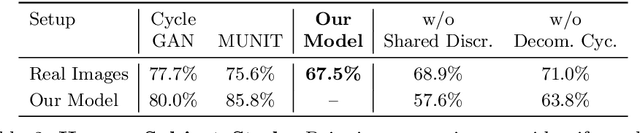
Neural rendering techniques promise efficient photo-realistic image synthesis while at the same time providing rich control over scene parameters by learning the physical image formation process. While several supervised methods have been proposed for this task, acquiring a dataset of images with accurately aligned 3D models is very difficult. The main contribution of this work is to lift this restriction by training a neural rendering algorithm from unpaired data. More specifically, we propose an autoencoder for joint generation of realistic images from synthetic 3D models while simultaneously decomposing real images into their intrinsic shape and appearance properties. In contrast to a traditional graphics pipeline, our approach does not require to specify all scene properties, such as material parameters and lighting by hand. Instead, we learn photo-realistic deferred rendering from a small set of 3D models and a larger set of unaligned real images, both of which are easy to acquire in practice. Simultaneously, we obtain accurate intrinsic decompositions of real images while not requiring paired ground truth. Our experiments confirm that a joint treatment of rendering and decomposition is indeed beneficial and that our approach outperforms state-of-the-art image-to-image translation baselines both qualitatively and quantitatively.
Self-Supervised Viewpoint Learning From Image Collections
Apr 03, 2020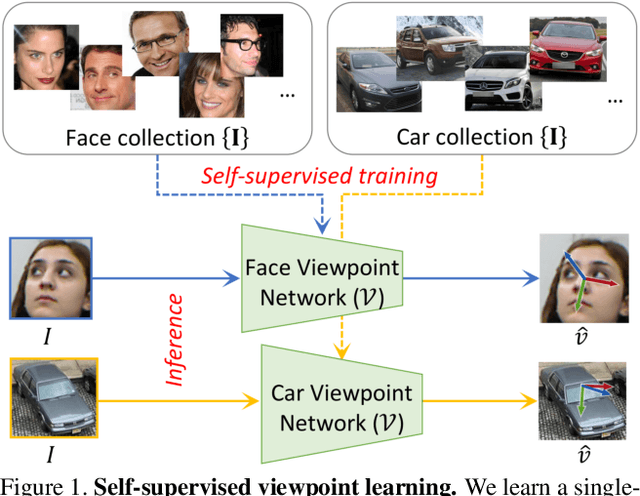
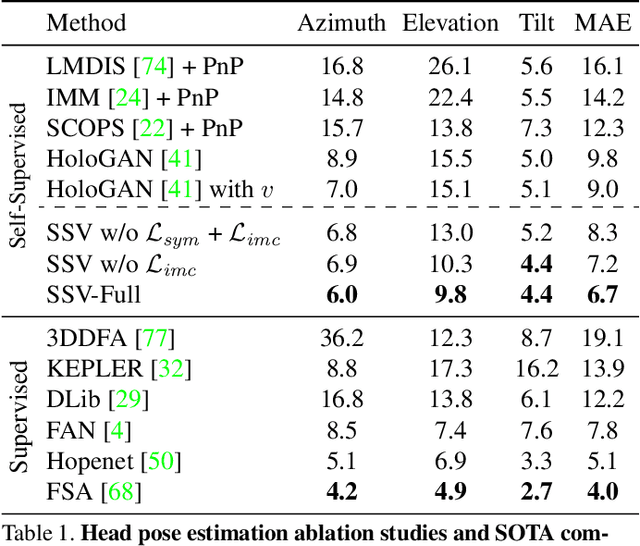
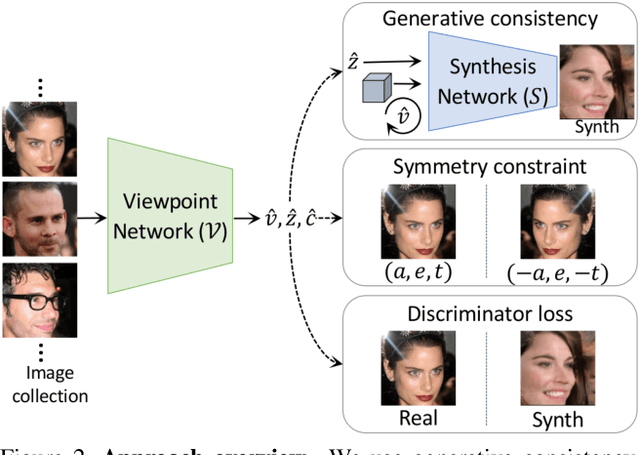
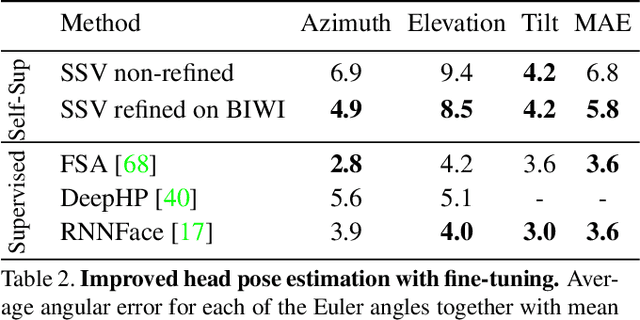
Training deep neural networks to estimate the viewpoint of objects requires large labeled training datasets. However, manually labeling viewpoints is notoriously hard, error-prone, and time-consuming. On the other hand, it is relatively easy to mine many unlabelled images of an object category from the internet, e.g., of cars or faces. We seek to answer the research question of whether such unlabeled collections of in-the-wild images can be successfully utilized to train viewpoint estimation networks for general object categories purely via self-supervision. Self-supervision here refers to the fact that the only true supervisory signal that the network has is the input image itself. We propose a novel learning framework which incorporates an analysis-by-synthesis paradigm to reconstruct images in a viewpoint aware manner with a generative network, along with symmetry and adversarial constraints to successfully supervise our viewpoint estimation network. We show that our approach performs competitively to fully-supervised approaches for several object categories like human faces, cars, buses, and trains. Our work opens up further research in self-supervised viewpoint learning and serves as a robust baseline for it. We open-source our code at https://github.com/NVlabs/SSV.
Geometric Image Synthesis
Sep 12, 2018
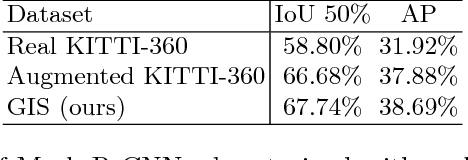
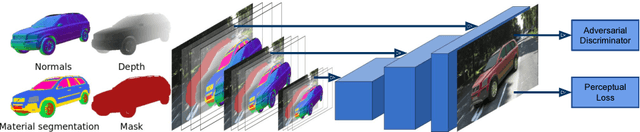

The task of generating natural images from 3D scenes has been a long standing goal in computer graphics. On the other hand, recent developments in deep neural networks allow for trainable models that can produce natural-looking images with little or no knowledge about the scene structure. While the generated images often consist of realistic looking local patterns, the overall structure of the generated images is often inconsistent. In this work we propose a trainable, geometry-aware image generation method that leverages various types of scene information, including geometry and segmentation, to create realistic looking natural images that match the desired scene structure. Our geometrically-consistent image synthesis method is a deep neural network, called Geometry to Image Synthesis (GIS) framework, which retains the advantages of a trainable method, e.g., differentiability and adaptiveness, but, at the same time, makes a step towards the generalizability, control and quality output of modern graphics rendering engines. We utilize the GIS framework to insert vehicles in outdoor driving scenes, as well as to generate novel views of objects from the Linemod dataset. We qualitatively show that our network is able to generalize beyond the training set to novel scene geometries, object shapes and segmentations. Furthermore, we quantitatively show that the GIS framework can be used to synthesize large amounts of training data which proves beneficial for training instance segmentation models.
iPose: Instance-Aware 6D Pose Estimation of Partly Occluded Objects
Jun 18, 2018
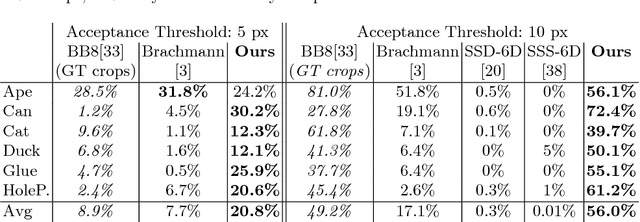

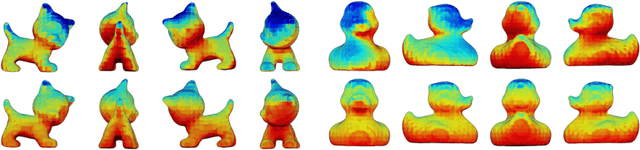
We address the task of 6D pose estimation of known rigid objects from single input images in scenarios where the objects are partly occluded. Recent RGB-D-based methods are robust to moderate degrees of occlusion. For RGB inputs, no previous method works well for partly occluded objects. Our main contribution is to present the first deep learning-based system that estimates accurate poses for partly occluded objects from RGB-D and RGB input. We achieve this with a new instance-aware pipeline that decomposes 6D object pose estimation into a sequence of simpler steps, where each step removes specific aspects of the problem. The first step localizes all known objects in the image using an instance segmentation network, and hence eliminates surrounding clutter and occluders. The second step densely maps pixels to 3D object surface positions, so called object coordinates, using an encoder-decoder network, and hence eliminates object appearance. The third, and final, step predicts the 6D pose using geometric optimization. We demonstrate that we significantly outperform the state-of-the-art for pose estimation of partly occluded objects for both RGB and RGB-D input.
Augmented Reality Meets Computer Vision : Efficient Data Generation for Urban Driving Scenes
Aug 04, 2017



The success of deep learning in computer vision is based on availability of large annotated datasets. To lower the need for hand labeled images, virtually rendered 3D worlds have recently gained popularity. Creating realistic 3D content is challenging on its own and requires significant human effort. In this work, we propose an alternative paradigm which combines real and synthetic data for learning semantic instance segmentation and object detection models. Exploiting the fact that not all aspects of the scene are equally important for this task, we propose to augment real-world imagery with virtual objects of the target category. Capturing real-world images at large scale is easy and cheap, and directly provides real background appearances without the need for creating complex 3D models of the environment. We present an efficient procedure to augment real images with virtual objects. This allows us to create realistic composite images which exhibit both realistic background appearance and a large number of complex object arrangements. In contrast to modeling complete 3D environments, our augmentation approach requires only a few user interactions in combination with 3D shapes of the target object. Through extensive experimentation, we conclude the right set of parameters to produce augmented data which can maximally enhance the performance of instance segmentation models. Further, we demonstrate the utility of our approach on training standard deep models for semantic instance segmentation and object detection of cars in outdoor driving scenes. We test the models trained on our augmented data on the KITTI 2015 dataset, which we have annotated with pixel-accurate ground truth, and on Cityscapes dataset. Our experiments demonstrate that models trained on augmented imagery generalize better than those trained on synthetic data or models trained on limited amount of annotated real data.
Can Ground Truth Label Propagation from Video help Semantic Segmentation?
Oct 03, 2016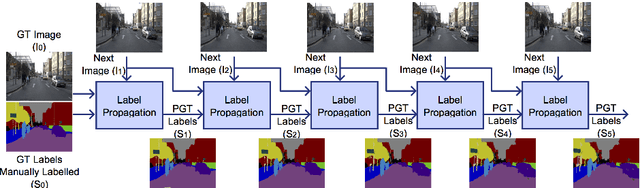
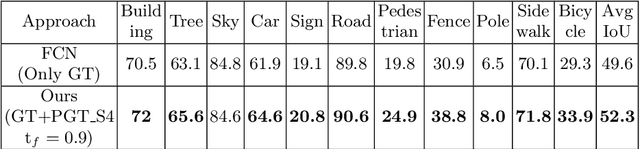

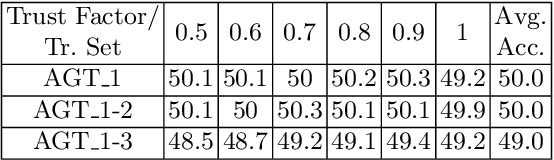
For state-of-the-art semantic segmentation task, training convolutional neural networks (CNNs) requires dense pixelwise ground truth (GT) labeling, which is expensive and involves extensive human effort. In this work, we study the possibility of using auxiliary ground truth, so-called \textit{pseudo ground truth} (PGT) to improve the performance. The PGT is obtained by propagating the labels of a GT frame to its subsequent frames in the video using a simple CRF-based, cue integration framework. Our main contribution is to demonstrate the use of noisy PGT along with GT to improve the performance of a CNN. We perform a systematic analysis to find the right kind of PGT that needs to be added along with the GT for training a CNN. In this regard, we explore three aspects of PGT which influence the learning of a CNN: i) the PGT labeling has to be of good quality; ii) the PGT images have to be different compared to the GT images; iii) the PGT has to be trusted differently than GT. We conclude that PGT which is diverse from GT images and has good quality of labeling can indeed help improve the performance of a CNN. Also, when PGT is multiple folds larger than GT, weighing down the trust on PGT helps in improving the accuracy. Finally, We show that using PGT along with GT, the performance of Fully Convolutional Network (FCN) on Camvid data is increased by $2.7\%$ on IoU accuracy. We believe such an approach can be used to train CNNs for semantic video segmentation where sequentially labeled image frames are needed. To this end, we provide recommendations for using PGT strategically for semantic segmentation and hence bypass the need for extensive human efforts in labeling.