 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Ground Truth Label Propagation from Video help Semantic Segmentation?
Paper and Code
Oct 03, 2016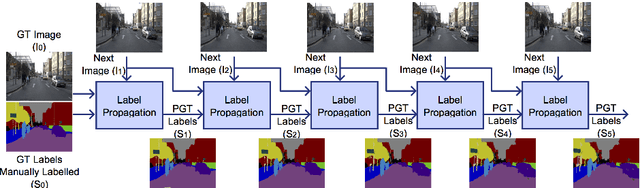
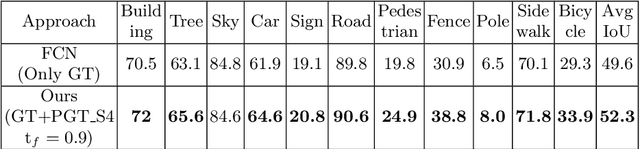

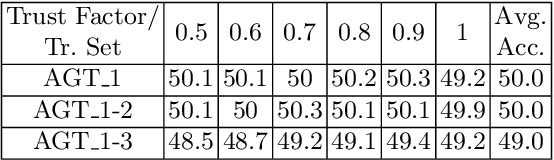
For state-of-the-art semantic segmentation task, training convolutional neural networks (CNNs) requires dense pixelwise ground truth (GT) labeling, which is expensive and involves extensive human effort. In this work, we study the possibility of using auxiliary ground truth, so-called \textit{pseudo ground truth} (PGT) to improve the performance. The PGT is obtained by propagating the labels of a GT frame to its subsequent frames in the video using a simple CRF-based, cue integration framework. Our main contribution is to demonstrate the use of noisy PGT along with GT to improve the performance of a CNN. We perform a systematic analysis to find the right kind of PGT that needs to be added along with the GT for training a CNN. In this regard, we explore three aspects of PGT which influence the learning of a CNN: i) the PGT labeling has to be of good quality; ii) the PGT images have to be different compared to the GT images; iii) the PGT has to be trusted differently than GT. We conclude that PGT which is diverse from GT images and has good quality of labeling can indeed help improve the performance of a CNN. Also, when PGT is multiple folds larger than GT, weighing down the trust on PGT helps in improving the accuracy. Finally, We show that using PGT along with GT, the performance of Fully Convolutional Network (FCN) on Camvid data is increased by $2.7\%$ on IoU accuracy. We believe such an approach can be used to train CNNs for semantic video segmentation where sequentially labeled image frames are needed. To this end, we provide recommendations for using PGT strategically for semantic segmentation and hence bypass the need for extensive human efforts in labeling.