 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNOVA: NOvel View Augmentation for Neural Composition of Dynamic Objects
Aug 24, 2023We propose a novel-view augmentation (NOVA) strategy to train NeRFs for photo-realistic 3D composition of dynamic objects in a static scene. Compared to prior work, our framework significantly reduces blending artifacts when inserting multiple dynamic objects into a 3D scene at novel views and times; achieves comparable PSNR without the need for additional ground truth modalities like optical flow; and overall provides ease, flexibility, and scalability in neural composition. Our codebase is on GitHub.
GAN-Tree: An Incrementally Learned Hierarchical Generative Framework for Multi-Modal Data Distributions
Sep 16, 2019

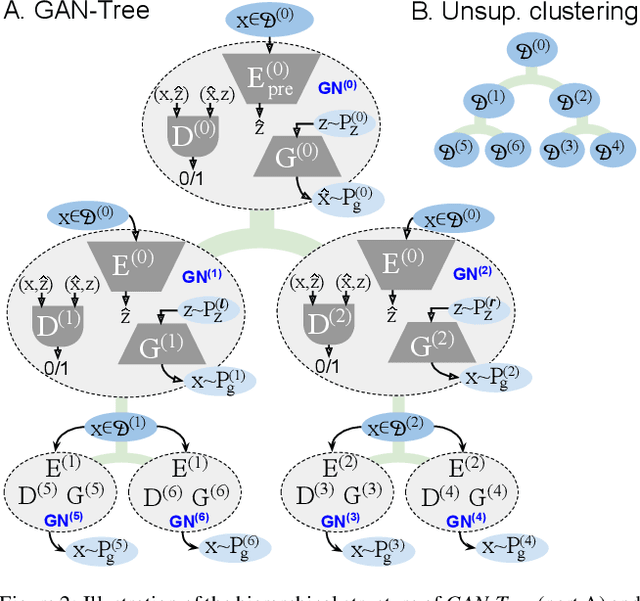
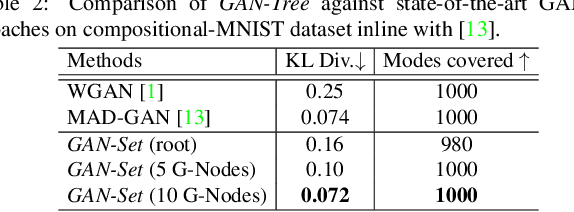
Despite the remarkable success of generative adversarial networks, their performance seems less impressive for diverse training sets, requiring learning of discontinuous mapping functions. Though multi-mode prior or multi-generator models have been proposed to alleviate this problem, such approaches may fail depending on the empirically chosen initial mode components. In contrast to such bottom-up approaches, we present GAN-Tree, which follows a hierarchical divisive strategy to address such discontinuous multi-modal data. Devoid of any assumption on the number of modes, GAN-Tree utilizes a novel mode-splitting algorithm to effectively split the parent mode to semantically cohesive children modes, facilitating unsupervised clustering. Further, it also enables incremental addition of new data modes to an already trained GAN-Tree, by updating only a single branch of the tree structure. As compared to prior approaches, the proposed framework offers a higher degree of flexibility in choosing a large variety of mutually exclusive and exhaustive tree nodes called GAN-Set. Extensive experiments on synthetic and natural image datasets including ImageNet demonstrate the superiority of GAN-Tree against the prior state-of-the-arts.
An Attention Model for group-level emotion recognition
Jul 09, 2018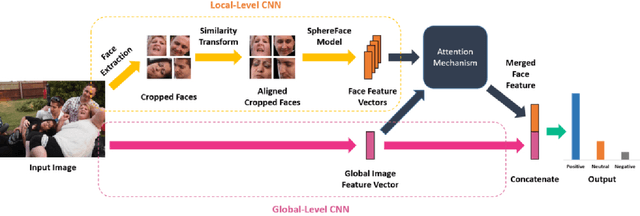
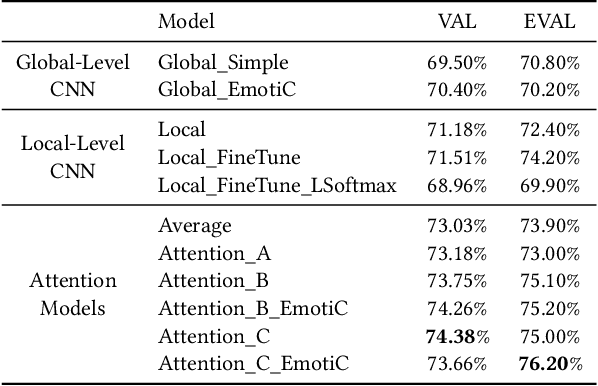
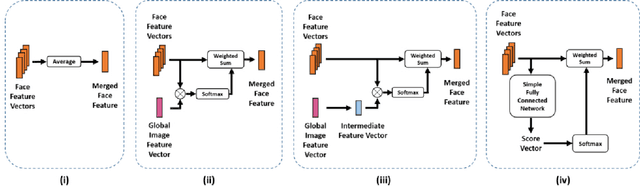
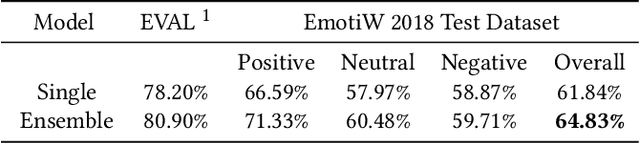
In this paper we propose a new approach for classifying the global emotion of images containing groups of people. To achieve this task, we consider two different and complementary sources of information: i) a global representation of the entire image (ii) a local representation where only faces are considered. While the global representation of the image is learned with a convolutional neural network (CNN), the local representation is obtained by merging face features through an attention mechanism. The two representations are first learned independently with two separate CNN branches and then fused through concatenation in order to obtain the final group-emotion classifier. For our submission to the EmotiW 2018 group-level emotion recognition challenge, we combine several variations of the proposed model into an ensemble, obtaining a final accuracy of 64.83% on the test set and ranking 4th among all challenge participants.