 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit-Merge Pooling
Jun 13, 2020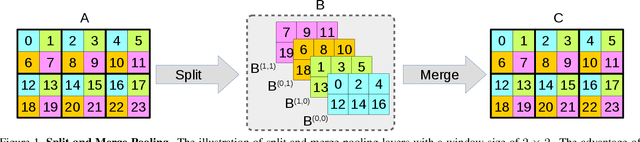

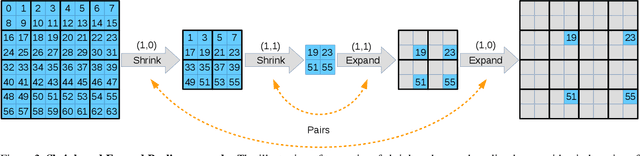
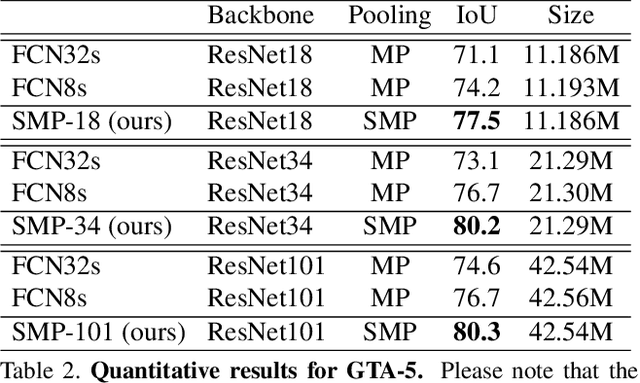
There are a variety of approaches to obtain a vast receptive field with convolutional neural networks (CNNs), such as pooling or striding convolutions. Most of these approaches were initially designed for image classification and later adapted to dense prediction tasks, such as semantic segmentation. However, the major drawback of this adaptation is the loss of spatial information. Even the popular dilated convolution approach, which in theory is able to operate with full spatial resolution, needs to subsample features for large image sizes in order to make the training and inference tractable. In this work, we introduce Split-Merge pooling to fully preserve the spatial information without any subsampling. By applying Split-Merge pooling to deep networks, we achieve, at the same time, a very large receptive field. We evaluate our approach for dense semantic segmentation of large image sizes taken from the Cityscapes and GTA-5 datasets. We demonstrate that by replacing max-pooling and striding convolutions with our split-merge pooling, we are able to improve the accuracy of different variations of ResNet significantly.
iPose: Instance-Aware 6D Pose Estimation of Partly Occluded Objects
Jun 18, 2018
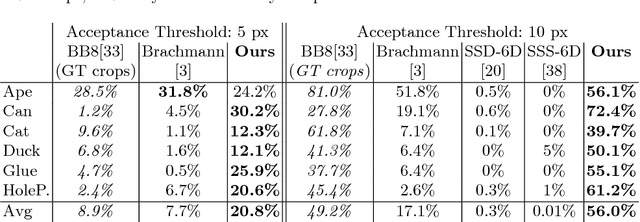

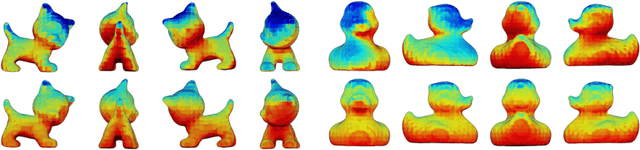
We address the task of 6D pose estimation of known rigid objects from single input images in scenarios where the objects are partly occluded. Recent RGB-D-based methods are robust to moderate degrees of occlusion. For RGB inputs, no previous method works well for partly occluded objects. Our main contribution is to present the first deep learning-based system that estimates accurate poses for partly occluded objects from RGB-D and RGB input. We achieve this with a new instance-aware pipeline that decomposes 6D object pose estimation into a sequence of simpler steps, where each step removes specific aspects of the problem. The first step localizes all known objects in the image using an instance segmentation network, and hence eliminates surrounding clutter and occluders. The second step densely maps pixels to 3D object surface positions, so called object coordinates, using an encoder-decoder network, and hence eliminates object appearance. The third, and final, step predicts the 6D pose using geometric optimization. We demonstrate that we significantly outperform the state-of-the-art for pose estimation of partly occluded objects for both RGB and RGB-D input.
Deep Object Co-Segmentation
Apr 17, 2018



This work presents a deep object co-segmentation (DOCS) approach for segmenting common objects of the same class within a pair of images. This means that the method learns to ignore common, or uncommon, background stuff and focuses on objects. If multiple object classes are presented in the image pair, they are jointly extracted as foreground. To address this task, we propose a CNN-based Siamese encoder-decoder architecture. The encoder extracts high-level semantic features of the foreground objects, a mutual correlation layer detects the common objects, and finally, the decoder generates the output foreground masks for each image. To train our model, we compile a large object co-segmentation dataset consisting of image pairs from the PASCAL VOC dataset with common objects masks. We evaluate our approach on commonly used datasets for co-segmentation tasks and observe that our approach consistently outperforms competing methods, for both seen and unseen object classes.
Analyzing Modular CNN Architectures for Joint Depth Prediction and Semantic Segmentation
Feb 26, 2017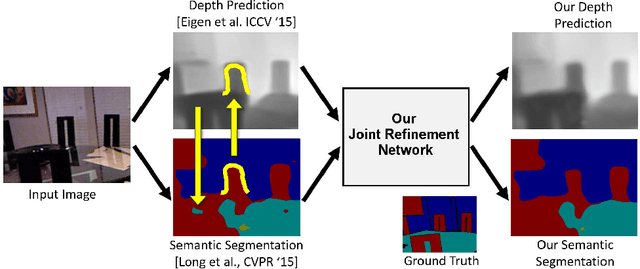
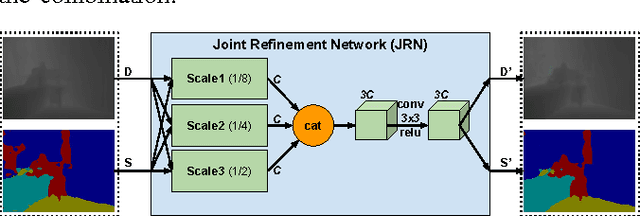
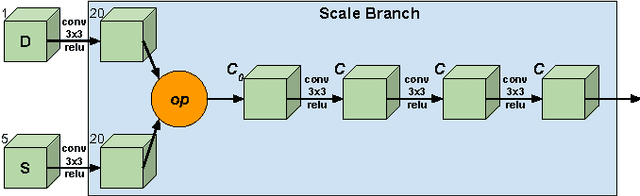

This paper addresses the task of designing a modular neural network architecture that jointly solves different tasks. As an example we use the tasks of depth estimation and semantic segmentation given a single RGB image. The main focus of this work is to analyze the cross-modality influence between depth and semantic prediction maps on their joint refinement. While most previous works solely focus on measuring improvements in accuracy, we propose a way to quantify the cross-modality influence. We show that there is a relationship between final accuracy and cross-modality influence, although not a simple linear one. Hence a larger cross-modality influence does not necessarily translate into an improved accuracy. We find that a beneficial balance between the cross-modality influences can be achieved by network architecture and conjecture that this relationship can be utilized to understand different network design choices. Towards this end we propose a Convolutional Neural Network (CNN) architecture that fuses the state of the state-of-the-art results for depth estimation and semantic labeling. By balancing the cross-modality influences between depth and semantic prediction, we achieve improved results for both tasks using the NYU-Depth v2 benchmark.