 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Modular CNN Architectures for Joint Depth Prediction and Semantic Segmentation
Paper and Code
Feb 26, 2017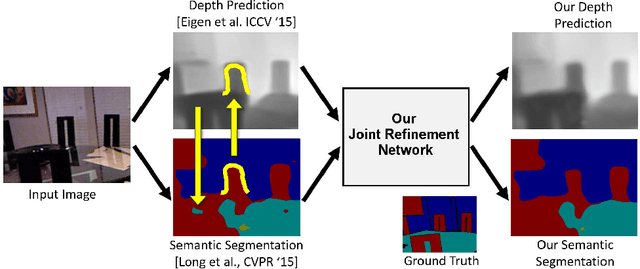
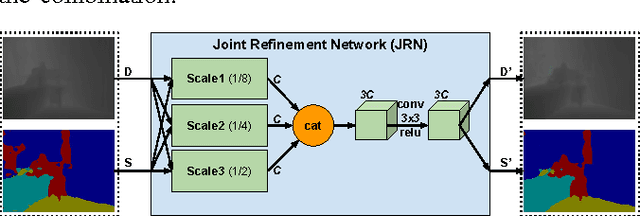
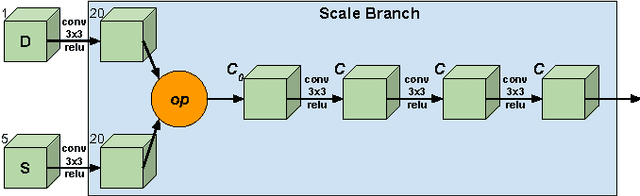

This paper addresses the task of designing a modular neural network architecture that jointly solves different tasks. As an example we use the tasks of depth estimation and semantic segmentation given a single RGB image. The main focus of this work is to analyze the cross-modality influence between depth and semantic prediction maps on their joint refinement. While most previous works solely focus on measuring improvements in accuracy, we propose a way to quantify the cross-modality influence. We show that there is a relationship between final accuracy and cross-modality influence, although not a simple linear one. Hence a larger cross-modality influence does not necessarily translate into an improved accuracy. We find that a beneficial balance between the cross-modality influences can be achieved by network architecture and conjecture that this relationship can be utilized to understand different network design choices. Towards this end we propose a Convolutional Neural Network (CNN) architecture that fuses the state of the state-of-the-art results for depth estimation and semantic labeling. By balancing the cross-modality influences between depth and semantic prediction, we achieve improved results for both tasks using the NYU-Depth v2 benchmark.