 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Cone Effect and Modality Gap in Medical Vision-Language Embeddings
Mar 18, 2026Vision-Language Models (VLMs) exhibit a characteristic "cone effect" in which nonlinear encoders map embeddings into highly concentrated regions of the representation space, contributing to cross-modal separation known as the modality gap. While this phenomenon has been widely observed, its practical impact on supervised multimodal learning -particularly in medical domains- remains unclear. In this work, we introduce a lightweight post-hoc mechanism that keeps pretrained VLM encoders frozen while continuously controlling cross-modal separation through a single hyperparameter {λ}. This enables systematic analysis of how the modality gap affects downstream multimodal performance without expensive retraining. We evaluate generalist (CLIP, SigLIP) and medically specialized (BioMedCLIP, MedSigLIP) models across diverse medical and natural datasets in a supervised multimodal settings. Results consistently show that reducing excessive modality gap improves downstream performance, with medical datasets exhibiting stronger sensitivity to gap modulation; however, fully collapsing the gap is not always optimal, and intermediate, task-dependent separation yields the best results. These findings position the modality gap as a tunable property of multimodal representations rather than a quantity that should be universally minimized.
EDCO: Dynamic Curriculum Orchestration for Domain-specific Large Language Model Fine-tuning
Jan 07, 2026Domain-specific large language models (LLMs), typically developed by fine-tuning a pre-trained general-purpose LLM on specialized datasets, represent a significant advancement in applied AI. A common strategy in LLM fine-tuning is curriculum learning, which pre-orders training samples based on metrics like difficulty to improve learning efficiency compared to a random sampling strategy. However, most existing methods for LLM fine-tuning rely on a static curriculum, designed prior to training, which lacks adaptability to the model's evolving needs during fine-tuning. To address this, we propose EDCO, a novel framework based on two key concepts: inference entropy and dynamic curriculum orchestration. Inspired by recent findings that maintaining high answer entropy benefits long-term reasoning gains, EDCO prioritizes samples with high inference entropy in a continuously adapted curriculum. EDCO integrates three core components: an efficient entropy estimator that uses prefix tokens to approximate full-sequence entropy, an entropy-based curriculum generator that selects data points with the highest inference entropy, and an LLM trainer that optimizes the model on the selected curriculum. Comprehensive experiments in communication, medicine and law domains, EDCO outperforms traditional curriculum strategies for fine-tuning Qwen3-4B and Llama3.2-3B models under supervised and reinforcement learning settings. Furthermore, the proposed efficient entropy estimation reduces computational time by 83.5% while maintaining high accuracy.
CURENet: Combining Unified Representations for Efficient Chronic Disease Prediction
Nov 14, 2025Electronic health records (EHRs) are designed to synthesize diverse data types, including unstructured clinical notes, structured lab tests, and time-series visit data. Physicians draw on these multimodal and temporal sources of EHR data to form a comprehensive view of a patient's health, which is crucial for informed therapeutic decision-making. Yet, most predictive models fail to fully capture the interactions, redundancies, and temporal patterns across multiple data modalities, often focusing on a single data type or overlooking these complexities. In this paper, we present CURENet, a multimodal model (Combining Unified Representations for Efficient chronic disease prediction) that integrates unstructured clinical notes, lab tests, and patients' time-series data by utilizing large language models (LLMs) for clinical text processing and textual lab tests, as well as transformer encoders for longitudinal sequential visits. CURENet has been capable of capturing the intricate interaction between different forms of clinical data and creating a more reliable predictive model for chronic illnesses. We evaluated CURENet using the public MIMIC-III and private FEMH datasets, where it achieved over 94\% accuracy in predicting the top 10 chronic conditions in a multi-label framework. Our findings highlight the potential of multimodal EHR integration to enhance clinical decision-making and improve patient outcomes.
Representation Learning of Lab Values via Masked AutoEncoder
Jan 05, 2025



Accurate imputation of missing laboratory values in electronic health records (EHRs) is critical to enable robust clinical predictions and reduce biases in AI systems in healthcare. Existing methods, such as variational autoencoders (VAEs) and decision tree-based approaches such as XGBoost, struggle to model the complex temporal and contextual dependencies in EHR data, mainly in underrepresented groups. In this work, we propose Lab-MAE, a novel transformer-based masked autoencoder framework that leverages self-supervised learning for the imputation of continuous sequential lab values. Lab-MAE introduces a structured encoding scheme that jointly models laboratory test values and their corresponding timestamps, enabling explicit capturing temporal dependencies. Empirical evaluation on the MIMIC-IV dataset demonstrates that Lab-MAE significantly outperforms the state-of-the-art baselines such as XGBoost across multiple metrics, including root mean square error (RMSE), R-squared (R2), and Wasserstein distance (WD). Notably, Lab-MAE achieves equitable performance across demographic groups of patients, advancing fairness in clinical predictions. We further investigate the role of follow-up laboratory values as potential shortcut features, revealing Lab-MAE's robustness in scenarios where such data is unavailable. The findings suggest that our transformer-based architecture, adapted to the characteristics of the EHR data, offers a foundation model for more accurate and fair clinical imputation models. In addition, we measure and compare the carbon footprint of Lab-MAE with the baseline XGBoost model, highlighting its environmental requirements.
Multi-OphthaLingua: A Multilingual Benchmark for Assessing and Debiasing LLM Ophthalmological QA in LMICs
Dec 18, 2024



Current ophthalmology clinical workflows are plagued by over-referrals, long waits, and complex and heterogeneous medical records. Large language models (LLMs) present a promising solution to automate various procedures such as triaging, preliminary tests like visual acuity assessment, and report summaries. However, LLMs have demonstrated significantly varied performance across different languages in natural language question-answering tasks, potentially exacerbating healthcare disparities in Low and Middle-Income Countries (LMICs). This study introduces the first multilingual ophthalmological question-answering benchmark with manually curated questions parallel across languages, allowing for direct cross-lingual comparisons. Our evaluation of 6 popular LLMs across 7 different languages reveals substantial bias across different languages, highlighting risks for clinical deployment of LLMs in LMICs. Existing debiasing methods such as Translation Chain-of-Thought or Retrieval-augmented generation (RAG) by themselves fall short of closing this performance gap, often failing to improve performance across all languages and lacking specificity for the medical domain. To address this issue, We propose CLARA (Cross-Lingual Reflective Agentic system), a novel inference time de-biasing method leveraging retrieval augmented generation and self-verification. Our approach not only improves performance across all languages but also significantly reduces the multilingual bias gap, facilitating equitable LLM application across the globe.
Deep Learning for Personalized Electrocardiogram Diagnosis: A Review
Sep 12, 2024The electrocardiogram (ECG) remains a fundamental tool in cardiac diagnostics, yet its interpretation traditionally reliant on the expertise of cardiologists. The emergence of deep learning has heralded a revolutionary era in medical data analysis, particularly in the domain of ECG diagnostics. However, inter-patient variability prohibit the generalibility of ECG-AI model trained on a population dataset, hence degrade the performance of ECG-AI on specific patient or patient group. Many studies have address this challenge using different deep learning technologies. This comprehensive review systematically synthesizes research from a wide range of studies to provide an in-depth examination of cutting-edge deep-learning techniques in personalized ECG diagnosis. The review outlines a rigorous methodology for the selection of pertinent scholarly articles and offers a comprehensive overview of deep learning approaches applied to personalized ECG diagnostics. Moreover, the challenges these methods encounter are investigated, along with future research directions, culminating in insights into how the integration of deep learning can transform personalized ECG diagnosis and enhance cardiac care. By emphasizing both the strengths and limitations of current methodologies, this review underscores the immense potential of deep learning to refine and redefine ECG analysis in clinical practice, paving the way for more accurate, efficient, and personalized cardiac diagnostics.
Latent Space Disentanglement in Diffusion Transformers Enables Zero-shot Fine-grained Semantic Editing
Aug 23, 2024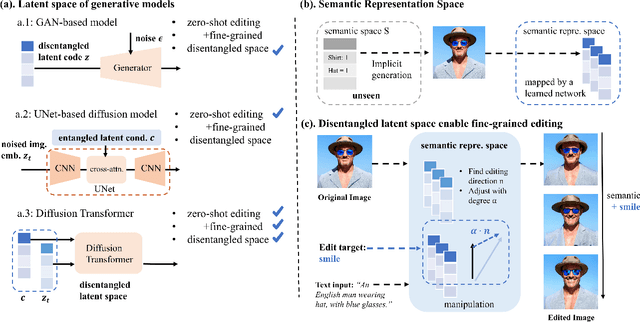

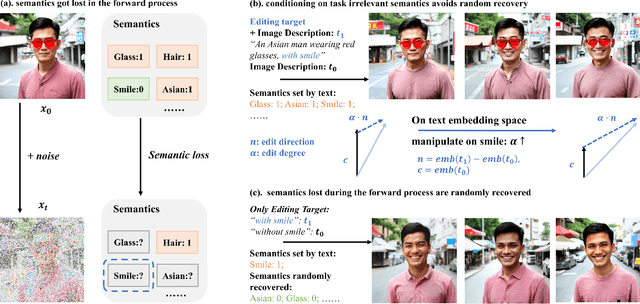

Diffusion Transformers (DiTs) have achieved remarkable success in diverse and high-quality text-to-image(T2I) generation. However, how text and image latents individually and jointly contribute to the semantics of generated images, remain largely unexplored. Through our investigation of DiT's latent space, we have uncovered key findings that unlock the potential for zero-shot fine-grained semantic editing: (1) Both the text and image spaces in DiTs are inherently decomposable. (2) These spaces collectively form a disentangled semantic representation space, enabling precise and fine-grained semantic control. (3) Effective image editing requires the combined use of both text and image latent spaces. Leveraging these insights, we propose a simple and effective Extract-Manipulate-Sample (EMS) framework for zero-shot fine-grained image editing. Our approach first utilizes a multi-modal Large Language Model to convert input images and editing targets into text descriptions. We then linearly manipulate text embeddings based on the desired editing degree and employ constrained score distillation sampling to manipulate image embeddings. We quantify the disentanglement degree of the latent space of diffusion models by proposing a new metric. To evaluate fine-grained editing performance, we introduce a comprehensive benchmark incorporating both human annotations, manual evaluation, and automatic metrics. We have conducted extensive experimental results and in-depth analysis to thoroughly uncover the semantic disentanglement properties of the diffusion transformer, as well as the effectiveness of our proposed method. Our annotated benchmark dataset is publicly available at https://anonymous.com/anonymous/EMS-Benchmark, facilitating reproducible research in this domain.
Dr.Academy: A Benchmark for Evaluating Questioning Capability in Education for Large Language Models
Aug 20, 2024



Teachers are important to imparting knowledge and guiding learners, and the role of large language models (LLMs) as potential educators is emerging as an important area of study. Recognizing LLMs' capability to generate educational content can lead to advances in automated and personalized learning. While LLMs have been tested for their comprehension and problem-solving skills, their capability in teaching remains largely unexplored. In teaching, questioning is a key skill that guides students to analyze, evaluate, and synthesize core concepts and principles. Therefore, our research introduces a benchmark to evaluate the questioning capability in education as a teacher of LLMs through evaluating their generated educational questions, utilizing Anderson and Krathwohl's taxonomy across general, monodisciplinary, and interdisciplinary domains. We shift the focus from LLMs as learners to LLMs as educators, assessing their teaching capability through guiding them to generate questions. We apply four metrics, including relevance, coverage, representativeness, and consistency, to evaluate the educational quality of LLMs' outputs. Our results indicate that GPT-4 demonstrates significant potential in teaching general, humanities, and science courses; Claude2 appears more apt as an interdisciplinary teacher. Furthermore, the automatic scores align with human perspectives.
MEDFuse: Multimodal EHR Data Fusion with Masked Lab-Test Modeling and Large Language Models
Jul 17, 2024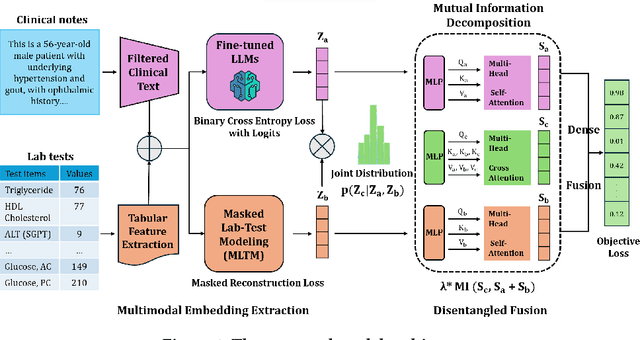
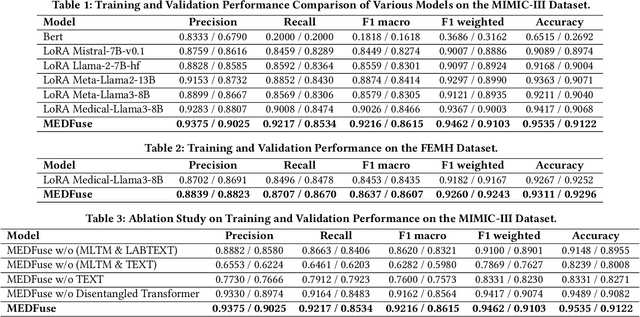
Electronic health records (EHRs) are multimodal by nature, consisting of structured tabular features like lab tests and unstructured clinical notes. In real-life clinical practice, doctors use complementary multimodal EHR data sources to get a clearer picture of patients' health and support clinical decision-making. However, most EHR predictive models do not reflect these procedures, as they either focus on a single modality or overlook the inter-modality interactions/redundancy. In this work, we propose MEDFuse, a Multimodal EHR Data Fusion framework that incorporates masked lab-test modeling and large language models (LLMs) to effectively integrate structured and unstructured medical data. MEDFuse leverages multimodal embeddings extracted from two sources: LLMs fine-tuned on free clinical text and masked tabular transformers trained on structured lab test results. We design a disentangled transformer module, optimized by a mutual information loss to 1) decouple modality-specific and modality-shared information and 2) extract useful joint representation from the noise and redundancy present in clinical notes. Through comprehensive validation on the public MIMIC-III dataset and the in-house FEMH dataset, MEDFuse demonstrates great potential in advancing clinical predictions, achieving over 90% F1 score in the 10-disease multi-label classification task.
Efficient In-Context Medical Segmentation with Meta-driven Visual Prompt Selection
Jul 15, 2024



In-context learning (ICL) with Large Vision Models (LVMs) presents a promising avenue in medical image segmentation by reducing the reliance on extensive labeling. However, the ICL performance of LVMs highly depends on the choices of visual prompts and suffers from domain shifts. While existing works leveraging LVMs for medical tasks have focused mainly on model-centric approaches like fine-tuning, we study an orthogonal data-centric perspective on how to select good visual prompts to facilitate generalization to medical domain. In this work, we propose a label-efficient in-context medical segmentation method by introducing a novel Meta-driven Visual Prompt Selection mechanism (MVPS), where a prompt retriever obtained from a meta-learning framework actively selects the optimal images as prompts to promote model performance and generalizability. Evaluated on 8 datasets and 4 tasks across 3 medical imaging modalities, our proposed approach demonstrates consistent gains over existing methods under different scenarios, improving both computational and label efficiency. Finally, we show that MVPS is a flexible, finetuning-free module that could be easily plugged into different backbones and combined with other model-centric approaches.