 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Disentanglement in Diffusion Transformers Enables Zero-shot Fine-grained Semantic Editing
Paper and Code
Aug 23, 2024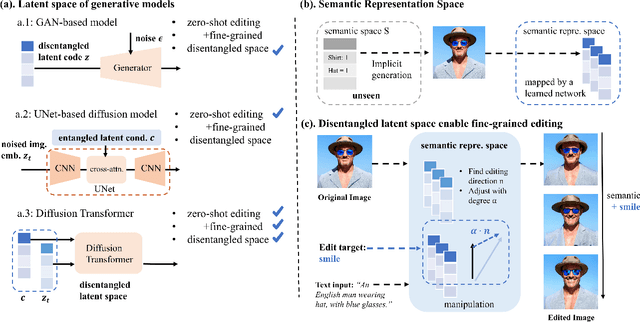

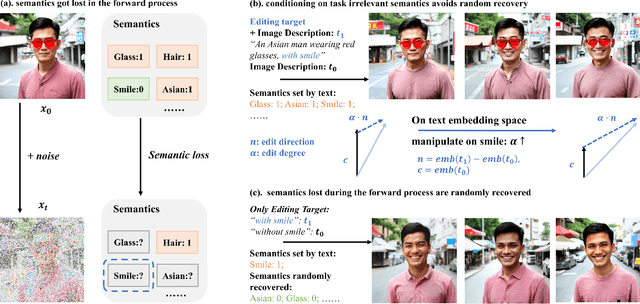

Diffusion Transformers (DiTs) have achieved remarkable success in diverse and high-quality text-to-image(T2I) generation. However, how text and image latents individually and jointly contribute to the semantics of generated images, remain largely unexplored. Through our investigation of DiT's latent space, we have uncovered key findings that unlock the potential for zero-shot fine-grained semantic editing: (1) Both the text and image spaces in DiTs are inherently decomposable. (2) These spaces collectively form a disentangled semantic representation space, enabling precise and fine-grained semantic control. (3) Effective image editing requires the combined use of both text and image latent spaces. Leveraging these insights, we propose a simple and effective Extract-Manipulate-Sample (EMS) framework for zero-shot fine-grained image editing. Our approach first utilizes a multi-modal Large Language Model to convert input images and editing targets into text descriptions. We then linearly manipulate text embeddings based on the desired editing degree and employ constrained score distillation sampling to manipulate image embeddings. We quantify the disentanglement degree of the latent space of diffusion models by proposing a new metric. To evaluate fine-grained editing performance, we introduce a comprehensive benchmark incorporating both human annotations, manual evaluation, and automatic metrics. We have conducted extensive experimental results and in-depth analysis to thoroughly uncover the semantic disentanglement properties of the diffusion transformer, as well as the effectiveness of our proposed method. Our annotated benchmark dataset is publicly available at https://anonymous.com/anonymous/EMS-Benchmark, facilitating reproducible research in this domain.