 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Deep Learning for Low-Resource Settings: A Vector Embedding Alignment Approach for Healthcare Applications
Jun 02, 2024Large-scale multi-modal deep learning models have revolutionized domains such as healthcare, highlighting the importance of computational power. However, in resource-constrained regions like Low and Middle-Income Countries (LMICs), limited access to GPUs and data poses significant challenges, often leaving CPUs as the sole resource. To address this, we advocate for leveraging vector embeddings to enable flexible and efficient computational methodologies, democratizing multimodal deep learning across diverse contexts. Our paper investigates the efficiency and effectiveness of using vector embeddings from single-modal foundation models and multi-modal Vision-Language Models (VLMs) for multimodal deep learning in low-resource environments, particularly in healthcare. Additionally, we propose a simple yet effective inference-time method to enhance performance by aligning image-text embeddings. Comparing these approaches with traditional methods, we assess their impact on computational efficiency and model performance using metrics like accuracy, F1-score, inference time, training time, and memory usage across three medical modalities: BRSET (ophthalmology), HAM10000 (dermatology), and SatelliteBench (public health). Our findings show that embeddings reduce computational demands without compromising model performance. Furthermore, our alignment method improves performance in medical tasks. This research promotes sustainable AI practices by optimizing resources in constrained environments, highlighting the potential of embedding-based approaches for efficient multimodal learning. Vector embeddings democratize multimodal deep learning in LMICs, particularly in healthcare, enhancing AI adaptability in varied use cases.
DF-DM: A foundational process model for multimodal data fusion in the artificial intelligence era
Apr 18, 2024


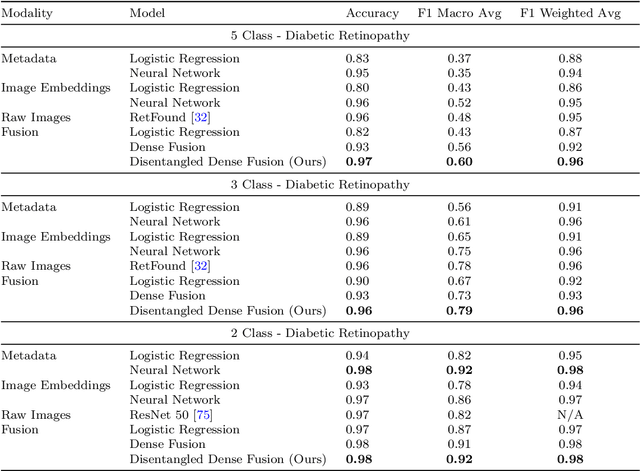
In the big data era, integrating diverse data modalities poses significant challenges, particularly in complex fields like healthcare. This paper introduces a new process model for multimodal Data Fusion for Data Mining, integrating embeddings and the Cross-Industry Standard Process for Data Mining with the existing Data Fusion Information Group model. Our model aims to decrease computational costs, complexity, and bias while improving efficiency and reliability. We also propose "disentangled dense fusion", a novel embedding fusion method designed to optimize mutual information and facilitate dense inter-modality feature interaction, thereby minimizing redundant information. We demonstrate the model's efficacy through three use cases: predicting diabetic retinopathy using retinal images and patient metadata, domestic violence prediction employing satellite imagery, internet, and census data, and identifying clinical and demographic features from radiography images and clinical notes. The model achieved a Macro F1 score of 0.92 in diabetic retinopathy prediction, an R-squared of 0.854 and sMAPE of 24.868 in domestic violence prediction, and a macro AUC of 0.92 and 0.99 for disease prediction and sex classification, respectively, in radiological analysis. These results underscore the Data Fusion for Data Mining model's potential to significantly impact multimodal data processing, promoting its adoption in diverse, resource-constrained settings.