 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing predictive multiplicity to measure individual performance within the AI Act
Feb 12, 2026When building AI systems for decision support, one often encounters the phenomenon of predictive multiplicity: a single best model does not exist; instead, one can construct many models with similar overall accuracy that differ in their predictions for individual cases. Especially when decisions have a direct impact on humans, this can be highly unsatisfactory. For a person subject to high disagreement between models, one could as well have chosen a different model of similar overall accuracy that would have decided the person's case differently. We argue that this arbitrariness conflicts with the EU AI Act, which requires providers of high-risk AI systems to report performance not only at the dataset level but also for specific persons. The goal of this paper is to put predictive multiplicity in context with the EU AI Act's provisions on accuracy and to subsequently derive concrete suggestions on how to evaluate and report predictive multiplicity in practice. Specifically: (1) We argue that incorporating information about predictive multiplicity can serve compliance with the EU AI Act's accuracy provisions for providers. (2) Based on this legal analysis, we suggest individual conflict ratios and $δ$-ambiguity as tools to quantify the disagreement between models on individual cases and to help detect individuals subject to conflicting predictions. (3) Based on computational insights, we derive easy-to-implement rules on how model providers could evaluate predictive multiplicity in practice. (4) Ultimately, we suggest that information about predictive multiplicity should be made available to deployers under the AI Act, enabling them to judge whether system outputs for specific individuals are reliable enough for their use case.
Weight Decay Improves Language Model Plasticity
Feb 11, 2026The prevailing paradigm in large language model (LLM) development is to pretrain a base model, then perform further training to improve performance and model behavior. However, hyperparameter optimization and scaling laws have been studied primarily from the perspective of the base model's validation loss, ignoring downstream adaptability. In this work, we study pretraining from the perspective of model plasticity, that is, the ability of the base model to successfully adapt to downstream tasks through fine-tuning. We focus on the role of weight decay, a key regularization parameter during pretraining. Through systematic experiments, we show that models trained with larger weight decay values are more plastic, meaning they show larger performance gains when fine-tuned on downstream tasks. This phenomenon can lead to counterintuitive trade-offs where base models that perform worse after pretraining can perform better after fine-tuning. Further investigation of weight decay's mechanistic effects on model behavior reveals that it encourages linearly separable representations, regularizes attention matrices, and reduces overfitting on the training data. In conclusion, this work demonstrates the importance of using evaluation metrics beyond cross-entropy loss for hyperparameter optimization and casts light on the multifaceted role of that a single optimization hyperparameter plays in shaping model behavior.
On the Surprising Effectiveness of Large Learning Rates under Standard Width Scaling
May 28, 2025



The dominant paradigm for training large-scale vision and language models is He initialization and a single global learning rate (\textit{standard parameterization}, SP). Despite its practical success, standard parametrization remains poorly understood from a theoretical perspective: Existing infinite-width theory would predict instability under large learning rates and vanishing feature learning under stable learning rates. However, empirically optimal learning rates consistently decay much slower than theoretically predicted. By carefully studying neural network training dynamics, we demonstrate that this discrepancy is not fully explained by finite-width phenomena such as catapult effects or a lack of alignment between weights and incoming activations. We instead show that the apparent contradiction can be fundamentally resolved by taking the loss function into account: In contrast to Mean Squared Error (MSE) loss, we prove that under cross-entropy (CE) loss, an intermediate \textit{controlled divergence} regime emerges, where logits diverge but loss, gradients, and activations remain stable. Stable training under large learning rates enables persistent feature evolution at scale in all hidden layers, which is crucial for the practical success of SP. In experiments across optimizers (SGD, Adam), architectures (MLPs, GPT) and data modalities (vision, language), we validate that neural networks operate in this controlled divergence regime under CE loss but not under MSE loss. Our empirical evidence suggests that width-scaling considerations are surprisingly useful for predicting empirically optimal learning rate exponents. Finally, our analysis clarifies the effectiveness and limitations of recently proposed layerwise learning rate scalings for standard initialization.
How much can we forget about Data Contamination?
Oct 04, 2024
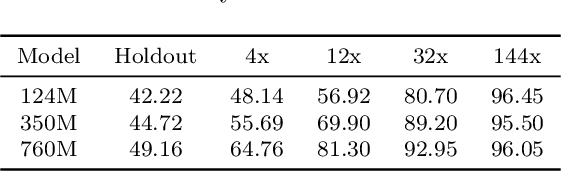
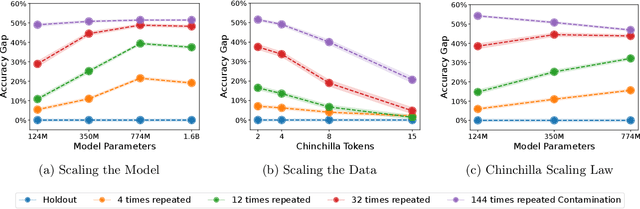
The leakage of benchmark data into the training data has emerged as a significant challenge for evaluating the capabilities of large language models (LLMs). In this work, we use experimental evidence and theoretical estimates to challenge the common assumption that small-scale contamination renders benchmark evaluations invalid. First, we experimentally quantify the magnitude of benchmark overfitting based on scaling along three dimensions: The number of model parameters (up to 1.6B), the number of times an example is seen (up to 144), and the number of training tokens (up to 40B). We find that if model and data follow the Chinchilla scaling laws, minor contamination indeed leads to overfitting. At the same time, even 144 times of contamination can be forgotten if the training data is scaled beyond five times Chinchilla, a regime characteristic of many modern LLMs. We then derive a simple theory of example forgetting via cumulative weight decay. It allows us to bound the number of gradient steps required to forget past data for any training run where we know the hyperparameters of AdamW. This indicates that many LLMs, including Llama 3, have forgotten the data seen at the beginning of training. Experimentally, we demonstrate that forgetting occurs faster than what is predicted by our bounds. Taken together, our results suggest that moderate amounts of contamination can be forgotten at the end of realistically scaled training runs.
Elephants Never Forget: Memorization and Learning of Tabular Data in Large Language Models
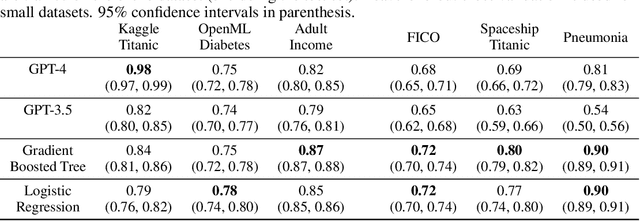
Apr 09, 2024While many have shown how Large Language Models (LLMs) can be applied to a diverse set of tasks, the critical issues of data contamination and memorization are often glossed over. In this work, we address this concern for tabular data. Specifically, we introduce a variety of different techniques to assess whether a language model has seen a tabular dataset during training. This investigation reveals that LLMs have memorized many popular tabular datasets verbatim. We then compare the few-shot learning performance of LLMs on datasets that were seen during training to the performance on datasets released after training. We find that LLMs perform better on datasets seen during training, indicating that memorization leads to overfitting. At the same time, LLMs show non-trivial performance on novel datasets and are surprisingly robust to data transformations. We then investigate the in-context statistical learning abilities of LLMs. Without fine-tuning, we find them to be limited. This suggests that much of the few-shot performance on novel datasets is due to the LLM's world knowledge. Overall, our results highlight the importance of testing whether an LLM has seen an evaluation dataset during pre-training. We make the exposure tests we developed available as the tabmemcheck Python package at https://github.com/interpretml/LLM-Tabular-Memorization-Checker
Elephants Never Forget: Testing Language Models for Memorization of Tabular Data
Mar 11, 2024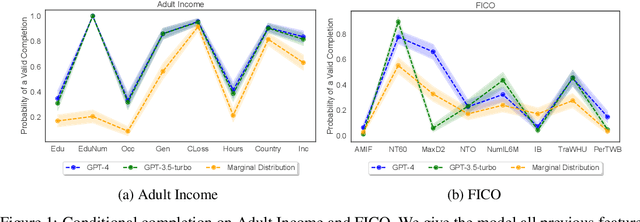
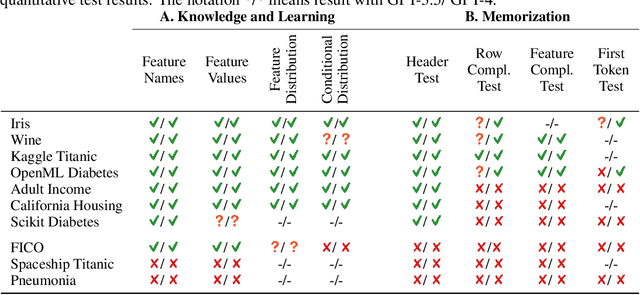
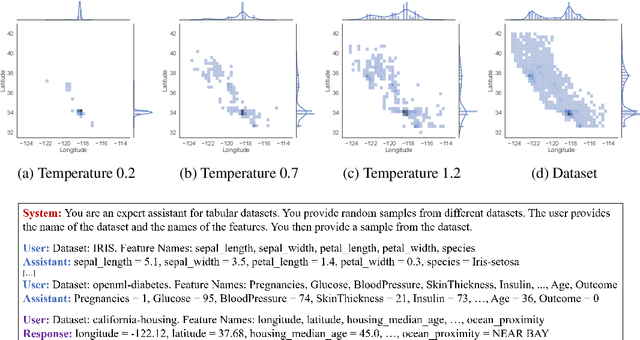
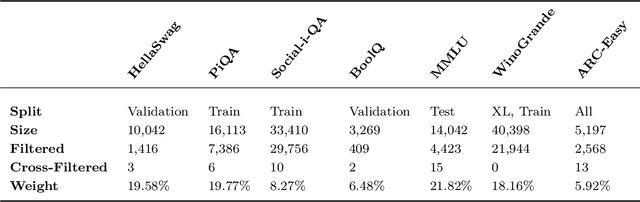
While many have shown how Large Language Models (LLMs) can be applied to a diverse set of tasks, the critical issues of data contamination and memorization are often glossed over. In this work, we address this concern for tabular data. Starting with simple qualitative tests for whether an LLM knows the names and values of features, we introduce a variety of different techniques to assess the degrees of contamination, including statistical tests for conditional distribution modeling and four tests that identify memorization. Our investigation reveals that LLMs are pre-trained on many popular tabular datasets. This exposure can lead to invalid performance evaluation on downstream tasks because the LLMs have, in effect, been fit to the test set. Interestingly, we also identify a regime where the language model reproduces important statistics of the data, but fails to reproduce the dataset verbatim. On these datasets, although seen during training, good performance on downstream tasks might not be due to overfitting. Our findings underscore the need for ensuring data integrity in machine learning tasks with LLMs. To facilitate future research, we release an open-source tool that can perform various tests for memorization \url{https://github.com/interpretml/LLM-Tabular-Memorization-Checker}.
Data Science with LLMs and Interpretable Models
Feb 22, 2024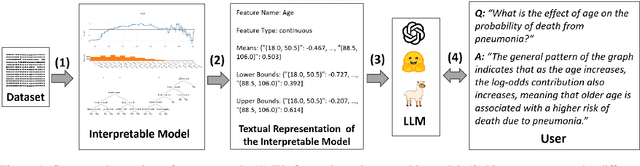
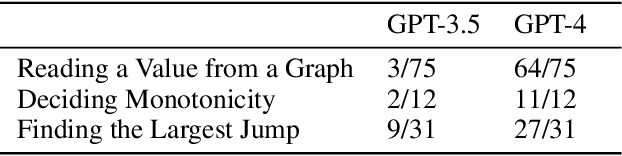


Recent years have seen important advances in the building of interpretable models, machine learning models that are designed to be easily understood by humans. In this work, we show that large language models (LLMs) are remarkably good at working with interpretable models, too. In particular, we show that LLMs can describe, interpret, and debug Generalized Additive Models (GAMs). Combining the flexibility of LLMs with the breadth of statistical patterns accurately described by GAMs enables dataset summarization, question answering, and model critique. LLMs can also improve the interaction between domain experts and interpretable models, and generate hypotheses about the underlying phenomenon. We release \url{https://github.com/interpretml/TalkToEBM} as an open-source LLM-GAM interface.
Statistics without Interpretation: A Sober Look at Explainable Machine Learning
Feb 05, 2024In the rapidly growing literature on explanation algorithms, it often remains unclear what precisely these algorithms are for and how they should be used. We argue that this is because explanation algorithms are often mathematically complex but don't admit a clear interpretation. Unfortunately, complex statistical methods that don't have a clear interpretation are bound to lead to errors in interpretation, a fact that has become increasingly apparent in the literature. In order to move forward, papers on explanation algorithms should make clear how precisely the output of the algorithms should be interpreted. They should also clarify what questions about the function can and cannot be answered given the explanations. Our argument is based on the distinction between statistics and their interpretation. It also relies on parallels between explainable machine learning and applied statistics.
LLMs Understand Glass-Box Models, Discover Surprises, and Suggest Repairs
Aug 07, 2023We show that large language models (LLMs) are remarkably good at working with interpretable models that decompose complex outcomes into univariate graph-represented components. By adopting a hierarchical approach to reasoning, LLMs can provide comprehensive model-level summaries without ever requiring the entire model to fit in context. This approach enables LLMs to apply their extensive background knowledge to automate common tasks in data science such as detecting anomalies that contradict prior knowledge, describing potential reasons for the anomalies, and suggesting repairs that would remove the anomalies. We use multiple examples in healthcare to demonstrate the utility of these new capabilities of LLMs, with particular emphasis on Generalized Additive Models (GAMs). Finally, we present the package $\texttt{TalkToEBM}$ as an open-source LLM-GAM interface.
Which Models have Perceptually-Aligned Gradients? An Explanation via Off-Manifold Robustness
May 30, 2023



One of the remarkable properties of robust computer vision models is that their input-gradients are often aligned with human perception, referred to in the literature as perceptually-aligned gradients (PAGs). Despite only being trained for classification, PAGs cause robust models to have rudimentary generative capabilities, including image generation, denoising, and in-painting. However, the underlying mechanisms behind these phenomena remain unknown. In this work, we provide a first explanation of PAGs via \emph{off-manifold robustness}, which states that models must be more robust off- the data manifold than they are on-manifold. We first demonstrate theoretically that off-manifold robustness leads input gradients to lie approximately on the data manifold, explaining their perceptual alignment. We then show that Bayes optimal models satisfy off-manifold robustness, and confirm the same empirically for robust models trained via gradient norm regularization, noise augmentation, and randomized smoothing. Quantifying the perceptual alignment of model gradients via their similarity with the gradients of generative models, we show that off-manifold robustness correlates well with perceptual alignment. Finally, based on the levels of on- and off-manifold robustness, we identify three different regimes of robustness that affect both perceptual alignment and model accuracy: weak robustness, bayes-aligned robustness, and excessive robustness.