 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Scale Mixture-of-Experts: From muP to the Maximally Scale-Stable Parameterization
May 13, 2026Recent frontier large language models predominantly rely on Mixture-of-Experts (MoE) architectures. Despite empirical progress, there is still no principled understanding of how hyperparameters should scale with network width $N$, expert width $N_e$, number of experts $M$, sparsity $K$, and depth $L$ to ensure both stability and optimal performance at scale. We take a principled step toward resolving this gap by analyzing three different scaling regimes: (I) co-scaling $N\asymp N_e$, (II) co-scaling $N\asymp M\asymp K$, and (III) full proportional scaling of $N, N_e, M$, and $K$. For each regime, we develop a novel Dynamical Mean Field Theory (DMFT) description of the limiting training dynamics of MoEs that provides a formal foundation for our analysis. Within this framework, we derive the unique parameterization for SGD and Adam satisfying all maximal-update ($μ$) desiderata. We then show that the resulting $μ$P prescription does not reliably induce monotonic improvement with scale or robust learning-rate transfer. We trace these pathologies to scale-dependent observables in the aggregation dynamics, which motivates a refined set of desiderata that we term maximal scale stability. Guided by this principle, we derive a Maximally Scale-Stable Parameterization (MSSP) for both SGD and Adam in all three scaling regimes, and characterize the corresponding limiting dynamics - qualitatively distinct from the $μ$P limit - through a separate DMFT analysis. Experiments verify that MSSP robustly recovers learning rate transfer and monotonic improvement with scale across regimes. Combined with existing depth-scaling theory, these results provide a complete scaling prescription for MoE architectures as a function of width, depth, expert width, and number of experts.
On the Surprising Effectiveness of Large Learning Rates under Standard Width Scaling
May 28, 2025



The dominant paradigm for training large-scale vision and language models is He initialization and a single global learning rate (\textit{standard parameterization}, SP). Despite its practical success, standard parametrization remains poorly understood from a theoretical perspective: Existing infinite-width theory would predict instability under large learning rates and vanishing feature learning under stable learning rates. However, empirically optimal learning rates consistently decay much slower than theoretically predicted. By carefully studying neural network training dynamics, we demonstrate that this discrepancy is not fully explained by finite-width phenomena such as catapult effects or a lack of alignment between weights and incoming activations. We instead show that the apparent contradiction can be fundamentally resolved by taking the loss function into account: In contrast to Mean Squared Error (MSE) loss, we prove that under cross-entropy (CE) loss, an intermediate \textit{controlled divergence} regime emerges, where logits diverge but loss, gradients, and activations remain stable. Stable training under large learning rates enables persistent feature evolution at scale in all hidden layers, which is crucial for the practical success of SP. In experiments across optimizers (SGD, Adam), architectures (MLPs, GPT) and data modalities (vision, language), we validate that neural networks operate in this controlled divergence regime under CE loss but not under MSE loss. Our empirical evidence suggests that width-scaling considerations are surprisingly useful for predicting empirically optimal learning rate exponents. Finally, our analysis clarifies the effectiveness and limitations of recently proposed layerwise learning rate scalings for standard initialization.
$\boldsymbolμ\mathbf{P^2}$: Effective Sharpness Aware Minimization Requires Layerwise Perturbation Scaling
Oct 31, 2024Sharpness Aware Minimization (SAM) enhances performance across various neural architectures and datasets. As models are continually scaled up to improve performance, a rigorous understanding of SAM's scaling behaviour is paramount. To this end, we study the infinite-width limit of neural networks trained with SAM, using the Tensor Programs framework. Our findings reveal that the dynamics of standard SAM effectively reduce to applying SAM solely in the last layer in wide neural networks, even with optimal hyperparameters. In contrast, we identify a stable parameterization with layerwise perturbation scaling, which we call $\textit{Maximal Update and Perturbation Parameterization}$ ($\mu$P$^2$), that ensures all layers are both feature learning and effectively perturbed in the limit. Through experiments with MLPs, ResNets and Vision Transformers, we empirically demonstrate that $\mu$P$^2$ is the first parameterization to achieve hyperparameter transfer of the joint optimum of learning rate and perturbation radius across model scales. Moreover, we provide an intuitive condition to derive $\mu$P$^2$ for other perturbation rules like Adaptive SAM and SAM-ON, also ensuring balanced perturbation effects across all layers.
Mind the spikes: Benign overfitting of kernels and neural networks in fixed dimension
May 23, 2023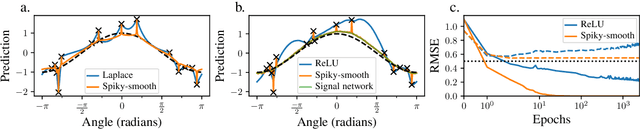
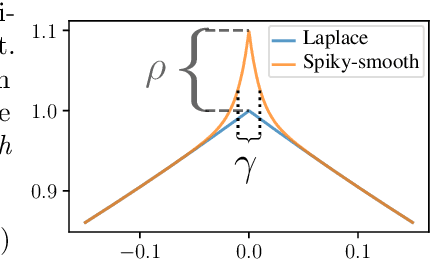

The success of over-parameterized neural networks trained to near-zero training error has caused great interest in the phenomenon of benign overfitting, where estimators are statistically consistent even though they interpolate noisy training data. While benign overfitting in fixed dimension has been established for some learning methods, current literature suggests that for regression with typical kernel methods and wide neural networks, benign overfitting requires a high-dimensional setting where the dimension grows with the sample size. In this paper, we show that the smoothness of the estimators, and not the dimension, is the key: benign overfitting is possible if and only if the estimator's derivatives are large enough. We generalize existing inconsistency results to non-interpolating models and more kernels to show that benign overfitting with moderate derivatives is impossible in fixed dimension. Conversely, we show that benign overfitting is possible for regression with a sequence of spiky-smooth kernels with large derivatives. Using neural tangent kernels, we translate our results to wide neural networks. We prove that while infinite-width networks do not overfit benignly with the ReLU activation, this can be fixed by adding small high-frequency fluctuations to the activation function. Our experiments verify that such neural networks, while overfitting, can indeed generalize well even on low-dimensional data sets.
Pitfalls of Climate Network Construction: A Statistical Perspective
Nov 17, 2022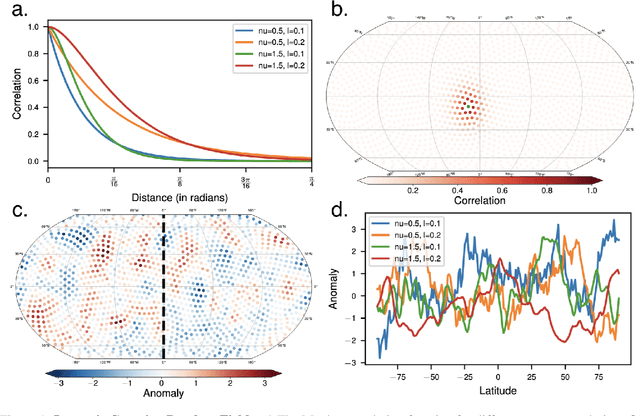

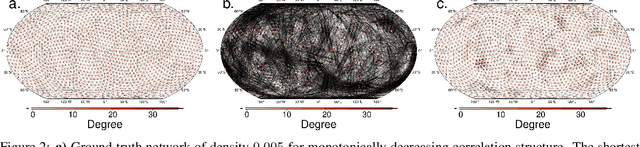
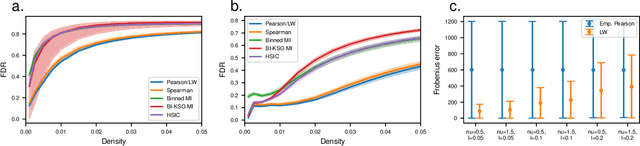
Network-based analyses of dynamical systems have become increasingly popular in climate science. Here we address network construction from a statistical perspective and highlight the often ignored fact that the calculated correlation values are only empirical estimates. To measure spurious behaviour as deviation from a ground truth network, we simulate time-dependent isotropic random fields on the sphere and apply common network construction techniques. We find several ways in which the uncertainty stemming from the estimation procedure has major impact on network characteristics. When the data has locally coherent correlation structure, spurious link bundle teleconnections and spurious high-degree clusters have to be expected. Anisotropic estimation variance can also induce severe biases into empirical networks. We validate our findings with ERA5 reanalysis data. Moreover we explain why commonly applied resampling procedures are inappropriate for significance evaluation and propose a statistically more meaningful ensemble construction framework. By communicating which difficulties arise in estimation from scarce data and by presenting which design decisions increase robustness, we hope to contribute to more reliable climate network construction in the future.
Statistical analysis of Wasserstein GANs with applications to time series forecasting
Nov 05, 2020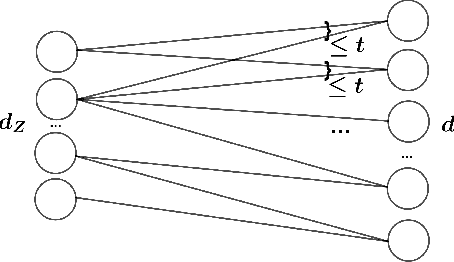
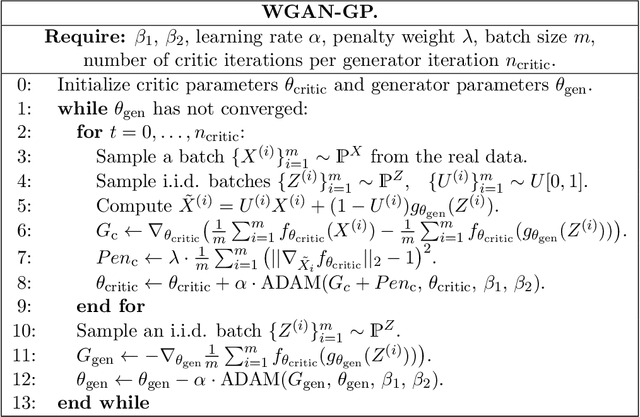
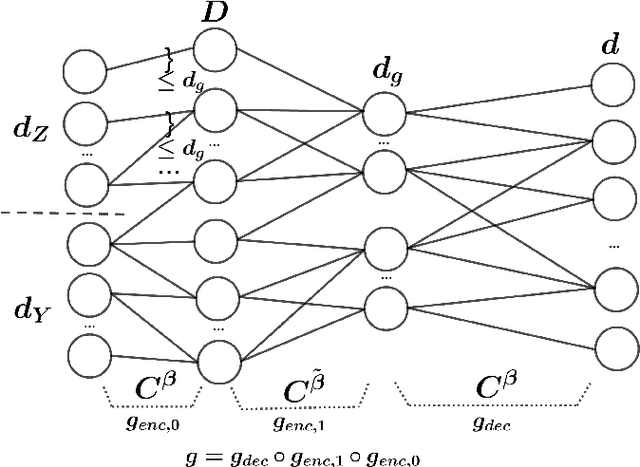
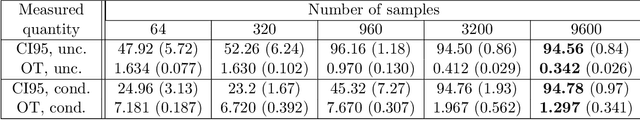
We provide statistical theory for conditional and unconditional Wasserstein generative adversarial networks (WGANs) in the framework of dependent observations. We prove upper bounds for the excess Bayes risk of the WGAN estimators with respect to a modified Wasserstein-type distance. Furthermore, we formalize and derive statements on the weak convergence of the estimators and use them to develop confidence intervals for new observations. The theory is applied to the special case of high-dimensional time series forecasting. We analyze the behavior of the estimators in simulations based on synthetic data and investigate a real data example with temperature data. The dependency of the data is quantified with absolutely regular beta-mixing coefficients.