 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable Feature Attributions: A Bridge between Post Hoc Explainability and Inherent Interpretability
Paper and Code
Jul 27, 2023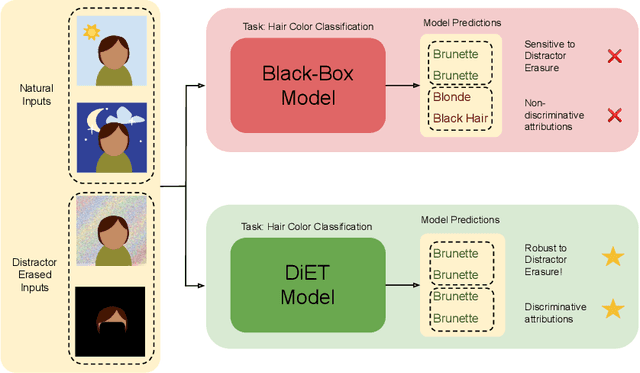

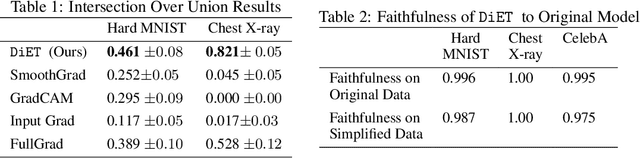
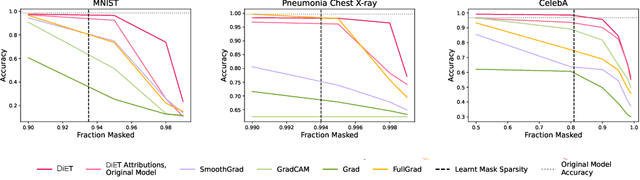
With the increased deployment of machine learning models in various real-world applications, researchers and practitioners alike have emphasized the need for explanations of model behaviour. To this end, two broad strategies have been outlined in prior literature to explain models. Post hoc explanation methods explain the behaviour of complex black-box models by highlighting features that are critical to model predictions; however, prior work has shown that these explanations may not be faithful, and even more concerning is our inability to verify them. Specifically, it is nontrivial to evaluate if a given attribution is correct with respect to the underlying model. Inherently interpretable models, on the other hand, circumvent these issues by explicitly encoding explanations into model architecture, meaning their explanations are naturally faithful and verifiable, but they often exhibit poor predictive performance due to their limited expressive power. In this work, we aim to bridge the gap between the aforementioned strategies by proposing Verifiability Tuning (VerT), a method that transforms black-box models into models that naturally yield faithful and verifiable feature attributions. We begin by introducing a formal theoretical framework to understand verifiability and show that attributions produced by standard models cannot be verified. We then leverage this framework to propose a method to build verifiable models and feature attributions out of fully trained black-box models. Finally, we perform extensive experiments on semi-synthetic and real-world datasets, and show that VerT produces models that (1) yield explanations that are correct and verifiable and (2) are faithful to the original black-box models they are meant to explain.