 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fistful of Words: Learning Transferable Visual Models from Bag-of-Words Supervision
Paper and Code
Jan 06, 2022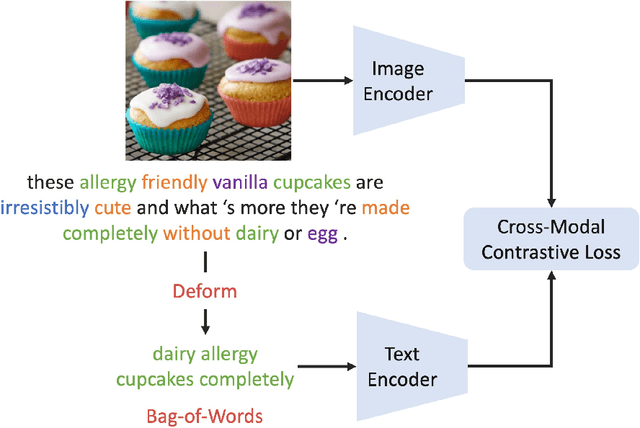
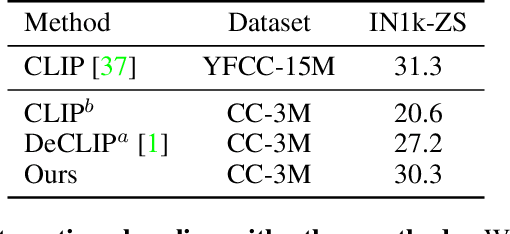

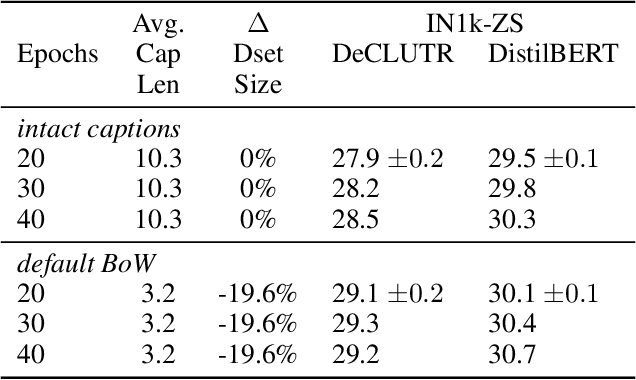
Using natural language as a supervision for training visual recognition models holds great promise. Recent works have shown that if such supervision is used in the form of alignment between images and captions in large training datasets, then the resulting aligned models perform well on zero-shot classification as downstream tasks2. In this paper, we focus on teasing out what parts of the language supervision are essential for training zero-shot image classification models. Through extensive and careful experiments, we show that: 1) A simple Bag-of-Words (BoW) caption could be used as a replacement for most of the image captions in the dataset. Surprisingly, we observe that this approach improves the zero-shot classification performance when combined with word balancing. 2) Using a BoW pretrained model, we can obtain more training data by generating pseudo-BoW captions on images that do not have a caption. Models trained on images with real and pseudo-BoW captions achieve stronger zero-shot performance. On ImageNet-1k zero-shot evaluation, our best model, that uses only 3M image-caption pairs, performs on-par with a CLIP model trained on 15M image-caption pairs (31.5% vs 31.3%).