 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity and Heterogeneous Dropout for Continual Learning in the Null Space of Neural Activations
Paper and Code
Mar 12, 2022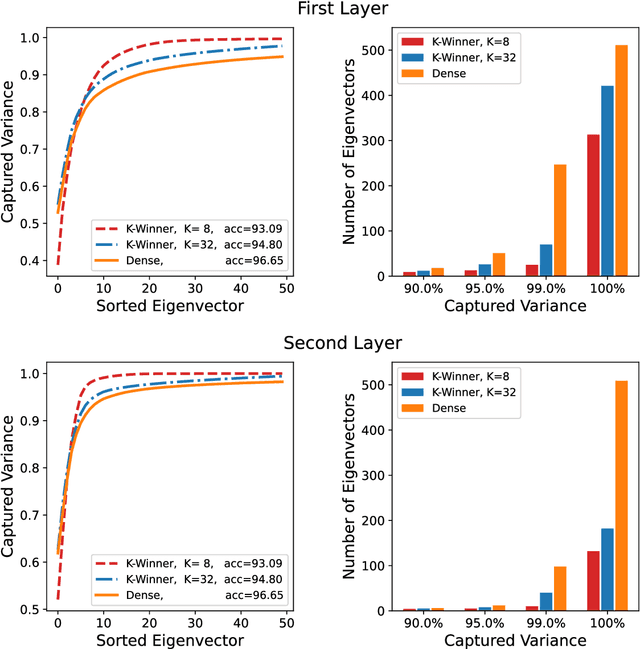

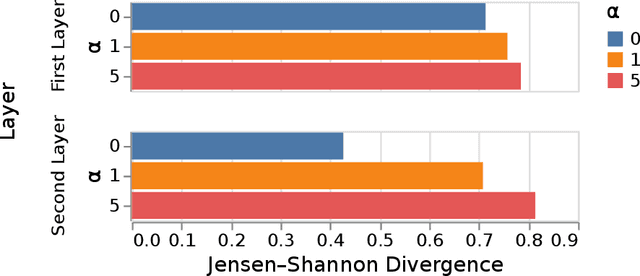

Continual/lifelong learning from a non-stationary input data stream is a cornerstone of intelligence. Despite their phenomenal performance in a wide variety of applications, deep neural networks are prone to forgetting their previously learned information upon learning new ones. This phenomenon is called "catastrophic forgetting" and is deeply rooted in the stability-plasticity dilemma. Overcoming catastrophic forgetting in deep neural networks has become an active field of research in recent years. In particular, gradient projection-based methods have recently shown exceptional performance at overcoming catastrophic forgetting. This paper proposes two biologically-inspired mechanisms based on sparsity and heterogeneous dropout that significantly increase a continual learner's performance over a long sequence of tasks. Our proposed approach builds on the Gradient Projection Memory (GPM) framework. We leverage K-winner activations in each layer of a neural network to enforce layer-wise sparse activations for each task, together with a between-task heterogeneous dropout that encourages the network to use non-overlapping activation patterns between different tasks. In addition, we introduce Continual Swiss Roll as a lightweight and interpretable -- yet challenging -- synthetic benchmark for continual learning. Lastly, we provide an in-depth analysis of our proposed method and demonstrate a significant performance boost on various benchmark continual learning problems.