 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog Anomaly Detection with Large Language Models via Knowledge-Enriched Fusion
Dec 12, 2025System logs are a critical resource for monitoring and managing distributed systems, providing insights into failures and anomalous behavior. Traditional log analysis techniques, including template-based and sequence-driven approaches, often lose important semantic information or struggle with ambiguous log patterns. To address this, we present EnrichLog, a training-free, entry-based anomaly detection framework that enriches raw log entries with both corpus-specific and sample-specific knowledge. EnrichLog incorporates contextual information, including historical examples and reasoning derived from the corpus, to enable more accurate and interpretable anomaly detection. The framework leverages retrieval-augmented generation to integrate relevant contextual knowledge without requiring retraining. We evaluate EnrichLog on four large-scale system log benchmark datasets and compare it against five baseline methods. Our results show that EnrichLog consistently improves anomaly detection performance, effectively handles ambiguous log entries, and maintains efficient inference. Furthermore, incorporating both corpus- and sample-specific knowledge enhances model confidence and detection accuracy, making EnrichLog well-suited for practical deployments.
Dynamic Black-box Backdoor Attacks on IoT Sensory Data
Nov 18, 2025Sensor data-based recognition systems are widely used in various applications, such as gait-based authentication and human activity recognition (HAR). Modern wearable and smart devices feature various built-in Inertial Measurement Unit (IMU) sensors, and such sensor-based measurements can be fed to a machine learning-based model to train and classify human activities. While deep learning-based models have proven successful in classifying human activity and gestures, they pose various security risks. In our paper, we discuss a novel dynamic trigger-generation technique for performing black-box adversarial attacks on sensor data-based IoT systems. Our empirical analysis shows that the attack is successful on various datasets and classifier models with minimal perturbation on the input data. We also provide a detailed comparative analysis of performance and stealthiness to various other poisoning techniques found in backdoor attacks. We also discuss some adversarial defense mechanisms and their impact on the effectiveness of our trigger-generation technique.
Semantically-Aware LLM Agent to Enhance Privacy in Conversational AI Services
Oct 30, 2025With the increasing use of conversational AI systems, there is growing concern over privacy leaks, especially when users share sensitive personal data in interactions with Large Language Models (LLMs). Conversations shared with these models may contain Personally Identifiable Information (PII), which, if exposed, could lead to security breaches or identity theft. To address this challenge, we present the Local Optimizations for Pseudonymization with Semantic Integrity Directed Entity Detection (LOPSIDED) framework, a semantically-aware privacy agent designed to safeguard sensitive PII data when using remote LLMs. Unlike prior work that often degrade response quality, our approach dynamically replaces sensitive PII entities in user prompts with semantically consistent pseudonyms, preserving the contextual integrity of conversations. Once the model generates its response, the pseudonyms are automatically depseudonymized, ensuring the user receives an accurate, privacy-preserving output. We evaluate our approach using real-world conversations sourced from ShareGPT, which we further augment and annotate to assess whether named entities are contextually relevant to the model's response. Our results show that LOPSIDED reduces semantic utility errors by a factor of 5 compared to baseline techniques, all while enhancing privacy.
Dynamic User-controllable Privacy-preserving Few-shot Sensing Framework
Aug 06, 2025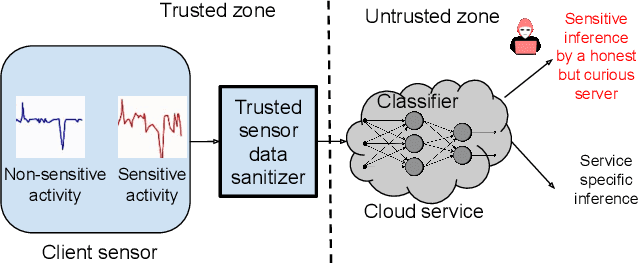

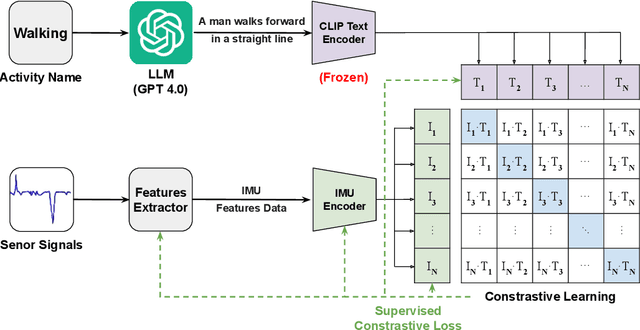

User-controllable privacy is important in modern sensing systems, as privacy preferences can vary significantly from person to person and may evolve over time. This is especially relevant in devices equipped with Inertial Measurement Unit (IMU) sensors, such as smartphones and wearables, which continuously collect rich time-series data that can inadvertently expose sensitive user behaviors. While prior work has proposed privacy-preserving methods for sensor data, most rely on static, predefined privacy labels or require large quantities of private training data, limiting their adaptability and user agency. In this work, we introduce PrivCLIP, a dynamic, user-controllable, few-shot privacy-preserving sensing framework. PrivCLIP allows users to specify and modify their privacy preferences by categorizing activities as sensitive (black-listed), non-sensitive (white-listed), or neutral (gray-listed). Leveraging a multimodal contrastive learning approach, PrivCLIP aligns IMU sensor data with natural language activity descriptions in a shared embedding space, enabling few-shot detection of sensitive activities. When a privacy-sensitive activity is identified, the system uses a language-guided activity sanitizer and a motion generation module (IMU-GPT) to transform the original data into a privacy-compliant version that semantically resembles a non-sensitive activity. We evaluate PrivCLIP on multiple human activity recognition datasets and demonstrate that it significantly outperforms baseline methods in terms of both privacy protection and data utility.
PCAP-Backdoor: Backdoor Poisoning Generator for Network Traffic in CPS/IoT Environments
Jan 26, 2025The rapid expansion of connected devices has made them prime targets for cyberattacks. To address these threats, deep learning-based, data-driven intrusion detection systems (IDS) have emerged as powerful tools for detecting and mitigating such attacks. These IDSs analyze network traffic to identify unusual patterns and anomalies that may indicate potential security breaches. However, prior research has shown that deep learning models are vulnerable to backdoor attacks, where attackers inject triggers into the model to manipulate its behavior and cause misclassifications of network traffic. In this paper, we explore the susceptibility of deep learning-based IDS systems to backdoor attacks in the context of network traffic analysis. We introduce \texttt{PCAP-Backdoor}, a novel technique that facilitates backdoor poisoning attacks on PCAP datasets. Our experiments on real-world Cyber-Physical Systems (CPS) and Internet of Things (IoT) network traffic datasets demonstrate that attackers can effectively backdoor a model by poisoning as little as 1\% or less of the entire training dataset. Moreover, we show that an attacker can introduce a trigger into benign traffic during model training yet cause the backdoored model to misclassify malicious traffic when the trigger is present. Finally, we highlight the difficulty of detecting this trigger-based backdoor, even when using existing backdoor defense techniques.
BaboonLand Dataset: Tracking Primates in the Wild and Automating Behaviour Recognition from Drone Videos
May 29, 2024



Using drones to track multiple individuals simultaneously in their natural environment is a powerful approach for better understanding group primate behavior. Previous studies have demonstrated that it is possible to automate the classification of primate behavior from video data, but these studies have been carried out in captivity or from ground-based cameras. To understand group behavior and the self-organization of a collective, the whole troop needs to be seen at a scale where behavior can be seen in relation to the natural environment in which ecological decisions are made. This study presents a novel dataset from drone videos for baboon detection, tracking, and behavior recognition. The baboon detection dataset was created by manually annotating all baboons in drone videos with bounding boxes. A tiling method was subsequently applied to create a pyramid of images at various scales from the original 5.3K resolution images, resulting in approximately 30K images used for baboon detection. The tracking dataset is derived from the detection dataset, where all bounding boxes are assigned the same ID throughout the video. This process resulted in half an hour of very dense tracking data. The behavior recognition dataset was generated by converting tracks into mini-scenes, a video subregion centered on each animal; each mini-scene was manually annotated with 12 distinct behavior types, resulting in over 20 hours of data. Benchmark results show mean average precision (mAP) of 92.62\% for the YOLOv8-X detection model, multiple object tracking precision (MOTA) of 63.81\% for the BotSort tracking algorithm, and micro top-1 accuracy of 63.97\% for the X3D behavior recognition model. Using deep learning to classify wildlife behavior from drone footage facilitates non-invasive insight into the collective behavior of an entire group.
Streaming Video Analytics On The Edge With Asynchronous Cloud Support
Oct 04, 2022


Emerging Internet of Things (IoT) and mobile computing applications are expected to support latency-sensitive deep neural network (DNN) workloads. To realize this vision, the Internet is evolving towards an edge-computing architecture, where computing infrastructure is located closer to the end device to help achieve low latency. However, edge computing may have limited resources compared to cloud environments and thus, cannot run large DNN models that often have high accuracy. In this work, we develop REACT, a framework that leverages cloud resources to execute large DNN models with higher accuracy to improve the accuracy of models running on edge devices. To do so, we propose a novel edge-cloud fusion algorithm that fuses edge and cloud predictions, achieving low latency and high accuracy. We extensively evaluate our approach and show that our approach can significantly improve the accuracy compared to baseline approaches. We focus specifically on object detection in videos (applicable in many video analytics scenarios) and show that the fused edge-cloud predictions can outperform the accuracy of edge-only and cloud-only scenarios by as much as 50%. We also show that REACT can achieve good performance across tradeoff points by choosing a wide range of system parameters to satisfy use-case specific constraints, such as limited network bandwidth or GPU cycles.
sat2pc: Estimating Point Cloud of Building Roofs from 2D Satellite Images
May 25, 2022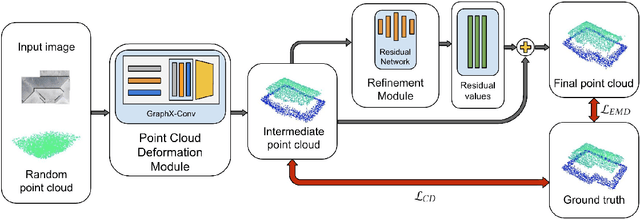



Three-dimensional (3D) urban models have gained interest because of their applications in many use-cases such as urban planning and virtual reality. However, generating these 3D representations requires LiDAR data, which are not always readily available. Thus, the applicability of automated 3D model generation algorithms is limited to a few locations. In this paper, we propose sat2pc, a deep learning architecture that predicts the point cloud of a building roof from a single 2D satellite image. Our architecture combines Chamfer distance and EMD loss, resulting in better 2D to 3D performance. We extensively evaluate our model and perform ablation studies on a building roof dataset. Our results show that sat2pc was able to outperform existing baselines by at least 18.6%. Further, we show that the predicted point cloud captures more detail and geometric characteristics than other baselines.
Energy-Efficient Parking Analytics System using Deep Reinforcement Learning
Feb 15, 2022
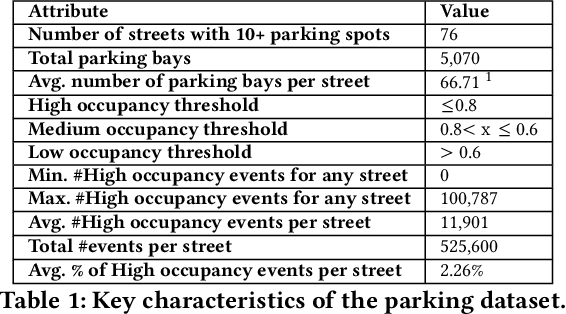

Advances in deep vision techniques and ubiquity of smart cameras will drive the next generation of video analytics. However, video analytics applications consume vast amounts of energy as both deep learning techniques and cameras are power-hungry. In this paper, we focus on a parking video analytics platform and propose RL-CamSleep, a deep reinforcement learning-based technique, to actuate the cameras to reduce the energy footprint while retaining the system's utility. Our key insight is that many video-analytics applications do not always need to be operational, and we can design policies to activate video analytics only when necessary. Moreover, our work is complementary to existing work that focuses on improving hardware and software efficiency. We evaluate our approach on a city-scale parking dataset having 76 streets spread across the city. Our analysis demonstrates how streets have various parking patterns, highlighting the importance of an adaptive policy. Our approach can learn such an adaptive policy that can reduce the average energy consumption by 76.38% and achieve an average accuracy of more than 98% in performing video analytics.
Federated Intrusion Detection for IoT with Heterogeneous Cohort Privacy
Jan 25, 2021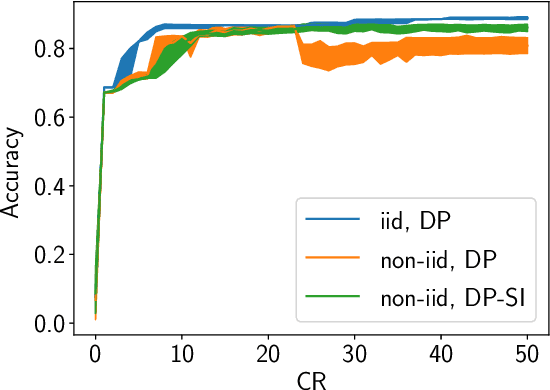

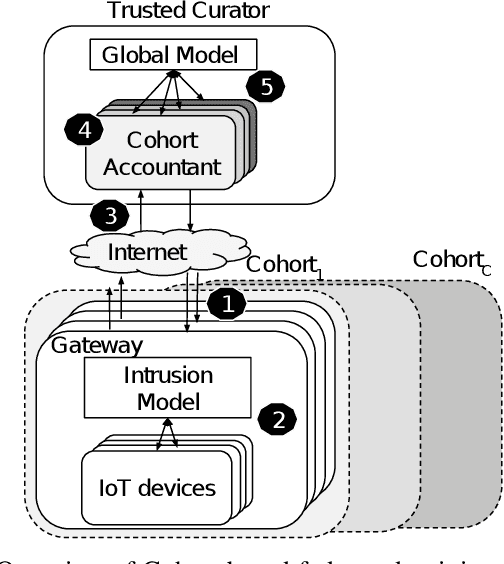
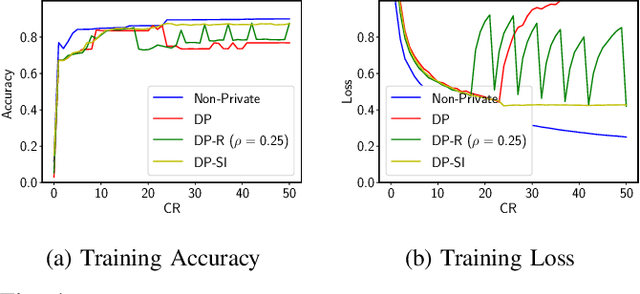
Internet of Things (IoT) devices are becoming increasingly popular and are influencing many application domains such as healthcare and transportation. These devices are used for real-world applications such as sensor monitoring, real-time control. In this work, we look at differentially private (DP) neural network (NN) based network intrusion detection systems (NIDS) to detect intrusion attacks on networks of such IoT devices. Existing NN training solutions in this domain either ignore privacy considerations or assume that the privacy requirements are homogeneous across all users. We show that the performance of existing differentially private stochastic methods degrade for clients with non-identical data distributions when clients' privacy requirements are heterogeneous. We define a cohort-based $(\epsilon,\delta)$-DP framework that models the more practical setting of IoT device cohorts with non-identical clients and heterogeneous privacy requirements. We propose two novel continual-learning based DP training methods that are designed to improve model performance in the aforementioned setting. To the best of our knowledge, ours is the first system that employs a continual learning-based approach to handle heterogeneity in client privacy requirements. We evaluate our approach on real datasets and show that our techniques outperform the baselines. We also show that our methods are robust to hyperparameter changes. Lastly, we show that one of our proposed methods can easily adapt to post-hoc relaxations of client privacy requirements.