 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Don't You Click: Neural Correlates of Non-Click Behaviors in Web Search
Sep 22, 2021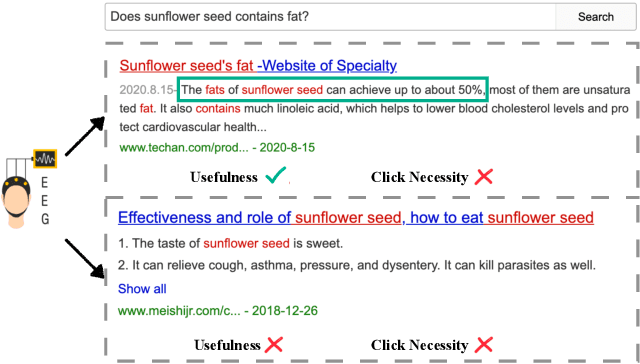

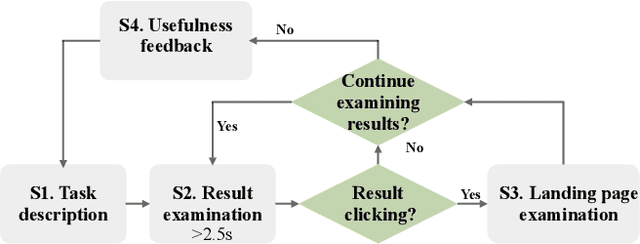
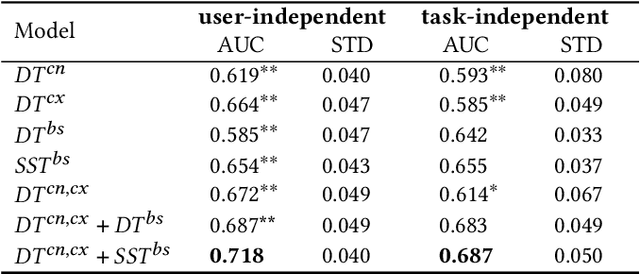
Web search heavily relies on click-through behavior as an essential feedback signal for performance improvement and evaluation. Traditionally, click is usually treated as a positive implicit feedback signal of relevance or usefulness, while non-click (especially non-click after examination) is regarded as a signal of irrelevance or uselessness. However, there are many cases where users do not click on any search results but still satisfy their information need with the contents of the results shown on the Search Engine Result Page (SERP). This raises the problem of measuring result usefulness and modeling user satisfaction in "Zero-click" search scenarios. Previous works have solved this issue by (1) detecting user satisfaction for abandoned SERP with context information and (2) considering result-level click necessity with external assessors' annotations. However, few works have investigated the reason behind non-click behavior and estimated the usefulness of non-click results. A challenge for this research question is how to collect valuable feedback for non-click results. With neuroimaging technologies, we design a lab-based user study and reveal differences in brain signals while examining non-click search results with different usefulness levels. The findings in significant brain regions and electroencephalogram~(EEG) spectrum also suggest that the process of usefulness judgment might involve similar cognitive functions of relevance perception and satisfaction decoding. Inspired by these findings, we conduct supervised learning tasks to estimate the usefulness of non-click results with brain signals and conventional information (i.e., content and context factors). Results show that it is feasible to utilize brain signals to improve usefulness estimation performance and enhancing human-computer interactions in "Zero-click" search scenarios.
Making Contextual Decisions with Low Technical Debt
May 09, 2017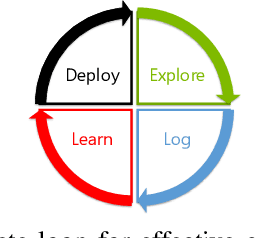
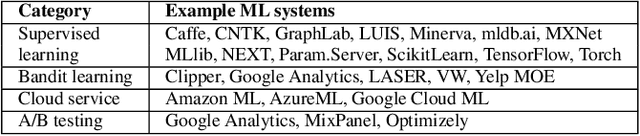

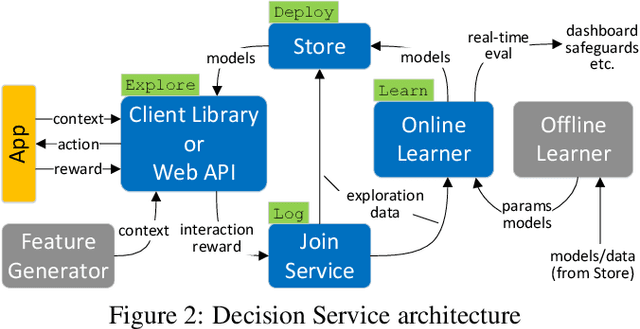
Applications and systems are constantly faced with decisions that require picking from a set of actions based on contextual information. Reinforcement-based learning algorithms such as contextual bandits can be very effective in these settings, but applying them in practice is fraught with technical debt, and no general system exists that supports them completely. We address this and create the first general system for contextual learning, called the Decision Service. Existing systems often suffer from technical debt that arises from issues like incorrect data collection and weak debuggability, issues we systematically address through our ML methodology and system abstractions. The Decision Service enables all aspects of contextual bandit learning using four system abstractions which connect together in a loop: explore (the decision space), log, learn, and deploy. Notably, our new explore and log abstractions ensure the system produces correct, unbiased data, which our learner uses for online learning and to enable real-time safeguards, all in a fully reproducible manner. The Decision Service has a simple user interface and works with a variety of applications: we present two live production deployments for content recommendation that achieved click-through improvements of 25-30%, another with 18% revenue lift in the landing page, and ongoing applications in tech support and machine failure handling. The service makes real-time decisions and learns continuously and scalably, while significantly lowering technical debt.