 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Multi-Resolution Procedural Knowledge Compression for Large Language Models
Jun 10, 2026Large language models (LLMs) are widely used to tackle complex tasks with autonomous workflows. Recently, reusable natural language skills have emerged as a popular paradigm to inject procedural knowledge into LLM applications. Since popular skills are often invoked repeatedly, placing their full text in every context significantly increases prefill cost and latency. While text compression techniques have the potential to solve this problem, most existing methods are designed to compress factual knowledge in documents instead of procedural knowledge, making them insufficient for skill compression. In this paper, we argue that an effective skill compression method should: 1) preserve logical dependencies among workflows and tool protocols, 2) enable lightweight, offline compression for frequently updated community skills, and 3) be adaptable to varying complexities across skills. To address this, we present SKIM (SKIll coMpression), an adaptive multi-resolution soft token compression framework for procedural skills. Depending on the complexity of each skill, SKIM creates different numbers of soft tokens that not only improve the efficiency of LLM inference, but also preserve the effectiveness of skill usage. Experiments indicate that SKIM compresses skills to 30 to 60 percent of their original token length while preserving task performance better than existing compression methods.We have released our code at https://github.com/bebr2/SKIM .
ATACompressor: Adaptive Task-Aware Compression for Efficient Long-Context Processing in LLMs
Feb 03, 2026Long-context inputs in large language models (LLMs) often suffer from the "lost in the middle" problem, where critical information becomes diluted or ignored due to excessive length. Context compression methods aim to address this by reducing input size, but existing approaches struggle with balancing information preservation and compression efficiency. We propose Adaptive Task-Aware Compressor (ATACompressor), which dynamically adjusts compression based on the specific requirements of the task. ATACompressor employs a selective encoder that compresses only the task-relevant portions of long contexts, ensuring that essential information is preserved while reducing unnecessary content. Its adaptive allocation controller perceives the length of relevant content and adjusts the compression rate accordingly, optimizing resource utilization. We evaluate ATACompressor on three QA datasets: HotpotQA, MSMARCO, and SQUAD-showing that it outperforms existing methods in terms of both compression efficiency and task performance. Our approach provides a scalable solution for long-context processing in LLMs. Furthermore, we perform a range of ablation studies and analysis experiments to gain deeper insights into the key components of ATACompressor.
Beyond Exposure: Optimizing Ranking Fairness with Non-linear Time-Income Functions
Feb 03, 2026Ranking is central to information distribution in web search and recommendation. Nowadays, in ranking optimization, the fairness to item providers is viewed as a crucial factor alongside ranking relevance for users. There are currently numerous concepts of fairness and one widely recognized fairness concept is Exposure Fairness. However, it relies primarily on exposure determined solely by position, overlooking other factors that significantly influence income, such as time. To address this limitation, we propose to study ranking fairness when the provider utility is influenced by other contextual factors and is neither equal to nor proportional to item exposure. We give a formal definition of Income Fairness and develop a corresponding measurement metric. Simulated experiments show that existing-exposure-fairness-based ranking algorithms fail to optimize the proposed income fairness. Therefore, we propose the Dynamic-Income-Derivative-aware Ranking Fairness algorithm, which, based on the marginal income gain at the present timestep, uses Taylor-expansion-based gradients to simultaneously optimize effectiveness and income fairness. In both offline and online settings with diverse time-income functions, DIDRF consistently outperforms state-of-the-art methods.
Beyond Experience Retrieval: Learning to Generate Utility-Optimized Structured Experience for Frozen LLMs
Jan 30, 2026Large language models (LLMs) are largely static and often redo reasoning or repeat mistakes. Prior experience reuse typically relies on external retrieval, which is similarity-based, can introduce noise, and adds latency. We introduce SEAM (Structured Experience Adapter Module), a lightweight, executor-specific plug-in that stores experience in its parameters and generates a structured, instance-tailored experience entry in a single forward pass to guide a frozen LLM executor. SEAM is trained for utility via executor rollouts and GRPO while keeping the executor frozen, and it can be further improved after deployment with supervised fine-tuning on logged successful trajectories. Experiments on mathematical reasoning benchmarks show consistent accuracy gains across executors with low overhead. Extensive ablations and analyses further elucidate the mechanisms underlying SEAM's effectiveness and robustness.
MulFeRL: Enhancing Reinforcement Learning with Verbal Feedback in a Multi-turn Loop
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is widely used to improve reasoning in multiple domains, yet outcome-only scalar rewards are often sparse and uninformative, especially on failed samples, where they merely indicate failure and provide no insight into why the reasoning fails. In this paper, we investigate how to leverage richer verbal feedback to guide RLVR training on failed samples, and how to convert such feedback into a trainable learning signal. Specifically, we propose a multi-turn feedback-guided reinforcement learning framework. It builds on three mechanisms: (1) dynamic multi-turn regeneration guided by feedback, triggered only on failed samples, (2) two complementary learning signals for within-turn and cross-turn optimization, and (3) structured feedback injection into the model's reasoning process. Trained on sampled OpenR1-Math, the approach outperforms supervised fine-tuning and RLVR baselines in-domain and generalizes well out-of-domain.
Why Don't You Click: Neural Correlates of Non-Click Behaviors in Web Search
Sep 22, 2021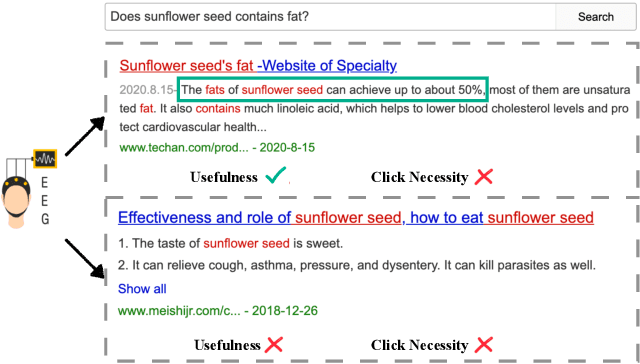

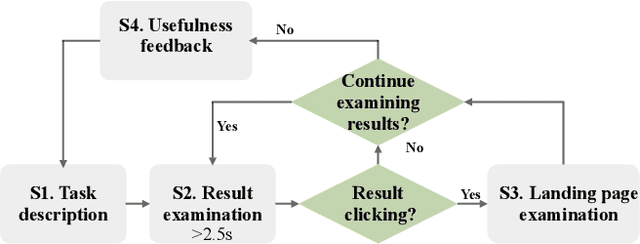
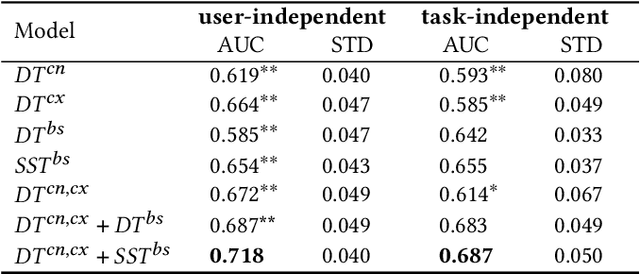
Web search heavily relies on click-through behavior as an essential feedback signal for performance improvement and evaluation. Traditionally, click is usually treated as a positive implicit feedback signal of relevance or usefulness, while non-click (especially non-click after examination) is regarded as a signal of irrelevance or uselessness. However, there are many cases where users do not click on any search results but still satisfy their information need with the contents of the results shown on the Search Engine Result Page (SERP). This raises the problem of measuring result usefulness and modeling user satisfaction in "Zero-click" search scenarios. Previous works have solved this issue by (1) detecting user satisfaction for abandoned SERP with context information and (2) considering result-level click necessity with external assessors' annotations. However, few works have investigated the reason behind non-click behavior and estimated the usefulness of non-click results. A challenge for this research question is how to collect valuable feedback for non-click results. With neuroimaging technologies, we design a lab-based user study and reveal differences in brain signals while examining non-click search results with different usefulness levels. The findings in significant brain regions and electroencephalogram~(EEG) spectrum also suggest that the process of usefulness judgment might involve similar cognitive functions of relevance perception and satisfaction decoding. Inspired by these findings, we conduct supervised learning tasks to estimate the usefulness of non-click results with brain signals and conventional information (i.e., content and context factors). Results show that it is feasible to utilize brain signals to improve usefulness estimation performance and enhancing human-computer interactions in "Zero-click" search scenarios.