 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivFT: Private and Fast Text Classification with Homomorphic Encryption
Aug 19, 2019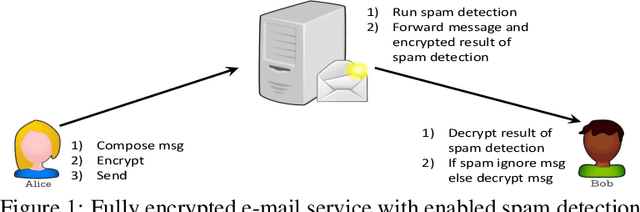

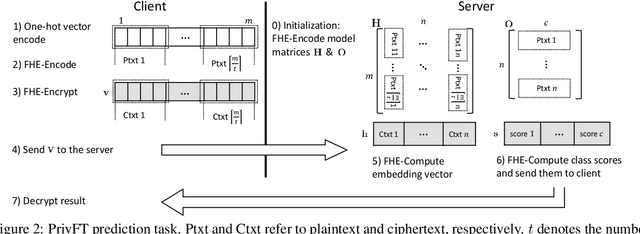
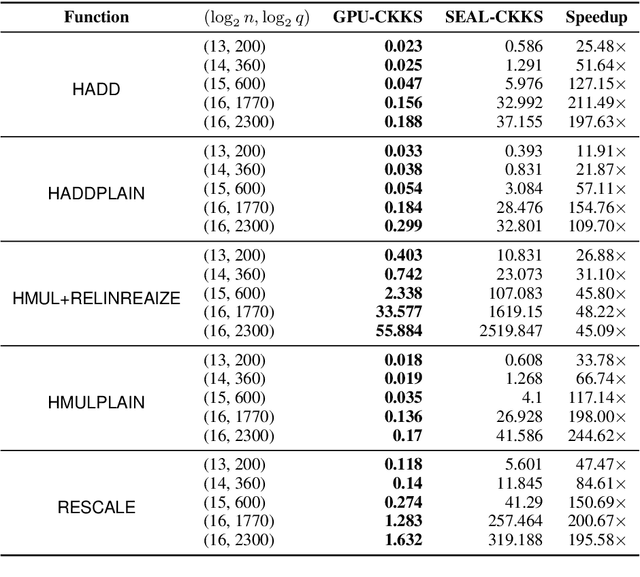
Privacy and security have increasingly become a concern for computing services in recent years. In this work, we present an efficient method for Text Classification while preserving the privacy of the content, using Fully Homomorphic Encryption (FHE). We train a simple supervised model on unencrypted data to achieve competitive results with recent approaches and outline a system for performing inferences directly on encrypted data with zero loss to prediction accuracy. This system is implemented with GPU hardware acceleration to achieve a run time per inference of less than 0.66 seconds, resulting in more than 12$\times$ speedup over its CPU counterpart. Finally, we show how to train this model from scratch using fully encrypted data to generate an encrypted model.
Making Contextual Decisions with Low Technical Debt
May 09, 2017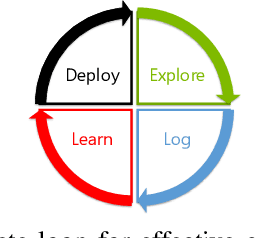
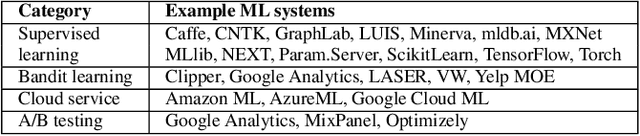

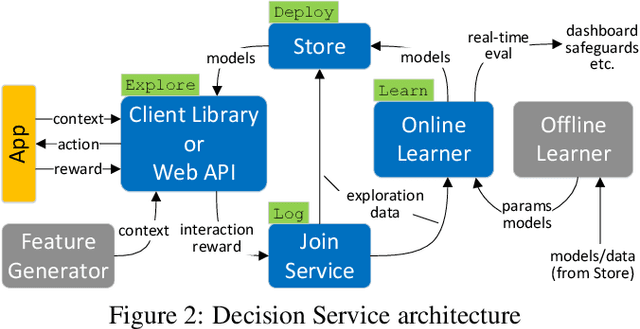
Applications and systems are constantly faced with decisions that require picking from a set of actions based on contextual information. Reinforcement-based learning algorithms such as contextual bandits can be very effective in these settings, but applying them in practice is fraught with technical debt, and no general system exists that supports them completely. We address this and create the first general system for contextual learning, called the Decision Service. Existing systems often suffer from technical debt that arises from issues like incorrect data collection and weak debuggability, issues we systematically address through our ML methodology and system abstractions. The Decision Service enables all aspects of contextual bandit learning using four system abstractions which connect together in a loop: explore (the decision space), log, learn, and deploy. Notably, our new explore and log abstractions ensure the system produces correct, unbiased data, which our learner uses for online learning and to enable real-time safeguards, all in a fully reproducible manner. The Decision Service has a simple user interface and works with a variety of applications: we present two live production deployments for content recommendation that achieved click-through improvements of 25-30%, another with 18% revenue lift in the landing page, and ongoing applications in tech support and machine failure handling. The service makes real-time decisions and learns continuously and scalably, while significantly lowering technical debt.
Structured Attention Networks
Feb 16, 2017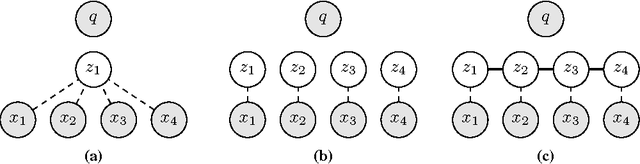

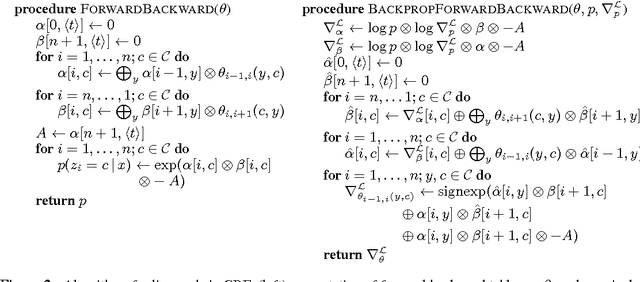

Attention networks have proven to be an effective approach for embedding categorical inference within a deep neural network. However, for many tasks we may want to model richer structural dependencies without abandoning end-to-end training. In this work, we experiment with incorporating richer structural distributions, encoded using graphical models, within deep networks. We show that these structured attention networks are simple extensions of the basic attention procedure, and that they allow for extending attention beyond the standard soft-selection approach, such as attending to partial segmentations or to subtrees. We experiment with two different classes of structured attention networks: a linear-chain conditional random field and a graph-based parsing model, and describe how these models can be practically implemented as neural network layers. Experiments show that this approach is effective for incorporating structural biases, and structured attention networks outperform baseline attention models on a variety of synthetic and real tasks: tree transduction, neural machine translation, question answering, and natural language inference. We further find that models trained in this way learn interesting unsupervised hidden representations that generalize simple attention.