 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrading Off Diversity and Quality in Natural Language Generation
Paper and Code
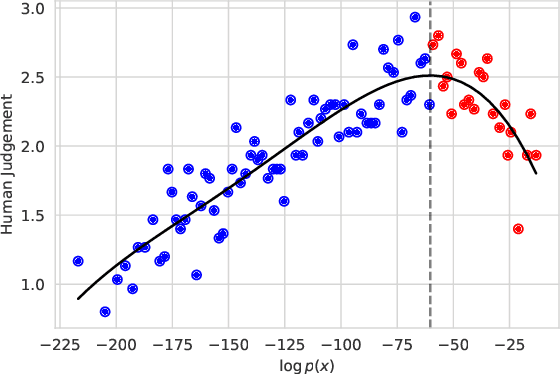

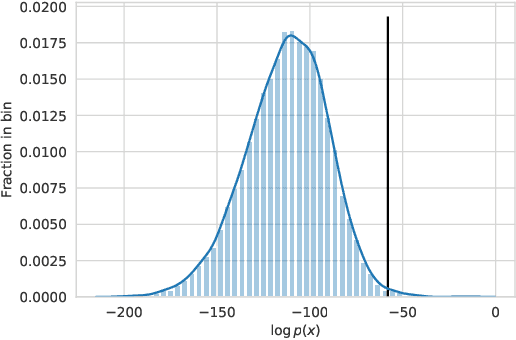
For open-ended language generation tasks such as storytelling and dialogue, choosing the right decoding algorithm is critical to controlling the tradeoff between generation quality and diversity. However, there presently exists no consensus on which decoding procedure is best or even the criteria by which to compare them. We address these issues by casting decoding as a multi-objective optimization problem aiming to simultaneously maximize both response quality and diversity. Our framework enables us to perform the first large-scale evaluation of decoding methods along the entire quality-diversity spectrum. We find that when diversity is a priority, all methods perform similarly, but when quality is viewed as more important, the recently proposed nucleus sampling (Holtzman et al. 2019) outperforms all other evaluated decoding algorithms. Our experiments also confirm the existence of the `likelihood trap', the counter-intuitive observation that high likelihood sequences are often surprisingly low quality. We leverage our findings to create and evaluate an algorithm called \emph{selective sampling} which tractably approximates globally-normalized temperature sampling.