 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems
Dec 27, 2020
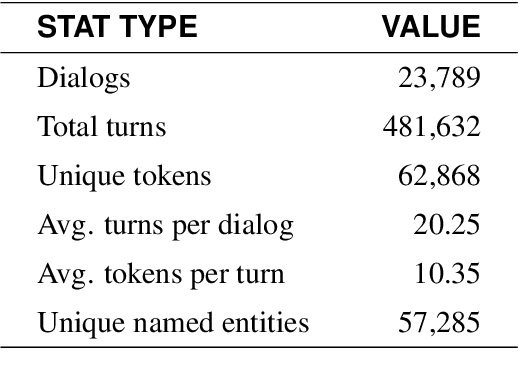


We present a data-driven, end-to-end approach to transaction-based dialog systems that performs at near-human levels in terms of verbal response quality and factual grounding accuracy. We show that two essential components of the system produce these results: a sufficiently large and diverse, in-domain labeled dataset, and a neural network-based, pre-trained model that generates both verbal responses and API call predictions. In terms of data, we introduce TicketTalk, a movie ticketing dialog dataset with 23,789 annotated conversations. The movie ticketing conversations range from completely open-ended and unrestricted to more structured, both in terms of their knowledge base, discourse features, and number of turns. In qualitative human evaluations, model-generated responses trained on just 10,000 TicketTalk dialogs were rated to "make sense" 86.5 percent of the time, almost the same as human responses in the same contexts. Our simple, API-focused annotation schema results in a much easier labeling task making it faster and more cost effective. It is also the key component for being able to predict API calls accurately. We handle factual grounding by incorporating API calls in the training data, allowing our model to learn which actions to take and when. Trained on the same 10,000-dialog set, the model's API call predictions were rated to be correct 93.9 percent of the time in our evaluations, surpassing the ratings for the corresponding human labels. We show how API prediction and response generation scores improve as the dataset size incrementally increases from 5000 to 21,000 dialogs. Our analysis also clearly illustrates the benefits of pre-training. We are publicly releasing the TicketTalk dataset with this paper to facilitate future work on transaction-based dialogs.
Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset
Sep 01, 2019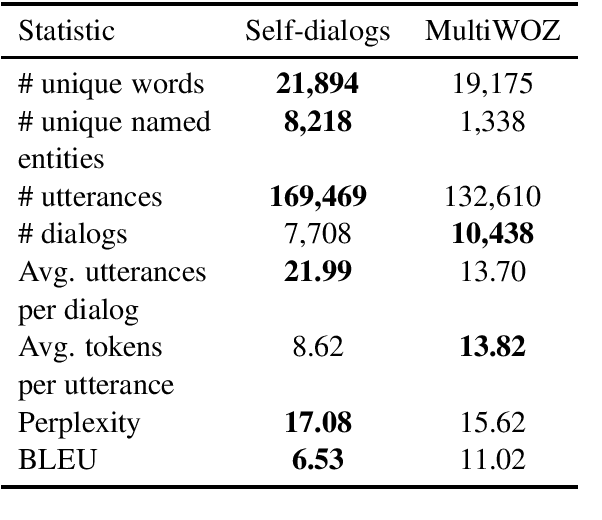

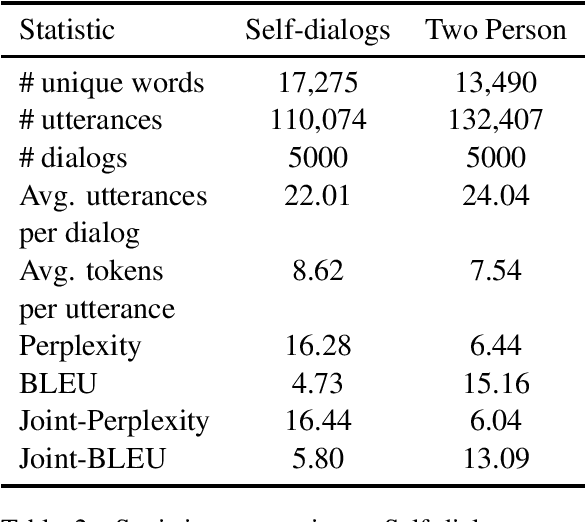
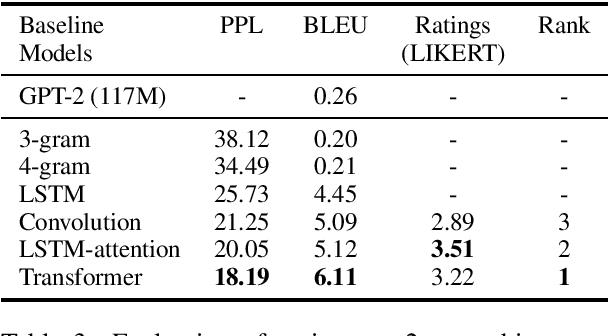
A significant barrier to progress in data-driven approaches to building dialog systems is the lack of high quality, goal-oriented conversational data. To help satisfy this elementary requirement, we introduce the initial release of the Taskmaster-1 dataset which includes 13,215 task-based dialogs comprising six domains. Two procedures were used to create this collection, each with unique advantages. The first involves a two-person, spoken "Wizard of Oz" (WOz) approach in which trained agents and crowdsourced workers interact to complete the task while the second is "self-dialog" in which crowdsourced workers write the entire dialog themselves. We do not restrict the workers to detailed scripts or to a small knowledge base and hence we observe that our dataset contains more realistic and diverse conversations in comparison to existing datasets. We offer several baseline models including state of the art neural seq2seq architectures with benchmark performance as well as qualitative human evaluations. Dialogs are labeled with API calls and arguments, a simple and cost effective approach which avoids the requirement of complex annotation schema. The layer of abstraction between the dialog model and the service provider API allows for a given model to interact with multiple services that provide similar functionally. Finally, the dataset will evoke interest in written vs. spoken language, discourse patterns, error handling and other linguistic phenomena related to dialog system research, development and design.