 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICP-4D: Bridging Iterative Closest Point and LiDAR Panoptic Segmentation
Dec 22, 2025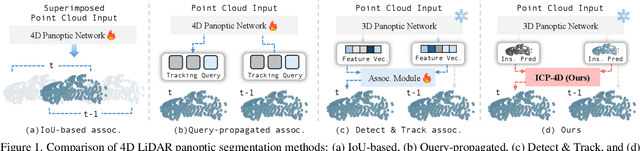
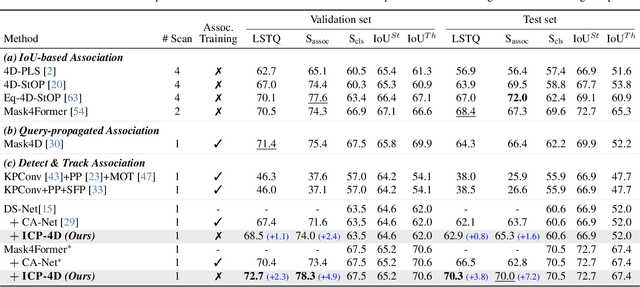
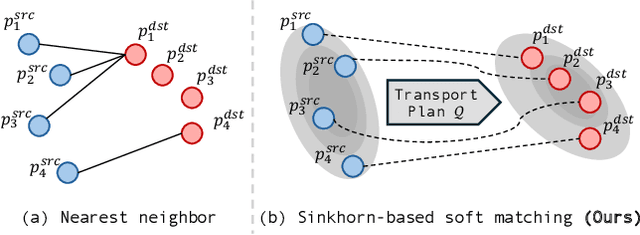
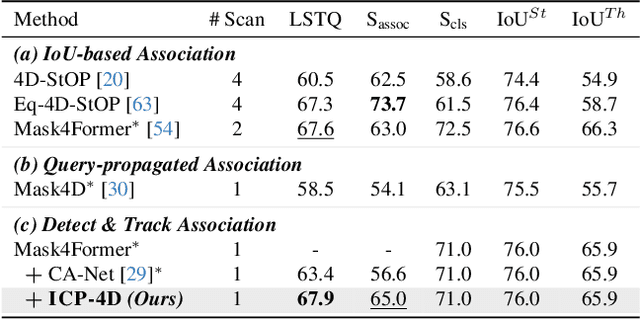
Dominant paradigms for 4D LiDAR panoptic segmentation are usually required to train deep neural networks with large superimposed point clouds or design dedicated modules for instance association. However, these approaches perform redundant point processing and consequently become computationally expensive, yet still overlook the rich geometric priors inherently provided by raw point clouds. To this end, we introduce ICP-4D, a simple yet effective training-free framework that unifies spatial and temporal reasoning through geometric relations among instance-level point sets. Specifically, we apply the Iterative Closest Point (ICP) algorithm to directly associate temporally consistent instances by aligning the source and target point sets through the estimated transformation. To stabilize association under noisy instance predictions, we introduce a Sinkhorn-based soft matching. This exploits the underlying instance distribution to obtain accurate point-wise correspondences, resulting in robust geometric alignment. Furthermore, our carefully designed pipeline, which considers three instance types-static, dynamic, and missing-offers computational efficiency and occlusion-aware matching. Our extensive experiments across both SemanticKITTI and panoptic nuScenes demonstrate that our method consistently outperforms state-of-the-art approaches, even without additional training or extra point cloud inputs.
CompMarkGS: Robust Watermarking for Compression 3D Gaussian Splatting
Mar 17, 20253D Gaussian Splatting (3DGS) enables rapid differentiable rendering for 3D reconstruction and novel view synthesis, leading to its widespread commercial use. Consequently, copyright protection via watermarking has become critical. However, because 3DGS relies on millions of Gaussians, which require gigabytes of storage, efficient transfer and storage require compression. Existing 3DGS watermarking methods are vulnerable to quantization-based compression, often resulting in the loss of the embedded watermark. To address this challenge, we propose a novel watermarking method that ensures watermark robustness after model compression while maintaining high rendering quality. In detail, we incorporate a quantization distortion layer that simulates compression during training, preserving the watermark under quantization-based compression. Also, we propose a learnable watermark embedding feature that embeds the watermark into the anchor feature, ensuring structural consistency and seamless integration into the 3D scene. Furthermore, we present a frequency-aware anchor growing mechanism to enhance image quality in high-frequency regions by effectively identifying Guassians within these regions. Experimental results confirm that our method preserves the watermark and maintains superior image quality under high compression, validating it as a promising approach for a secure 3DGS model.
LVMark: Robust Watermark for latent video diffusion models
Dec 12, 2024Rapid advancements in generative models have made it possible to create hyper-realistic videos. As their applicability increases, their unauthorized use has raised significant concerns, leading to the growing demand for techniques to protect the ownership of the generative model itself. While existing watermarking methods effectively embed watermarks into image-generative models, they fail to account for temporal information, resulting in poor performance when applied to video-generative models. To address this issue, we introduce a novel watermarking method called LVMark, which embeds watermarks into video diffusion models. A key component of LVMark is a selective weight modulation strategy that efficiently embeds watermark messages into the video diffusion model while preserving the quality of the generated videos. To accurately decode messages in the presence of malicious attacks, we design a watermark decoder that leverages spatio-temporal information in the 3D wavelet domain through a cross-attention module. To the best of our knowledge, our approach is the first to highlight the potential of video-generative model watermarking as a valuable tool for enhancing the effectiveness of ownership protection in video-generative models.
WateRF: Robust Watermarks in Radiance Fields for Protection of Copyrights
May 03, 2024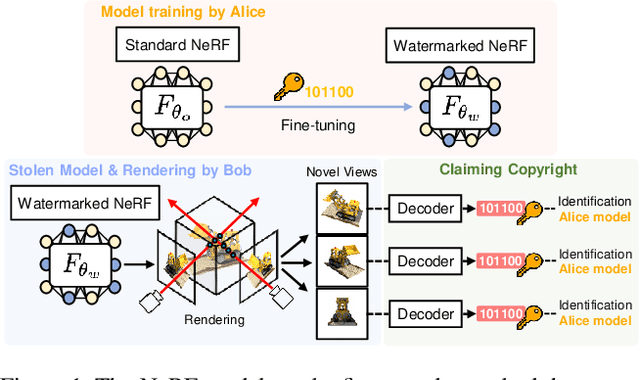
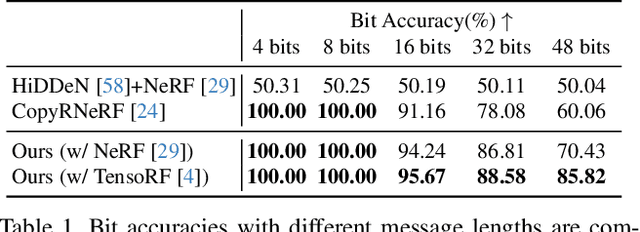
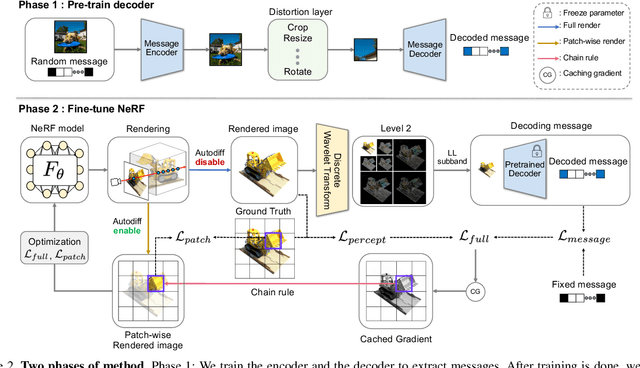
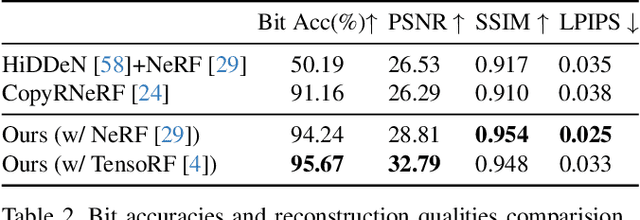
The advances in the Neural Radiance Fields (NeRF) research offer extensive applications in diverse domains, but protecting their copyrights has not yet been researched in depth. Recently, NeRF watermarking has been considered one of the pivotal solutions for safely deploying NeRF-based 3D representations. However, existing methods are designed to apply only to implicit or explicit NeRF representations. In this work, we introduce an innovative watermarking method that can be employed in both representations of NeRF. This is achieved by fine-tuning NeRF to embed binary messages in the rendering process. In detail, we propose utilizing the discrete wavelet transform in the NeRF space for watermarking. Furthermore, we adopt a deferred back-propagation technique and introduce a combination with the patch-wise loss to improve rendering quality and bit accuracy with minimum trade-offs. We evaluate our method in three different aspects: capacity, invisibility, and robustness of the embedded watermarks in the 2D-rendered images. Our method achieves state-of-the-art performance with faster training speed over the compared state-of-the-art methods.