 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect, Reject, Correct: Crossmodal Compensation of Corrupted Sensors
Dec 01, 2020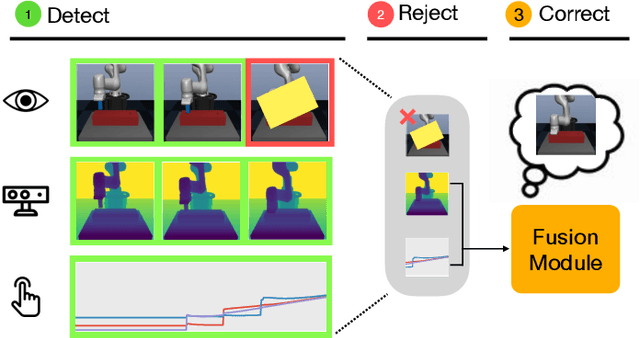
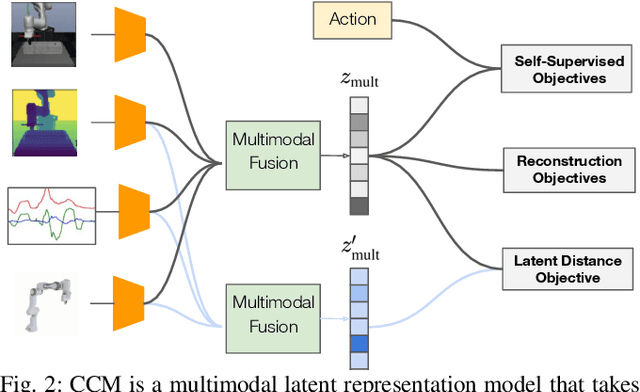
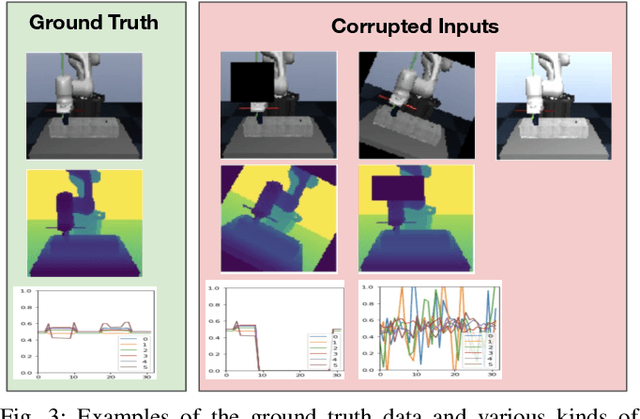
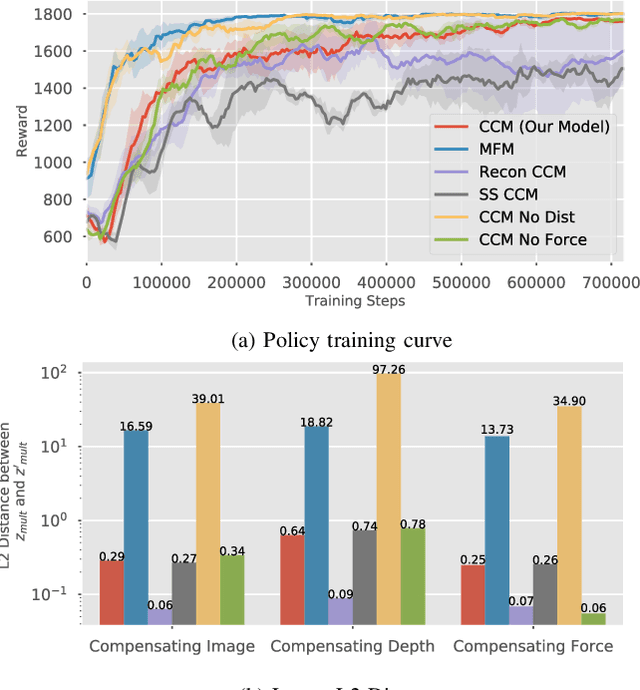
Using sensor data from multiple modalities presents an opportunity to encode redundant and complementary features that can be useful when one modality is corrupted or noisy. Humans do this everyday, relying on touch and proprioceptive feedback in visually-challenging environments. However, robots might not always know when their sensors are corrupted, as even broken sensors can return valid values. In this work, we introduce the Crossmodal Compensation Model (CCM), which can detect corrupted sensor modalities and compensate for them. CMM is a representation model learned with self-supervision that leverages unimodal reconstruction loss for corruption detection. CCM then discards the corrupted modality and compensates for it with information from the remaining sensors. We show that CCM learns rich state representations that can be used for contact-rich manipulation policies, even when input modalities are corrupted in ways not seen during training time.
Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks
Jul 28, 2019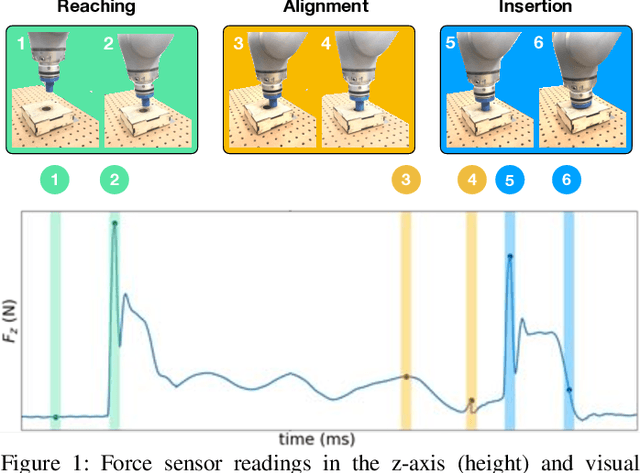
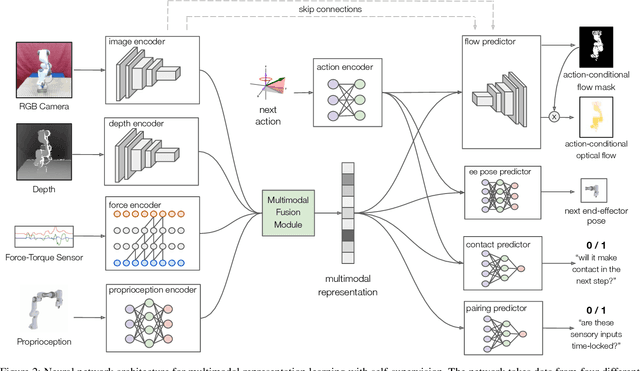
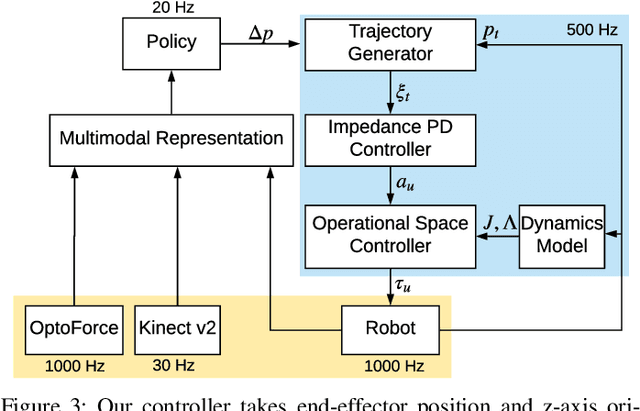
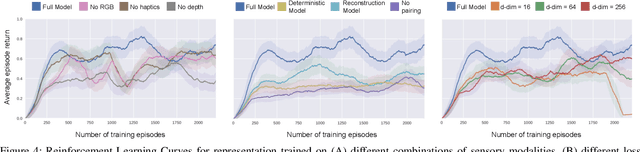
Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. It is non-trivial to manually design a robot controller that combines these modalities which have very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. In this work, we use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. Evaluating our method on a peg insertion task, we show that it generalizes over varying geometries, configurations, and clearances, while being robust to external perturbations. We also systematically study different self-supervised learning objectives and representation learning architectures. Results are presented in simulation and on a physical robot.
Predicting Economic Development using Geolocated Wikipedia Articles
May 11, 2019



Progress on the UN Sustainable Development Goals (SDGs) is hampered by a persistent lack of data regarding key social, environmental, and economic indicators, particularly in developing countries. For example, data on poverty --- the first of seventeen SDGs --- is both spatially sparse and infrequently collected in Sub-Saharan Africa due to the high cost of surveys. Here we propose a novel method for estimating socioeconomic indicators using open-source, geolocated textual information from Wikipedia articles. We demonstrate that modern NLP techniques can be used to predict community-level asset wealth and education outcomes using nearby geolocated Wikipedia articles. When paired with nightlights satellite imagery, our method outperforms all previously published benchmarks for this prediction task, indicating the potential of Wikipedia to inform both research in the social sciences and future policy decisions.
Privacy-Preserving Action Recognition for Smart Hospitals using Low-Resolution Depth Images
Nov 25, 2018


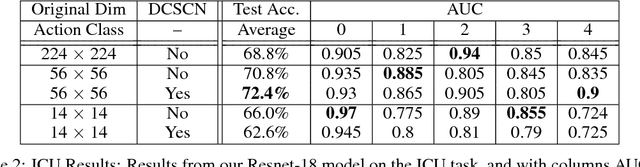
Computer-vision hospital systems can greatly assist healthcare workers and improve medical facility treatment, but often face patient resistance due to the perceived intrusiveness and violation of privacy associated with visual surveillance. We downsample video frames to extremely low resolutions to degrade private information from surveillance videos. We measure the amount of activity-recognition information retained in low resolution depth images, and also apply a privately-trained DCSCN super-resolution model to enhance the utility of our images. We implement our techniques with two actual healthcare-surveillance scenarios, hand-hygiene compliance and ICU activity-logging, and show that our privacy-preserving techniques preserve enough information for realistic healthcare tasks.