 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Dense Reward for Long-Horizon Robotic Tasks
Mar 31, 2026Existing robotic foundation policies are trained primarily via large-scale imitation learning. While such models demonstrate strong capabilities, they often struggle with long-horizon tasks due to distribution shift and error accumulation. While reinforcement learning (RL) can finetune these models, it cannot work well across diverse tasks without manual reward engineering. We propose VLLR, a dense reward framework combining (1) an extrinsic reward from Large Language Models (LLMs) and Vision-Language Models (VLMs) for task progress recognition, and (2) an intrinsic reward based on policy self-certainty. VLLR uses LLMs to decompose tasks into verifiable subtasks and then VLMs to estimate progress to initialize the value function for a brief warm-up phase, avoiding prohibitive inference cost during full training; and self-certainty provides per-step intrinsic guidance throughout PPO finetuning. Ablation studies reveal complementary benefits: VLM-based value initialization primarily improves task completion efficiency, while self-certainty primarily enhances success rates, particularly on out-of-distribution tasks. On the CHORES benchmark covering mobile manipulation and navigation, VLLR achieves up to 56% absolute success rate gains over the pretrained policy, up to 5% gains over state-of-the-art RL finetuning methods on in-distribution tasks, and up to $10\%$ gains on out-of-distribution tasks, all without manual reward engineering. Additional visualizations can be found in https://silongyong.github.io/vllr_project_page/
Efficient Conditional Pre-training for Transfer Learning
Dec 10, 2020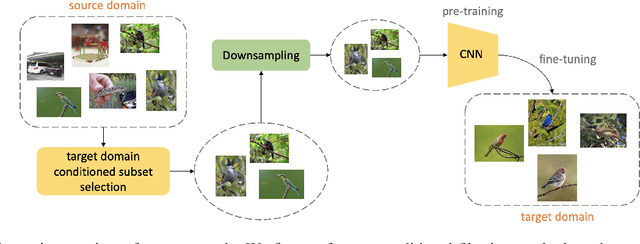
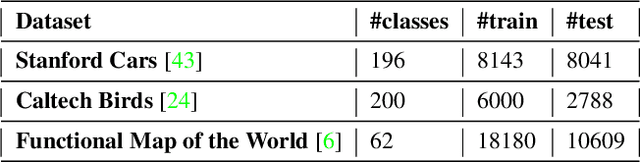
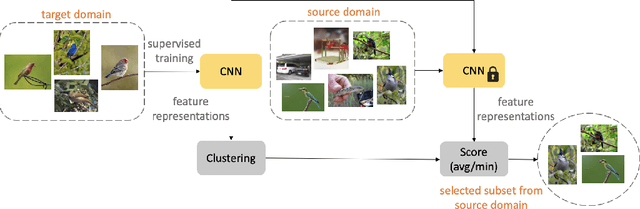
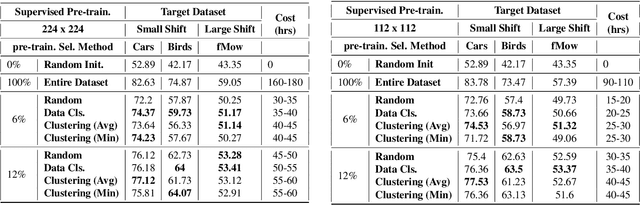
Almost all the state-of-the-art neural networks for computer vision tasks are trained by (1) Pre-training on a large scale dataset and (2) finetuning on the target dataset. This strategy helps reduce the dependency on the target dataset and improves convergence rate and generalization on the target task. Although pre-training on large scale datasets is very useful, its foremost disadvantage is high training cost. To address this, we propose efficient target dataset conditioned filtering methods to remove less relevant samples from the pre-training dataset. Unlike prior work, we focus on efficiency, adaptability, and flexibility in addition to performance. Additionally, we discover that lowering image resolutions in the pre-training step offers a great trade-off between cost and performance. We validate our techniques by pre-training on ImageNet in both the unsupervised and supervised settings and finetuning on a diverse collection of target datasets and tasks. Our proposed methods drastically reduce pre-training cost and provide strong performance boosts.
Predicting Economic Development using Geolocated Wikipedia Articles
May 11, 2019



Progress on the UN Sustainable Development Goals (SDGs) is hampered by a persistent lack of data regarding key social, environmental, and economic indicators, particularly in developing countries. For example, data on poverty --- the first of seventeen SDGs --- is both spatially sparse and infrequently collected in Sub-Saharan Africa due to the high cost of surveys. Here we propose a novel method for estimating socioeconomic indicators using open-source, geolocated textual information from Wikipedia articles. We demonstrate that modern NLP techniques can be used to predict community-level asset wealth and education outcomes using nearby geolocated Wikipedia articles. When paired with nightlights satellite imagery, our method outperforms all previously published benchmarks for this prediction task, indicating the potential of Wikipedia to inform both research in the social sciences and future policy decisions.
Learning to Interpret Satellite Images in Global Scale Using Wikipedia
May 11, 2019



Despite recent progress in computer vision, finegrained interpretation of satellite images remains challenging because of a lack of labeled training data. To overcome this limitation, we construct a novel dataset called WikiSatNet by pairing georeferenced Wikipedia articles with satellite imagery of their corresponding locations. We then propose two strategies to learn representations of satellite images by predicting properties of the corresponding articles from the images. Leveraging this new multi-modal dataset, we can drastically reduce the quantity of human-annotated labels and time required for downstream tasks. On the recently released fMoW dataset, our pre-training strategies can boost the performance of a model pre-trained on ImageNet by up to 4:5% in F1 score.
Learning to Interpret Satellite Images Using Wikipedia
Sep 19, 2018
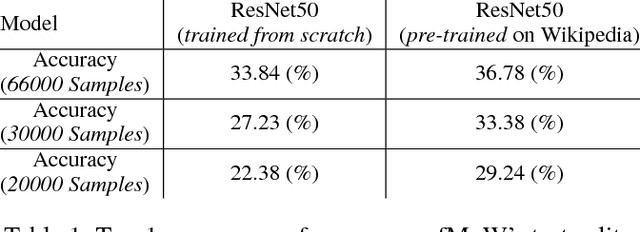

Despite recent progress in computer vision, fine-grained interpretation of satellite images remains challenging because of a lack of labeled training data. To overcome this limitation, we propose using Wikipedia as a previously untapped source of rich, georeferenced textual information with global coverage. We construct a novel large-scale, multi-modal dataset by pairing geo-referenced Wikipedia articles with satellite imagery of their corresponding locations. To prove the efficacy of this dataset, we focus on the African continent and train a deep network to classify images based on labels extracted from articles. We then fine-tune the model on a human annotated dataset and demonstrate that this weak form of supervision can drastically reduce the quantity of human annotated labels and time required for downstream tasks.