 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaboration with Cellular Networks for RFI Cancellation at Radio Telescope
Oct 31, 2022The growing need for electromagnetic spectrum to support the next generation (xG) communication networks increasingly generate unwanted radio frequency interference (RFI) in protected bands for radio astronomy. RFI is commonly mitigated at the Radio Telescope without any active collaboration with the interfering sources. In this work, we provide a method of signal characterization and its use in subsequent cancellation, that uses Eigenspaces derived from the telescope and the transmitter signals. This is different from conventional time-frequency domain analysis, which is limited to fixed characterizations (e.g., complex exponential in Fourier methods) that cannot adapt to the changing statistics (e.g., autocorrelation) of the RFI, typically observed in communication systems. We have presented effectiveness of this collaborative method using real-world astronomical signals and practical simulated LTE signals (downlink and uplink) as source of RFI along with propagation conditions based on preset benchmarks and standards. Through our analysis and simulation using these signals, we are able to remove 89.04% of the RFI from cellular networks, which reduces excision at the Telescope and capable of significantly improving throughput as corrupted time frequency bins data becomes usable.
IQ-Learn: Inverse soft-Q Learning for Imitation
Jun 23, 2021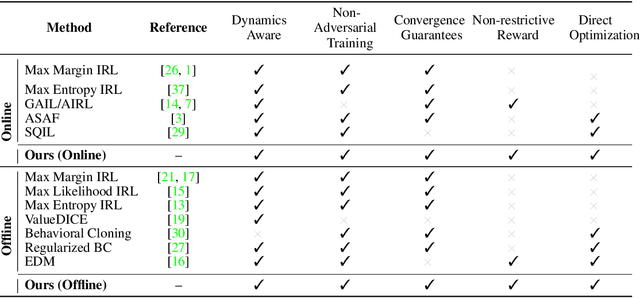



In many sequential decision-making problems (e.g., robotics control, game playing, sequential prediction), human or expert data is available containing useful information about the task. However, imitation learning (IL) from a small amount of expert data can be challenging in high-dimensional environments with complex dynamics. Behavioral cloning is a simple method that is widely used due to its simplicity of implementation and stable convergence but doesn't utilize any information involving the environment's dynamics. Many existing methods that exploit dynamics information are difficult to train in practice due to an adversarial optimization process over reward and policy approximators or biased, high variance gradient estimators. We introduce a method for dynamics-aware IL which avoids adversarial training by learning a single Q-function, implicitly representing both reward and policy. On standard benchmarks, the implicitly learned rewards show a high positive correlation with the ground-truth rewards, illustrating our method can also be used for inverse reinforcement learning (IRL). Our method, Inverse soft-Q learning (IQ-Learn) obtains state-of-the-art results in offline and online imitation learning settings, surpassing existing methods both in the number of required environment interactions and scalability in high-dimensional spaces.
Efficient Conditional Pre-training for Transfer Learning
Dec 10, 2020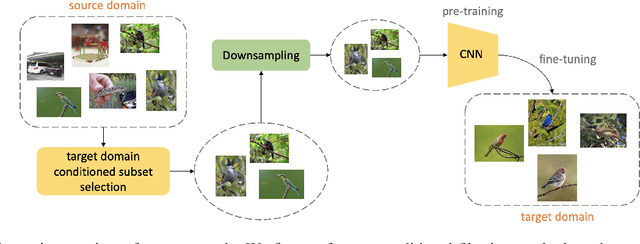
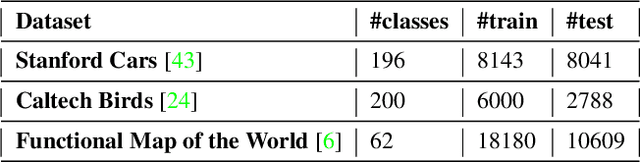
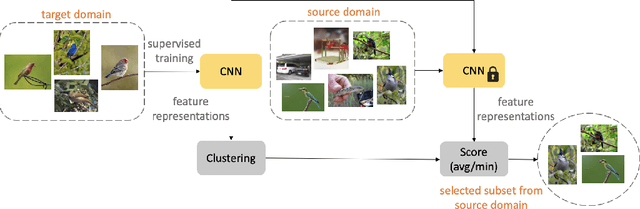
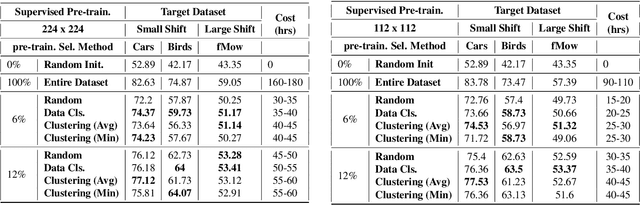
Almost all the state-of-the-art neural networks for computer vision tasks are trained by (1) Pre-training on a large scale dataset and (2) finetuning on the target dataset. This strategy helps reduce the dependency on the target dataset and improves convergence rate and generalization on the target task. Although pre-training on large scale datasets is very useful, its foremost disadvantage is high training cost. To address this, we propose efficient target dataset conditioned filtering methods to remove less relevant samples from the pre-training dataset. Unlike prior work, we focus on efficiency, adaptability, and flexibility in addition to performance. Additionally, we discover that lowering image resolutions in the pre-training step offers a great trade-off between cost and performance. We validate our techniques by pre-training on ImageNet in both the unsupervised and supervised settings and finetuning on a diverse collection of target datasets and tasks. Our proposed methods drastically reduce pre-training cost and provide strong performance boosts.
Belief Propagation Neural Networks
Jul 01, 2020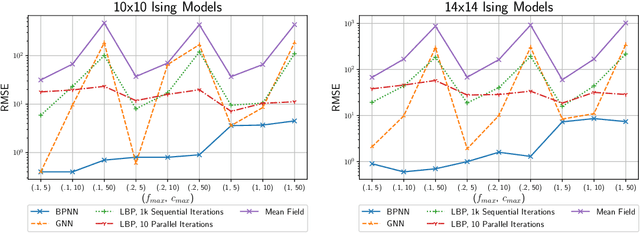

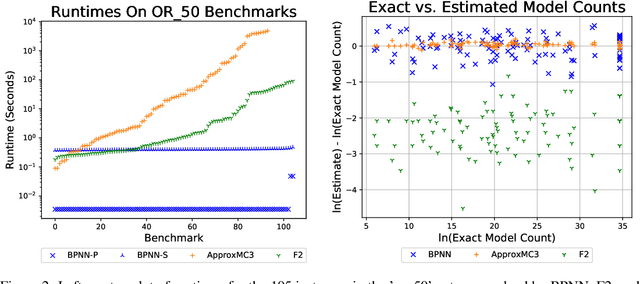
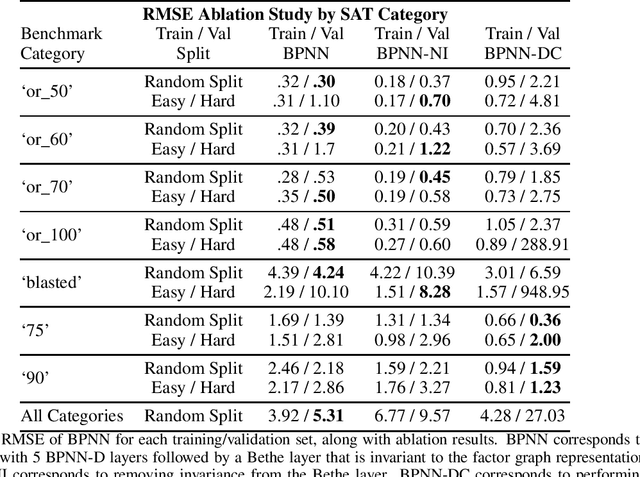
Learned neural solvers have successfully been used to solve combinatorial optimization and decision problems. More general counting variants of these problems, however, are still largely solved with hand-crafted solvers. To bridge this gap, we introduce belief propagation neural networks (BPNNs), a class of parameterized operators that operate on factor graphs and generalize Belief Propagation (BP). In its strictest form, a BPNN layer (BPNN-D) is a learned iterative operator that provably maintains many of the desirable properties of BP for any choice of the parameters. Empirically, we show that by training BPNN-D learns to perform the task better than the original BP: it converges 1.7x faster on Ising models while providing tighter bounds. On challenging model counting problems, BPNNs compute estimates 100's of times faster than state-of-the-art handcrafted methods, while returning an estimate of comparable quality.