 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Interpret Satellite Images Using Wikipedia
Paper and Code
Sep 19, 2018
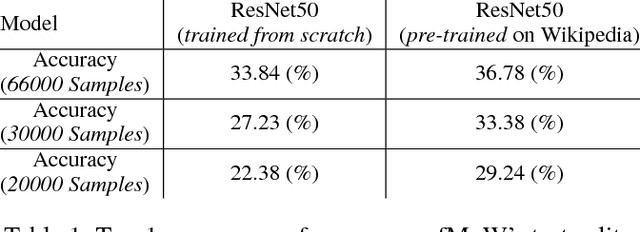

Despite recent progress in computer vision, fine-grained interpretation of satellite images remains challenging because of a lack of labeled training data. To overcome this limitation, we propose using Wikipedia as a previously untapped source of rich, georeferenced textual information with global coverage. We construct a novel large-scale, multi-modal dataset by pairing geo-referenced Wikipedia articles with satellite imagery of their corresponding locations. To prove the efficacy of this dataset, we focus on the African continent and train a deep network to classify images based on labels extracted from articles. We then fine-tune the model on a human annotated dataset and demonstrate that this weak form of supervision can drastically reduce the quantity of human annotated labels and time required for downstream tasks.