 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Interpret Satellite Images in Global Scale Using Wikipedia
May 11, 2019



Despite recent progress in computer vision, finegrained interpretation of satellite images remains challenging because of a lack of labeled training data. To overcome this limitation, we construct a novel dataset called WikiSatNet by pairing georeferenced Wikipedia articles with satellite imagery of their corresponding locations. We then propose two strategies to learn representations of satellite images by predicting properties of the corresponding articles from the images. Leveraging this new multi-modal dataset, we can drastically reduce the quantity of human-annotated labels and time required for downstream tasks. On the recently released fMoW dataset, our pre-training strategies can boost the performance of a model pre-trained on ImageNet by up to 4:5% in F1 score.
Mapping Missing Population in Rural India: A Deep Learning Approach with Satellite Imagery
May 04, 2019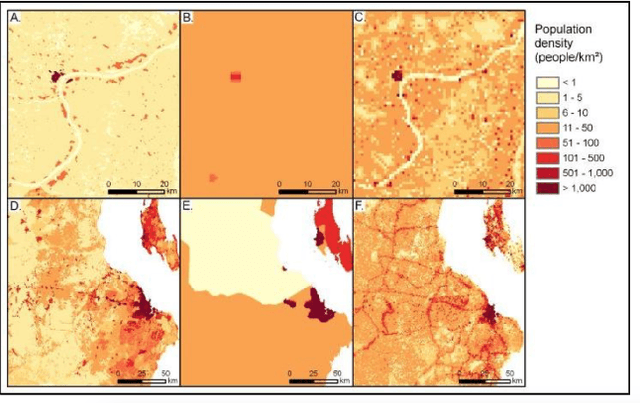
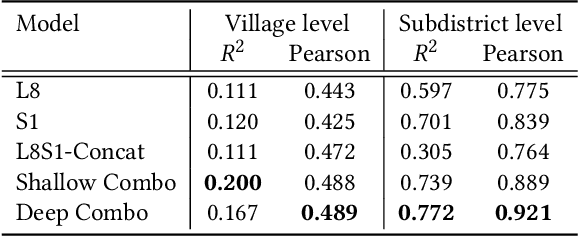
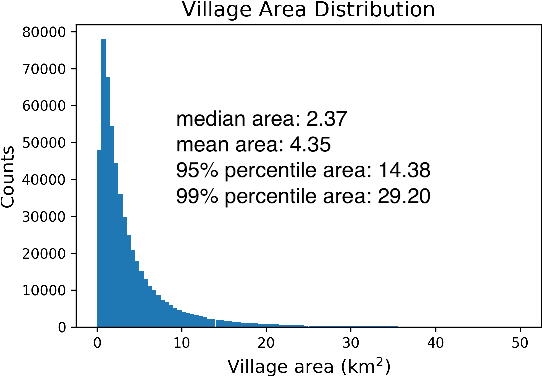
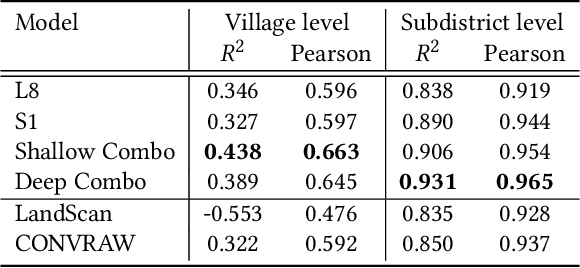
Millions of people worldwide are absent from their country's census. Accurate, current, and granular population metrics are critical to improving government allocation of resources, to measuring disease control, to responding to natural disasters, and to studying any aspect of human life in these communities. Satellite imagery can provide sufficient information to build a population map without the cost and time of a government census. We present two Convolutional Neural Network (CNN) architectures which efficiently and effectively combine satellite imagery inputs from multiple sources to accurately predict the population density of a region. In this paper, we use satellite imagery from rural villages in India and population labels from the 2011 SECC census. Our best model achieves better performance than previous papers as well as LandScan, a community standard for global population distribution.
* 7 pages
Learning to Interpret Satellite Images Using Wikipedia
Sep 19, 2018
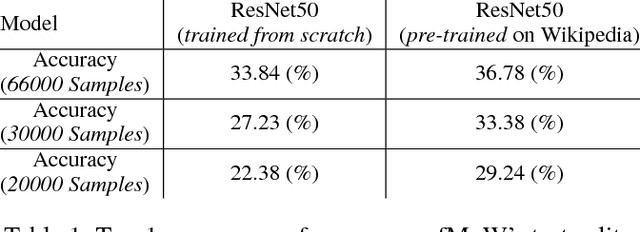

Despite recent progress in computer vision, fine-grained interpretation of satellite images remains challenging because of a lack of labeled training data. To overcome this limitation, we propose using Wikipedia as a previously untapped source of rich, georeferenced textual information with global coverage. We construct a novel large-scale, multi-modal dataset by pairing geo-referenced Wikipedia articles with satellite imagery of their corresponding locations. To prove the efficacy of this dataset, we focus on the African continent and train a deep network to classify images based on labels extracted from articles. We then fine-tune the model on a human annotated dataset and demonstrate that this weak form of supervision can drastically reduce the quantity of human annotated labels and time required for downstream tasks.