 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Pseudo-Label Optimism for the Bank Loan Problem
Dec 03, 2021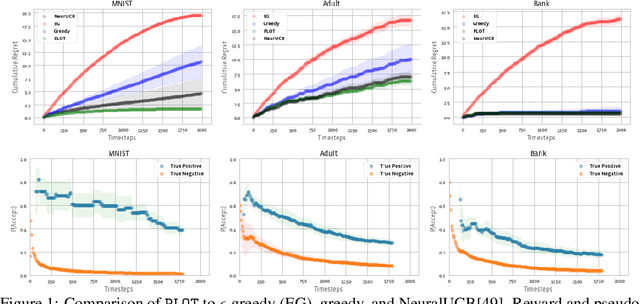
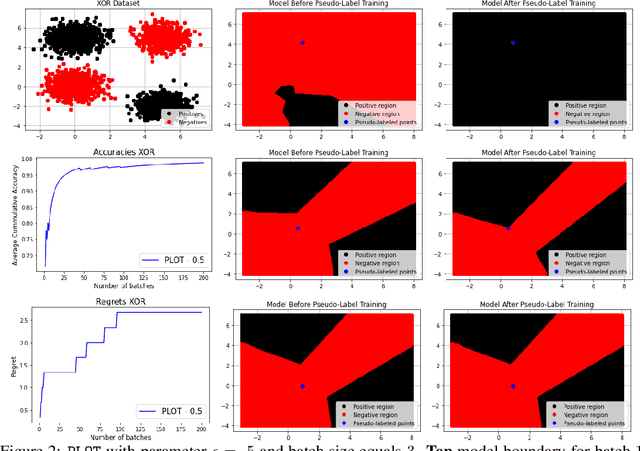
We study a class of classification problems best exemplified by the \emph{bank loan} problem, where a lender decides whether or not to issue a loan. The lender only observes whether a customer will repay a loan if the loan is issued to begin with, and thus modeled decisions affect what data is available to the lender for future decisions. As a result, it is possible for the lender's algorithm to ``get stuck'' with a self-fulfilling model. This model never corrects its false negatives, since it never sees the true label for rejected data, thus accumulating infinite regret. In the case of linear models, this issue can be addressed by adding optimism directly into the model predictions. However, there are few methods that extend to the function approximation case using Deep Neural Networks. We present Pseudo-Label Optimism (PLOT), a conceptually and computationally simple method for this setting applicable to DNNs. \PLOT{} adds an optimistic label to the subset of decision points the current model is deciding on, trains the model on all data so far (including these points along with their optimistic labels), and finally uses the resulting \emph{optimistic} model for decision making. \PLOT{} achieves competitive performance on a set of three challenging benchmark problems, requiring minimal hyperparameter tuning. We also show that \PLOT{} satisfies a logarithmic regret guarantee, under a Lipschitz and logistic mean label model, and under a separability condition on the data.
Similarity Search for Efficient Active Learning and Search of Rare Concepts
Jun 30, 2020
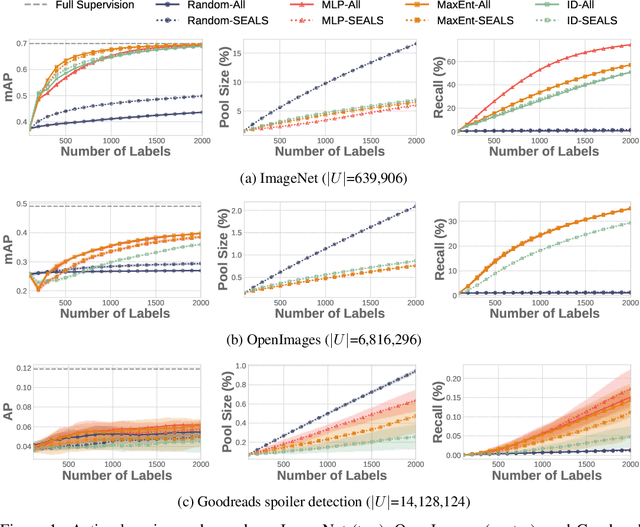

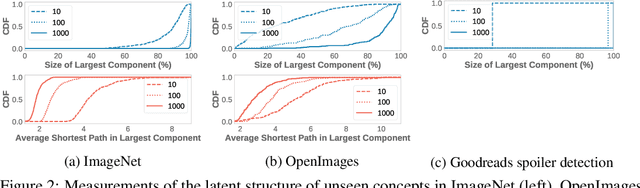
Many active learning and search approaches are intractable for industrial settings with billions of unlabeled examples. Existing approaches, such as uncertainty sampling or information density, search globally for the optimal examples to label, scaling linearly or even quadratically with the unlabeled data. However, in practice, data is often heavily skewed; only a small fraction of collected data will be relevant for a given learning task. For example, when identifying rare classes, detecting malicious content, or debugging model performance, the ratio of positive to negative examples can be 1 to 1,000 or more. In this work, we exploit this skew in large training datasets to reduce the number of unlabeled examples considered in each selection round by only looking at the nearest neighbors to the labeled examples. Empirically, we observe that learned representations effectively cluster unseen concepts, making active learning very effective and substantially reducing the number of viable unlabeled examples. We evaluate several active learning and search techniques in this setting on three large-scale datasets: ImageNet, Goodreads spoiler detection, and OpenImages. For rare classes, active learning methods need as little as 0.31% of the labeled data to match the average precision of full supervision. By limiting active learning methods to only consider the immediate neighbors of the labeled data as candidates for labeling, we need only process as little as 1% of the unlabeled data while achieving similar reductions in labeling costs as the traditional global approach. This process of expanding the candidate pool with the nearest neighbors of the labeled set can be done efficiently and reduces the computational complexity of selection by orders of magnitude.
Privacy-Preserving Action Recognition for Smart Hospitals using Low-Resolution Depth Images
Nov 25, 2018


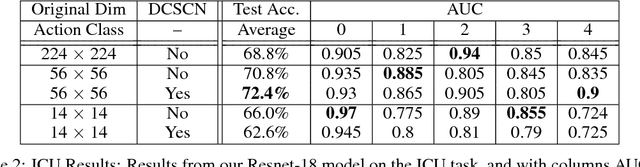
Computer-vision hospital systems can greatly assist healthcare workers and improve medical facility treatment, but often face patient resistance due to the perceived intrusiveness and violation of privacy associated with visual surveillance. We downsample video frames to extremely low resolutions to degrade private information from surveillance videos. We measure the amount of activity-recognition information retained in low resolution depth images, and also apply a privately-trained DCSCN super-resolution model to enhance the utility of our images. We implement our techniques with two actual healthcare-surveillance scenarios, hand-hygiene compliance and ICU activity-logging, and show that our privacy-preserving techniques preserve enough information for realistic healthcare tasks.
AI Blue Book: Vehicle Price Prediction using Visual Features
Oct 18, 2018

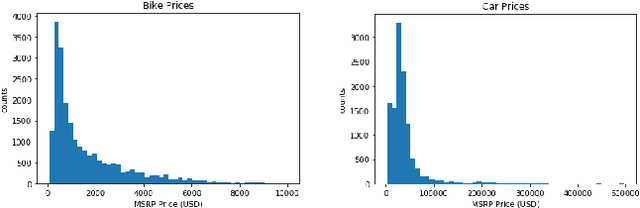

In this work, we build a series of machine learning models to predict the price of a product given its image, and visualize the features that result in higher or lower price predictions. We collect two novel datasets of product images and their MSRP prices for this purpose: a bicycle dataset and a car dataset. We set baselines for price regression using linear regression on histogram of oriented gradients (HOG) and convolutional neural network (CNN) features, and a baseline for price segment classification using a multiclass SVM. For our main models, we train several deep CNNs using both transfer learning and our own architectures, for both regression and classification. We achieve strong results on both datasets, with deep CNNs significantly outperforming other models in a variety of metrics. Finally, we use several recently-developed methods to visualize the image features that result in higher or lower prices.