 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Decisions Reduce Regret: Adversarial Domain Adaptation for the Bank Loan Problem
Aug 15, 2023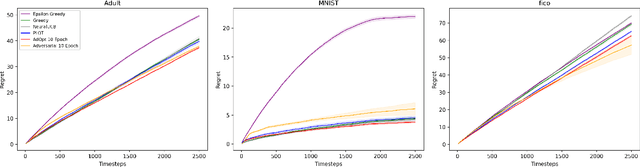

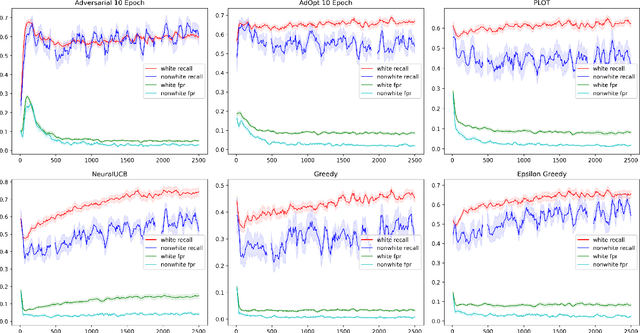

In many real world settings binary classification decisions are made based on limited data in near real-time, e.g. when assessing a loan application. We focus on a class of these problems that share a common feature: the true label is only observed when a data point is assigned a positive label by the principal, e.g. we only find out whether an applicant defaults if we accepted their loan application. As a consequence, the false rejections become self-reinforcing and cause the labelled training set, that is being continuously updated by the model decisions, to accumulate bias. Prior work mitigates this effect by injecting optimism into the model, however this comes at the cost of increased false acceptance rate. We introduce adversarial optimism (AdOpt) to directly address bias in the training set using adversarial domain adaptation. The goal of AdOpt is to learn an unbiased but informative representation of past data, by reducing the distributional shift between the set of accepted data points and all data points seen thus far. AdOpt significantly exceeds state-of-the-art performance on a set of challenging benchmark problems. Our experiments also provide initial evidence that the introduction of adversarial domain adaptation improves fairness in this setting.
Practical Policy Optimization with Personalized Experimentation
Mar 30, 2023

Many organizations measure treatment effects via an experimentation platform to evaluate the casual effect of product variations prior to full-scale deployment. However, standard experimentation platforms do not perform optimally for end user populations that exhibit heterogeneous treatment effects (HTEs). Here we present a personalized experimentation framework, Personalized Experiments (PEX), which optimizes treatment group assignment at the user level via HTE modeling and sequential decision policy optimization to optimize multiple short-term and long-term outcomes simultaneously. We describe an end-to-end workflow that has proven to be successful in practice and can be readily implemented using open-source software.
Neural Pseudo-Label Optimism for the Bank Loan Problem
Dec 03, 2021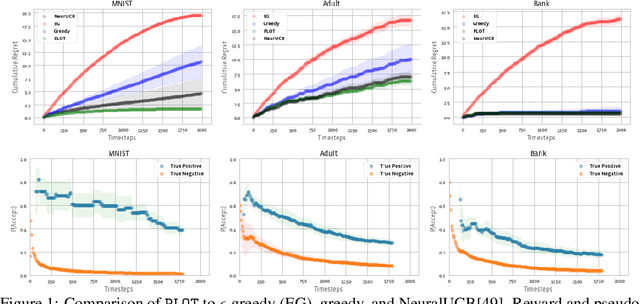
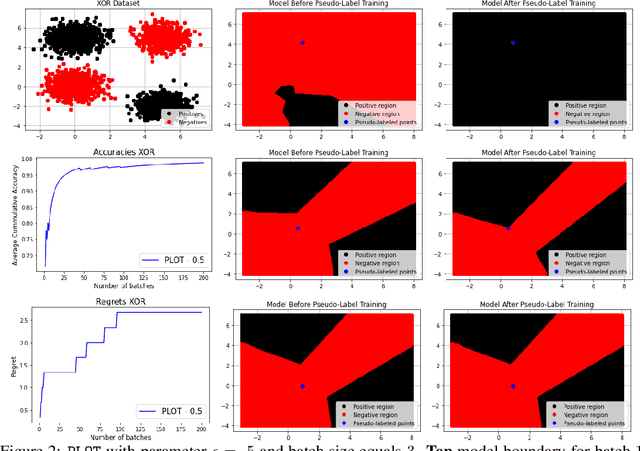
We study a class of classification problems best exemplified by the \emph{bank loan} problem, where a lender decides whether or not to issue a loan. The lender only observes whether a customer will repay a loan if the loan is issued to begin with, and thus modeled decisions affect what data is available to the lender for future decisions. As a result, it is possible for the lender's algorithm to ``get stuck'' with a self-fulfilling model. This model never corrects its false negatives, since it never sees the true label for rejected data, thus accumulating infinite regret. In the case of linear models, this issue can be addressed by adding optimism directly into the model predictions. However, there are few methods that extend to the function approximation case using Deep Neural Networks. We present Pseudo-Label Optimism (PLOT), a conceptually and computationally simple method for this setting applicable to DNNs. \PLOT{} adds an optimistic label to the subset of decision points the current model is deciding on, trains the model on all data so far (including these points along with their optimistic labels), and finally uses the resulting \emph{optimistic} model for decision making. \PLOT{} achieves competitive performance on a set of three challenging benchmark problems, requiring minimal hyperparameter tuning. We also show that \PLOT{} satisfies a logarithmic regret guarantee, under a Lipschitz and logistic mean label model, and under a separability condition on the data.
Looper: An end-to-end ML platform for product decisions
Nov 10, 2021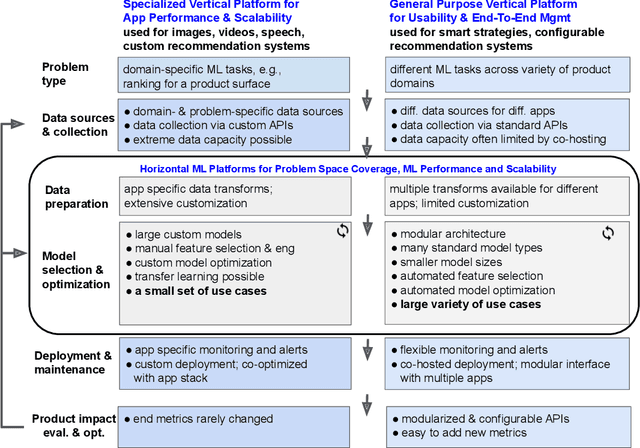
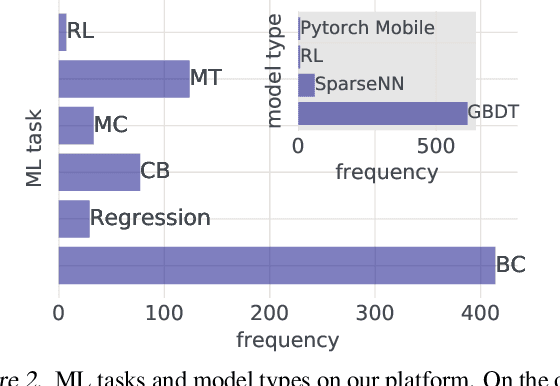
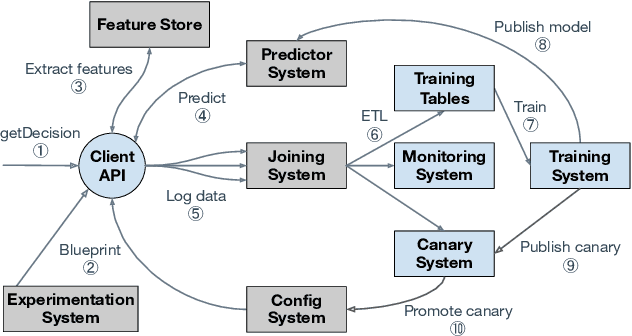
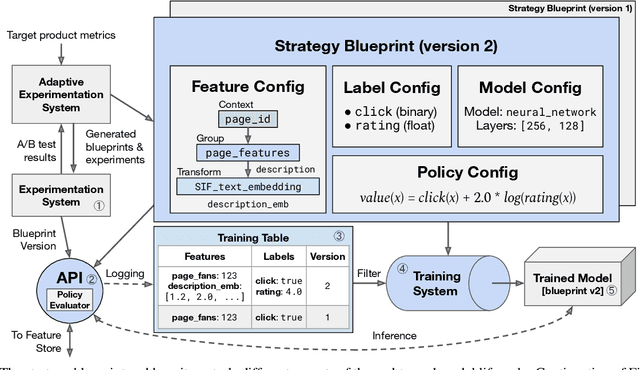
Modern software systems and products increasingly rely on machine learning models to make data-driven decisions based on interactions with users and systems, e.g., compute infrastructure. For broader adoption, this practice must (i) accommodate software engineers without ML backgrounds, and (ii) provide mechanisms to optimize for product goals. In this work, we describe general principles and a specific end-to-end ML platform, Looper, which offers easy-to-use APIs for decision-making and feedback collection. Looper supports the full end-to-end ML lifecycle from online data collection to model training, deployment, inference, and extends support to evaluation and tuning against product goals. We outline the platform architecture and overall impact of production deployment -- Looper currently hosts 700 ML models and makes 6 million decisions per second. We also describe the learning curve and summarize experiences of platform adopters.
Distilling Heterogeneity: From Explanations of Heterogeneous Treatment Effect Models to Interpretable Policies
Nov 05, 2021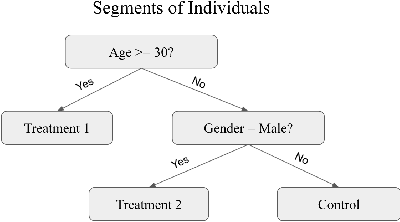
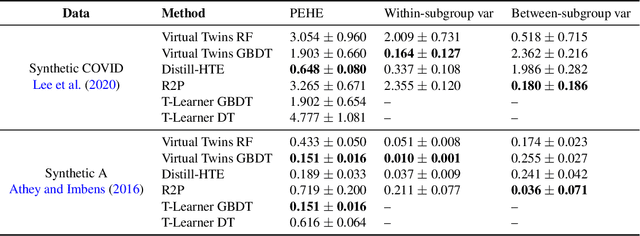
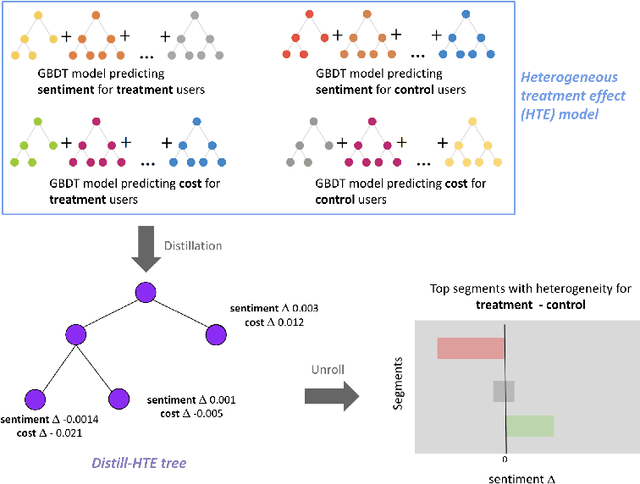
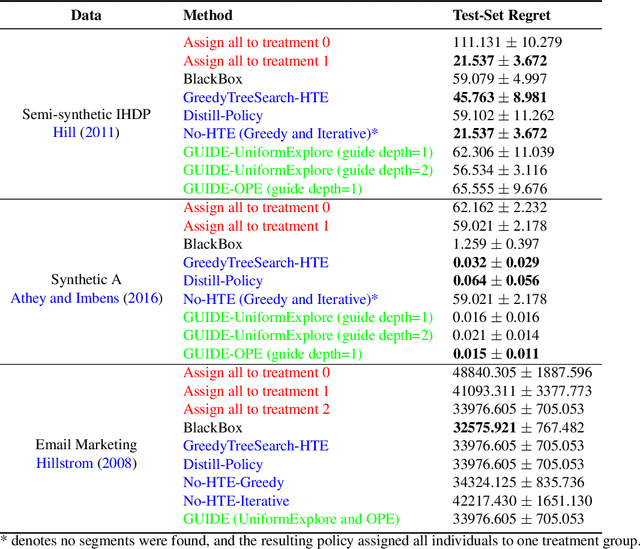
Internet companies are increasingly using machine learning models to create personalized policies which assign, for each individual, the best predicted treatment for that individual. They are frequently derived from black-box heterogeneous treatment effect (HTE) models that predict individual-level treatment effects. In this paper, we focus on (1) learning explanations for HTE models; (2) learning interpretable policies that prescribe treatment assignments. We also propose guidance trees, an approach to ensemble multiple interpretable policies without the loss of interpretability. These rule-based interpretable policies are easy to deploy and avoid the need to maintain a HTE model in a production environment.
Real-world Video Adaptation with Reinforcement Learning
Aug 28, 2020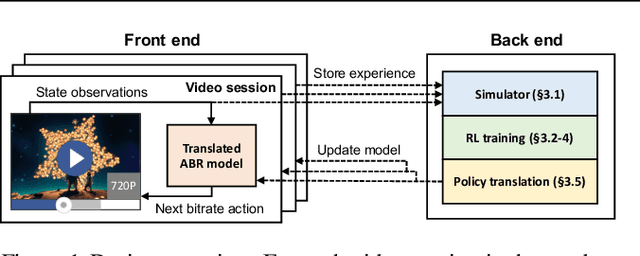
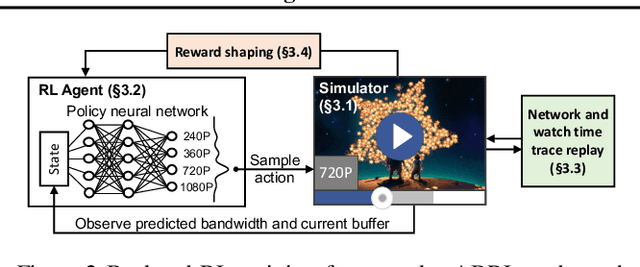
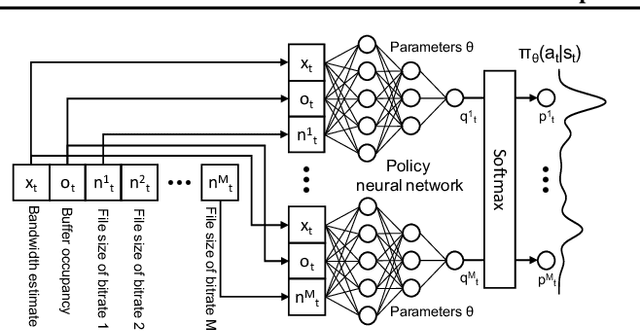
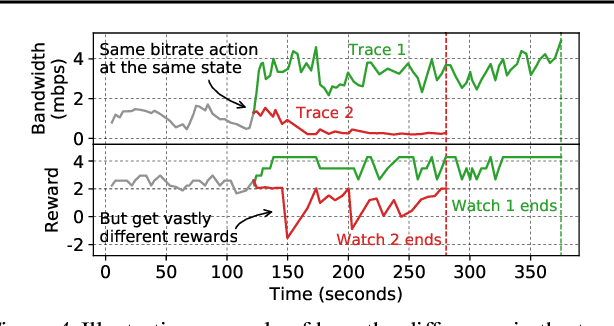
Client-side video players employ adaptive bitrate (ABR) algorithms to optimize user quality of experience (QoE). We evaluate recently proposed RL-based ABR methods in Facebook's web-based video streaming platform. Real-world ABR contains several challenges that requires customized designs beyond off-the-shelf RL algorithms -- we implement a scalable neural network architecture that supports videos with arbitrary bitrate encodings; we design a training method to cope with the variance resulting from the stochasticity in network conditions; and we leverage constrained Bayesian optimization for reward shaping in order to optimize the conflicting QoE objectives. In a week-long worldwide deployment with more than 30 million video streaming sessions, our RL approach outperforms the existing human-engineered ABR algorithms.
Thompson Sampling for Contextual Bandit Problems with Auxiliary Safety Constraints
Nov 02, 2019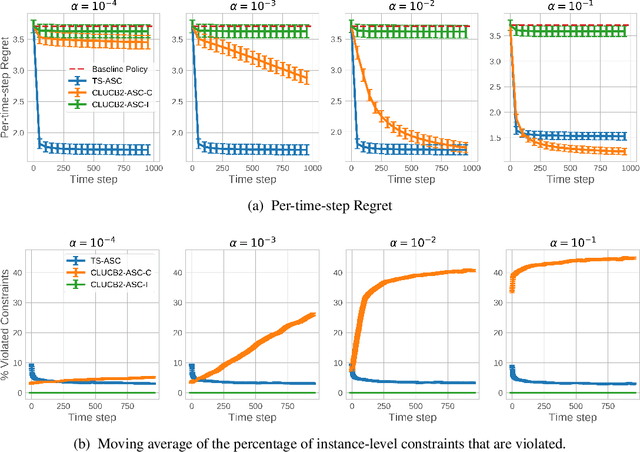
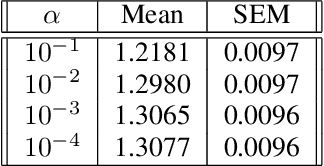
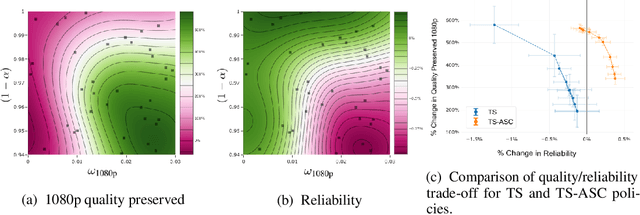
Recent advances in contextual bandit optimization and reinforcement learning have garnered interest in applying these methods to real-world sequential decision making problems. Real-world applications frequently have constraints with respect to a currently deployed policy. Many of the existing constraint-aware algorithms consider problems with a single objective (the reward) and a constraint on the reward with respect to a baseline policy. However, many important applications involve multiple competing objectives and auxiliary constraints. In this paper, we propose a novel Thompson sampling algorithm for multi-outcome contextual bandit problems with auxiliary constraints. We empirically evaluate our algorithm on a synthetic problem. Lastly, we apply our method to a real world video transcoding problem and provide a practical way for navigating the trade-off between safety and performance using Bayesian optimization.