 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Practical Policy Optimization with Personalized Experimentation
Mar 30, 2023

Many organizations measure treatment effects via an experimentation platform to evaluate the casual effect of product variations prior to full-scale deployment. However, standard experimentation platforms do not perform optimally for end user populations that exhibit heterogeneous treatment effects (HTEs). Here we present a personalized experimentation framework, Personalized Experiments (PEX), which optimizes treatment group assignment at the user level via HTE modeling and sequential decision policy optimization to optimize multiple short-term and long-term outcomes simultaneously. We describe an end-to-end workflow that has proven to be successful in practice and can be readily implemented using open-source software.
Looper: An end-to-end ML platform for product decisions
Nov 10, 2021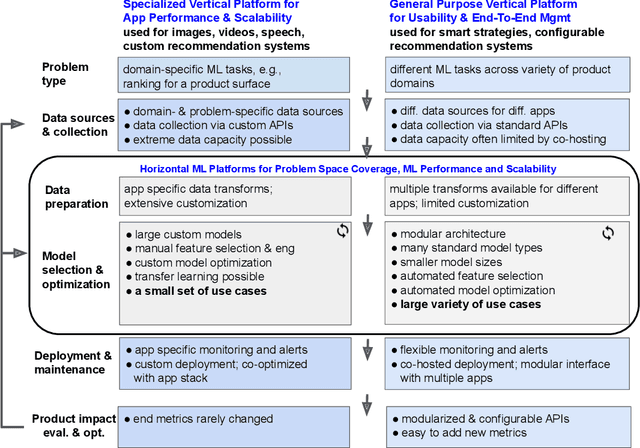
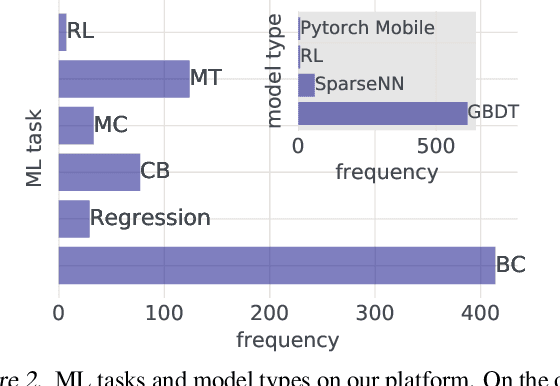
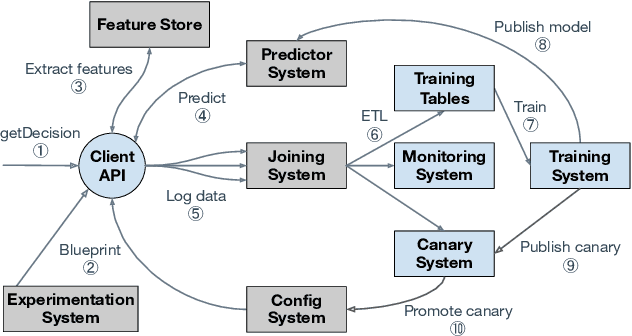
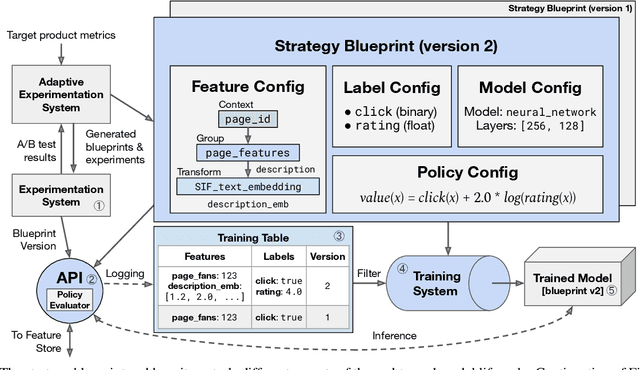
Modern software systems and products increasingly rely on machine learning models to make data-driven decisions based on interactions with users and systems, e.g., compute infrastructure. For broader adoption, this practice must (i) accommodate software engineers without ML backgrounds, and (ii) provide mechanisms to optimize for product goals. In this work, we describe general principles and a specific end-to-end ML platform, Looper, which offers easy-to-use APIs for decision-making and feedback collection. Looper supports the full end-to-end ML lifecycle from online data collection to model training, deployment, inference, and extends support to evaluation and tuning against product goals. We outline the platform architecture and overall impact of production deployment -- Looper currently hosts 700 ML models and makes 6 million decisions per second. We also describe the learning curve and summarize experiences of platform adopters.
Distilling Heterogeneity: From Explanations of Heterogeneous Treatment Effect Models to Interpretable Policies
Nov 05, 2021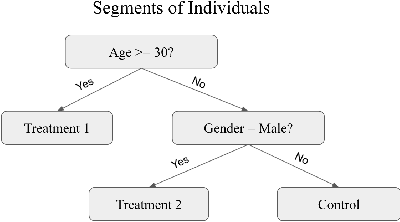
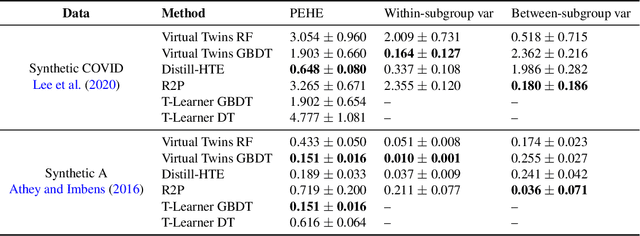
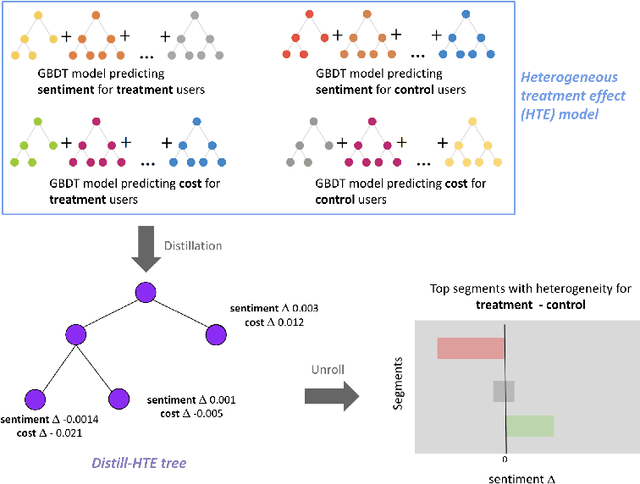
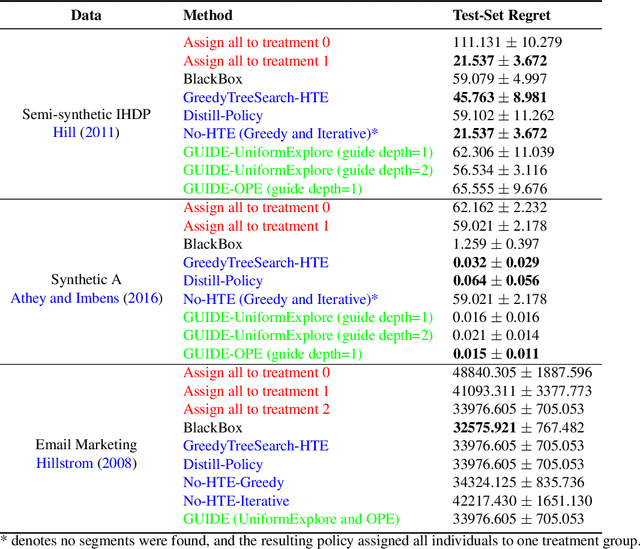
Internet companies are increasingly using machine learning models to create personalized policies which assign, for each individual, the best predicted treatment for that individual. They are frequently derived from black-box heterogeneous treatment effect (HTE) models that predict individual-level treatment effects. In this paper, we focus on (1) learning explanations for HTE models; (2) learning interpretable policies that prescribe treatment assignments. We also propose guidance trees, an approach to ensemble multiple interpretable policies without the loss of interpretability. These rule-based interpretable policies are easy to deploy and avoid the need to maintain a HTE model in a production environment.
Personalization for Web-based Services using Offline Reinforcement Learning
Feb 10, 2021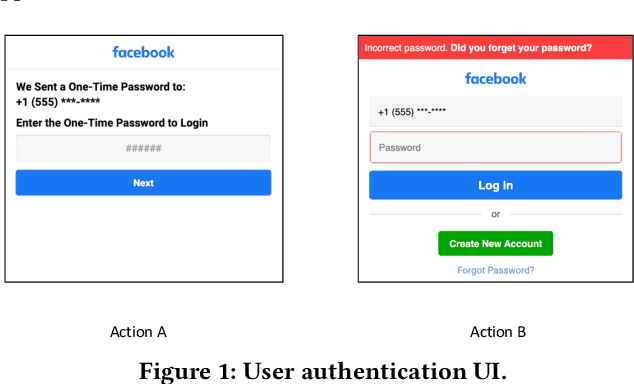

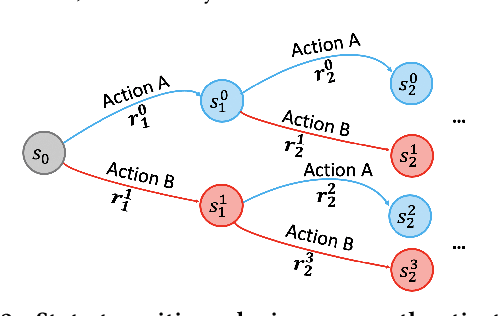
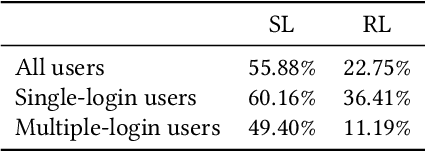
Large-scale Web-based services present opportunities for improving UI policies based on observed user interactions. We address challenges of learning such policies through model-free offline Reinforcement Learning (RL) with off-policy training. Deployed in a production system for user authentication in a major social network, it significantly improves long-term objectives. We articulate practical challenges, compare several ML techniques, provide insights on training and evaluation of RL models, and discuss generalizations.
Predictive Precompute with Recurrent Neural Networks
Dec 14, 2019
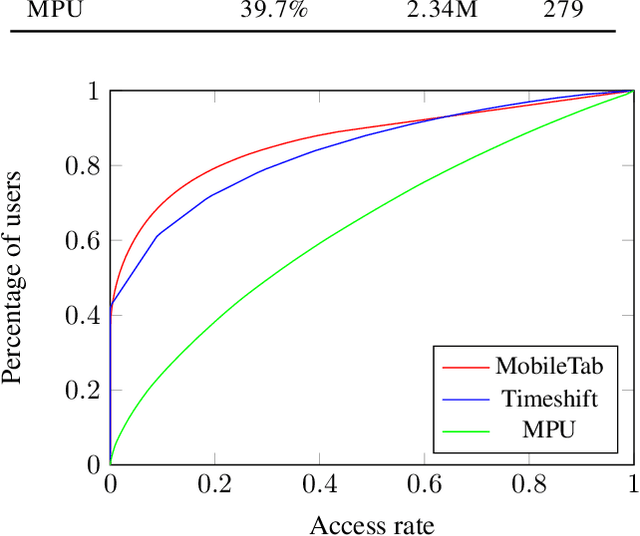
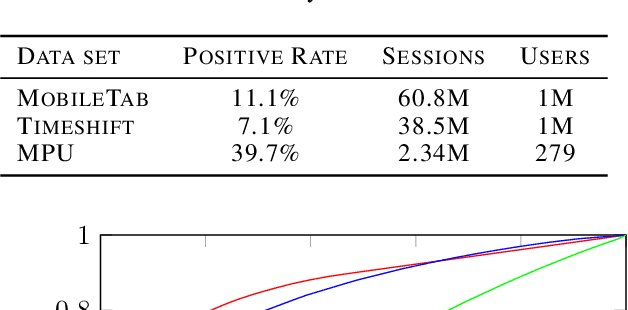
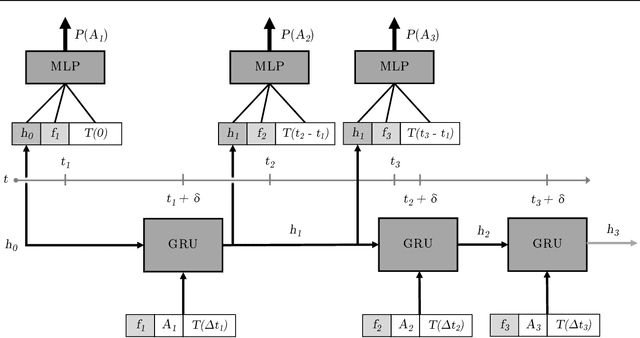
In both mobile and web applications, speeding up user interface response times can often lead to significant improvements in user engagement. A common technique to improve responsiveness is to precompute data ahead of time for specific features. However, simply precomputing data for all user and feature combinations is prohibitive at scale due to both network constraints and server-side computational costs. It is therefore important to accurately predict per-user feature usage in order to minimize wasted precomputation ("predictive precompute''). In this paper, we describe the novel application of recurrent neural networks (RNNs) for predictive precompute. We compare their performance with traditional machine learning models, and share findings from their use in a billion-user scale production environment at Facebook. We demonstrate that RNN models improve prediction accuracy, eliminate most feature engineering steps, and reduce the computational cost of serving predictions by an order of magnitude.