 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Heterogeneity: From Explanations of Heterogeneous Treatment Effect Models to Interpretable Policies
Nov 05, 2021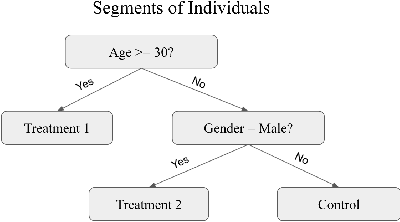
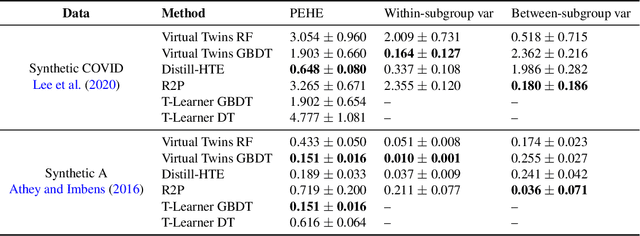
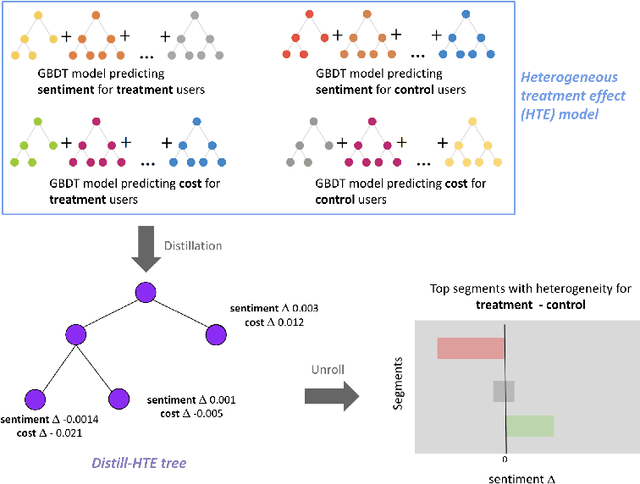
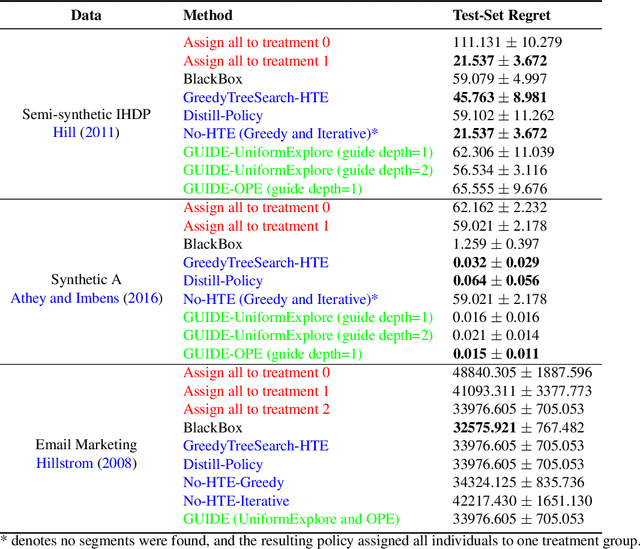
Internet companies are increasingly using machine learning models to create personalized policies which assign, for each individual, the best predicted treatment for that individual. They are frequently derived from black-box heterogeneous treatment effect (HTE) models that predict individual-level treatment effects. In this paper, we focus on (1) learning explanations for HTE models; (2) learning interpretable policies that prescribe treatment assignments. We also propose guidance trees, an approach to ensemble multiple interpretable policies without the loss of interpretability. These rule-based interpretable policies are easy to deploy and avoid the need to maintain a HTE model in a production environment.
Efficient Balanced Treatment Assignments for Experimentation
Oct 21, 2020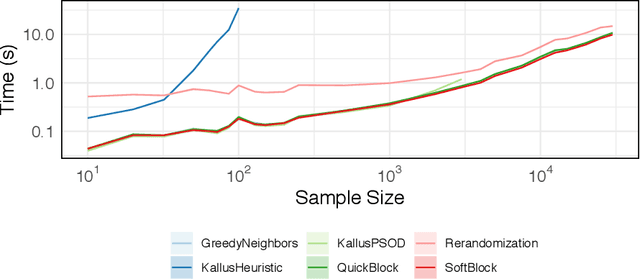
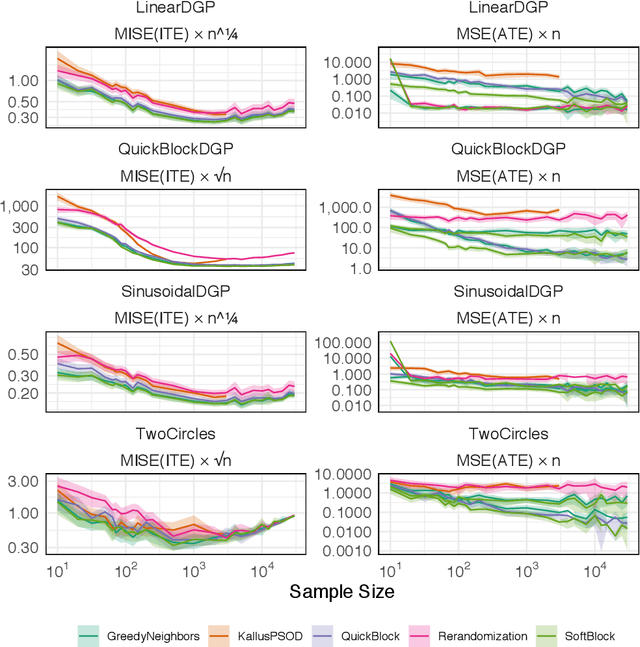

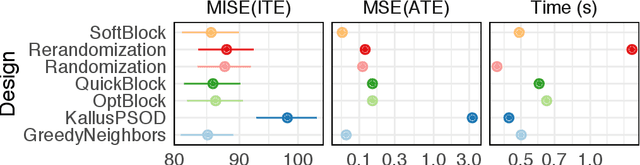
In this work, we reframe the problem of balanced treatment assignment as optimization of a two-sample test between test and control units. Using this lens we provide an assignment algorithm that is optimal with respect to the minimum spanning tree test of Friedman and Rafsky (1979). This assignment to treatment groups may be performed exactly in polynomial time. We provide a probabilistic interpretation of this process in terms of the most probable element of designs drawn from a determinantal point process which admits a probabilistic interpretation of the design. We provide a novel formulation of estimation as transductive inference and show how the tree structures used in design can also be used in an adjustment estimator. We conclude with a simulation study demonstrating the improved efficacy of our method.
Real-world Video Adaptation with Reinforcement Learning
Aug 28, 2020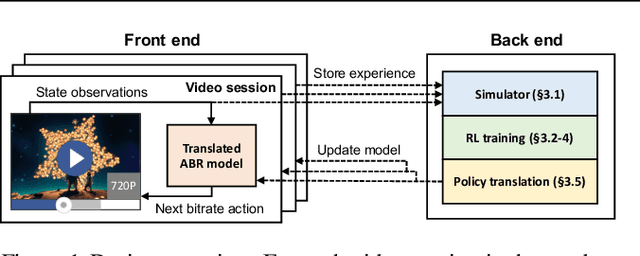
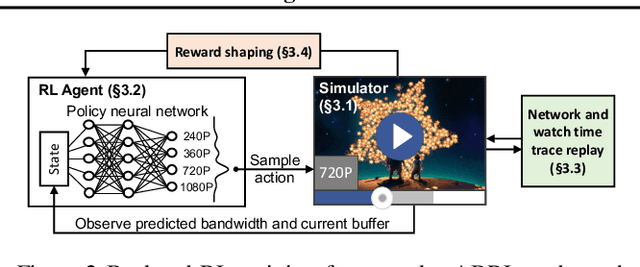
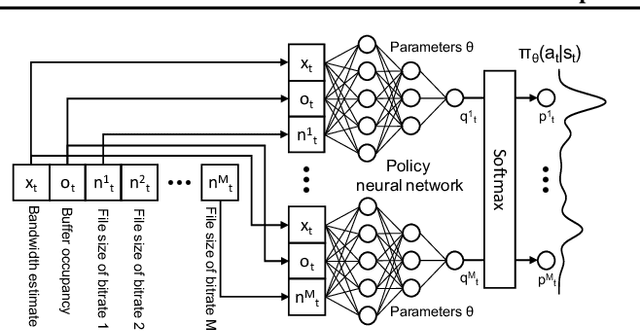
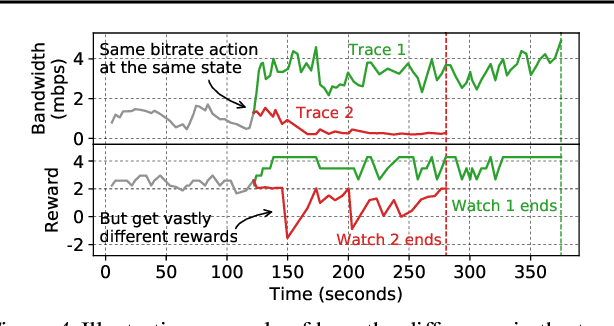
Client-side video players employ adaptive bitrate (ABR) algorithms to optimize user quality of experience (QoE). We evaluate recently proposed RL-based ABR methods in Facebook's web-based video streaming platform. Real-world ABR contains several challenges that requires customized designs beyond off-the-shelf RL algorithms -- we implement a scalable neural network architecture that supports videos with arbitrary bitrate encodings; we design a training method to cope with the variance resulting from the stochasticity in network conditions; and we leverage constrained Bayesian optimization for reward shaping in order to optimize the conflicting QoE objectives. In a week-long worldwide deployment with more than 30 million video streaming sessions, our RL approach outperforms the existing human-engineered ABR algorithms.
Thompson Sampling for Contextual Bandit Problems with Auxiliary Safety Constraints
Nov 02, 2019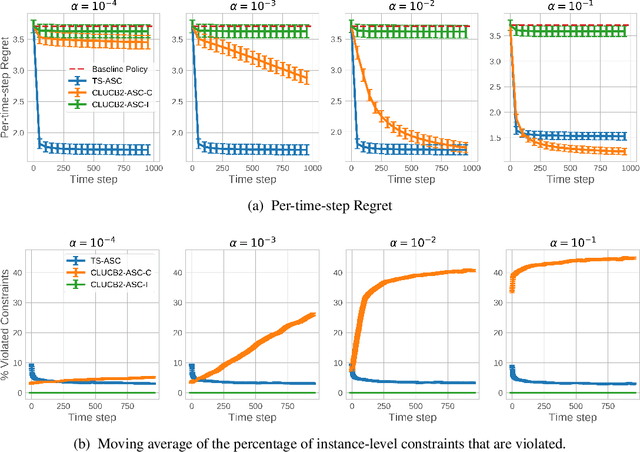
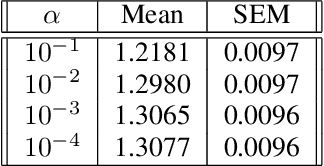
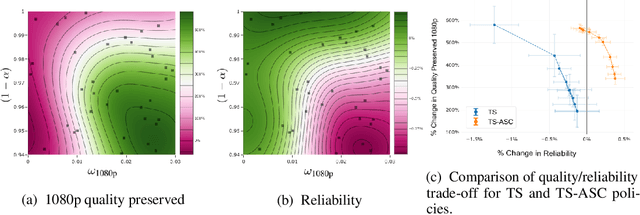
Recent advances in contextual bandit optimization and reinforcement learning have garnered interest in applying these methods to real-world sequential decision making problems. Real-world applications frequently have constraints with respect to a currently deployed policy. Many of the existing constraint-aware algorithms consider problems with a single objective (the reward) and a constraint on the reward with respect to a baseline policy. However, many important applications involve multiple competing objectives and auxiliary constraints. In this paper, we propose a novel Thompson sampling algorithm for multi-outcome contextual bandit problems with auxiliary constraints. We empirically evaluate our algorithm on a synthetic problem. Lastly, we apply our method to a real world video transcoding problem and provide a practical way for navigating the trade-off between safety and performance using Bayesian optimization.
Balanced Off-Policy Evaluation in General Action Spaces
Jun 13, 2019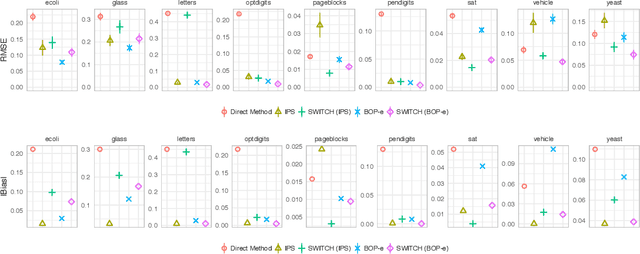

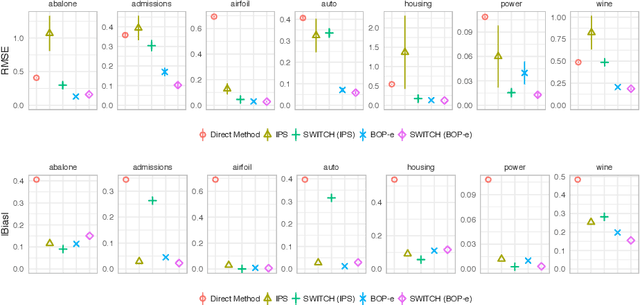
In many practical applications of contextual bandits, online learning is infeasible and practitioners must rely on off-policy evaluation (OPE) of logged data collected from prior policies. OPE generally consists of a combination of two components: (i) directly estimating a model of the reward given state and action and (ii) importance sampling. While recent work has made significant advances adaptively combining these two components, less attention has been paid to improving the quality of the importance weights themselves. In this work we present balancing off-policy evaluation (BOP-e), an importance sampling procedure that directly optimizes for balance and can be plugged into any OPE estimator that uses importance sampling. BOP-e directly estimates the importance sampling ratio via a classifier which attempts to distinguish state-action pairs from an observed versus a proposed policy. BOP-e can be applied to continuous, mixed, and multi-valued action spaces without modification and is easily scalable to many observations. Further, we show that minimization of regret in the constructed binary classification problem translates directly into minimizing regret in the off-policy evaluation task. Finally, we provide experimental evidence that BOP-e outperforms inverse propensity weighting-based approaches for offline evaluation of policies in the contextual bandit setting under both discrete and continuous action spaces.